












部署模式
如何部署服务是微服务中的一个重要问题,微服务的部署方式非常灵活,有以下的不同选项可供选择 (参考 open-open.com/lib/view/)
- 多服务共享主机/虚机
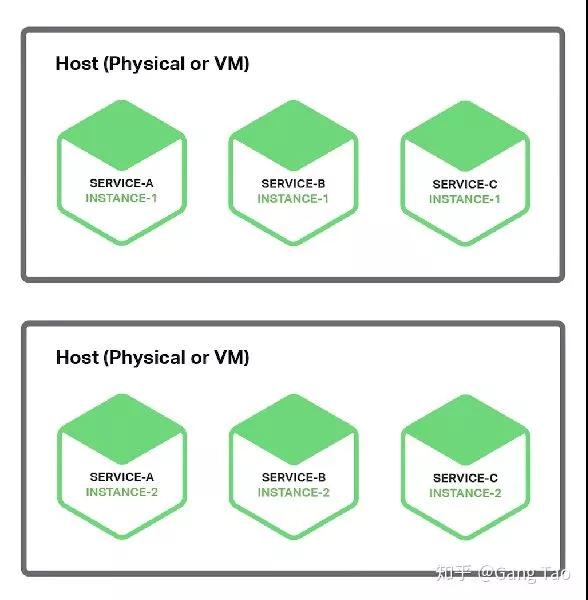
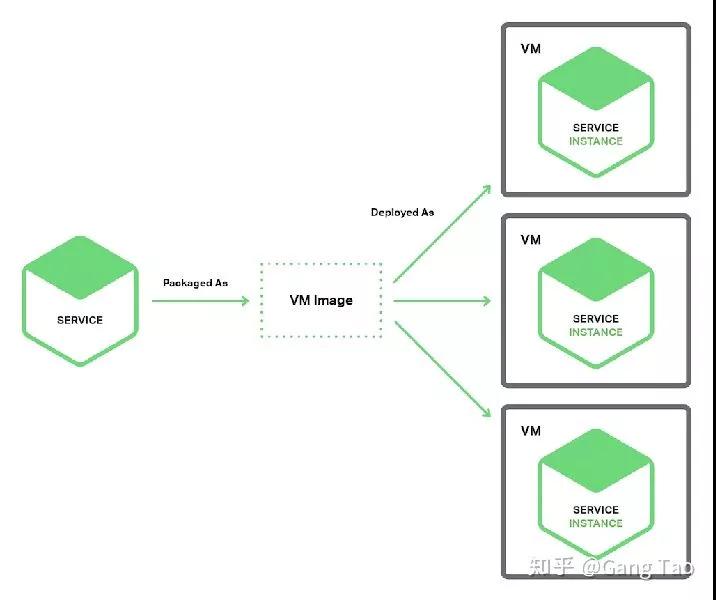
- 单服务部署单一主机/虚机
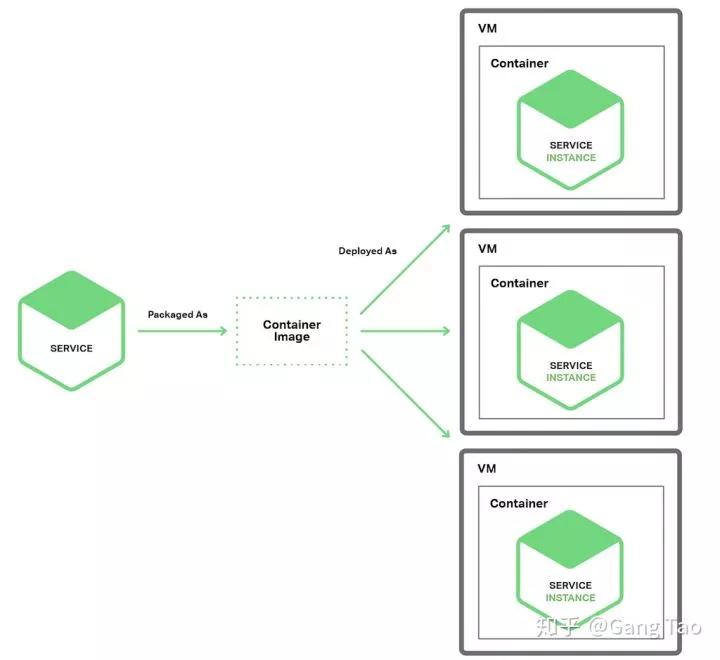
- 单服务部署单一容器(Docker)
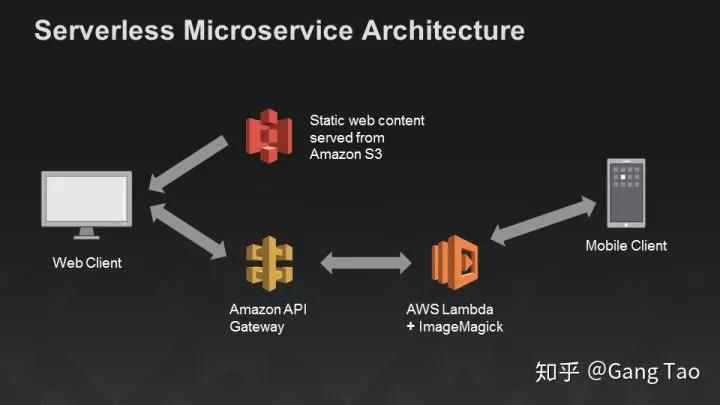
- 无服务部署(serverless),例如AWS Lambda
- 使用服务部署平台 (Kubernetes,Docker Swarm,Mesos, AWS ECS)
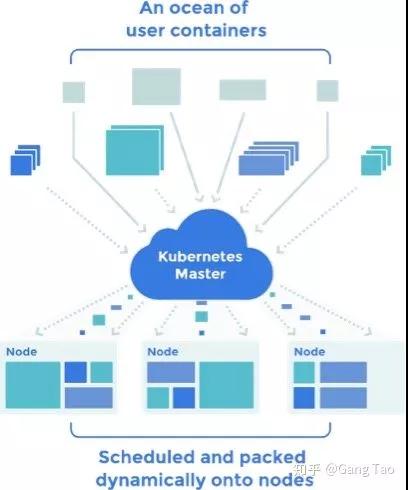
不同的部署方式各有优缺点,重点推荐使用容器编排系统的服务部署平台,能够提供各种灵活的部署方案。
横向关注点
微服务的开发过程中常常会花很多时间来处理一些各个服务都会遇到的问题,例如
- 如何管理配置信息,例如用户名和口令,服务器的网络地址,等等
- 日志管理
- 健康检查
- 业务度量数据(Metrics)的收集和分析
- 分布服务的追踪
- 这里推荐使用一个稳定的微服务框架来处理这些问题,例如基于Java的spring boot,基于Golang的Micro等
API网关
API网关类似服务代理,所有的客户端都通过API网关提供的统一服务API来消费服务内容。
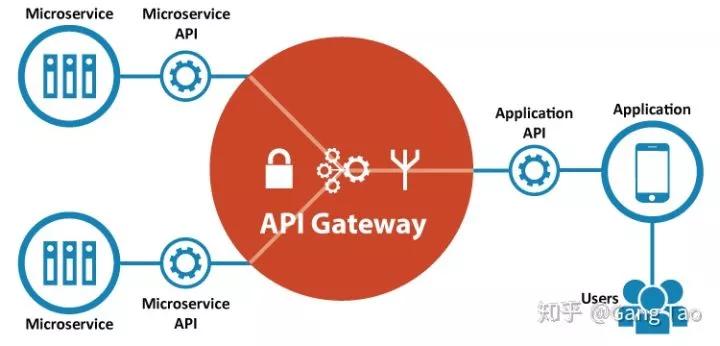
下面是几个开源的API Gateway
- Kong ( github.com/Mashape/kong )
- APIAxle ( http://apiaxle.com/ )
- Tyk ( tyk.io/ )
- apiGrove ( http://apigrove.net/ )
- WSO2 API Manager ( http://wso2.com/products/api-manager/ )
服务发现
服务发现是指API网关或者客户端如何获得微服务的地址,主要有以下几种发现方式:
- 客户端发现
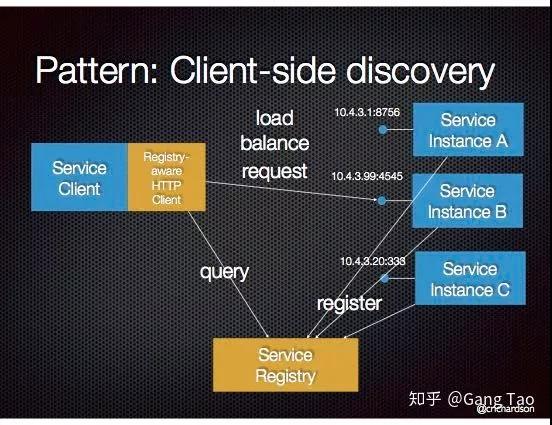
- 服务器端发现

这种方案中的Router可以并入API网关,客户端直接和网关通信。
两种方案需要用到服务注册,,区别在于是否把服务注册直接暴露给客户端使用。常见的提供服务发现的注册开源解决方案有:
- Apache Zookeeper
- Consul
- Etcd
断路器
当微服务系统中的某个服务出现问题的时候,或者网络出现时延的时候,调用客户端会被阻塞,导致大量的调用占用大量的资源。这时候需要引入类似断路器效果的代理,当出现不健康的服务的时候,断路器会返回出错,阻止更多的客户端掉用,直至服务的健康状态恢复。
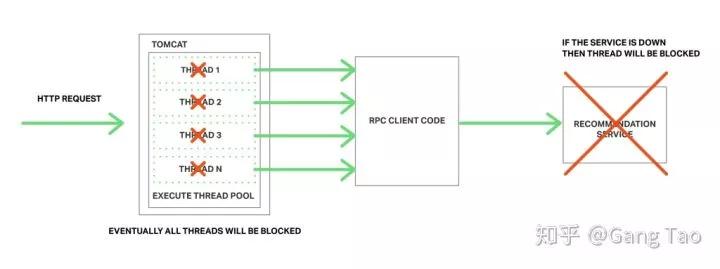
netflix的hystrix提供了类似的服务 github.com/Netflix/Hyst
数据管理
在设计微服务的时候要考虑是否每一个服务拥有自己的数据库或者是共享数据库
- 每个服务拥有自己的数据库
- 共享数据库
这两种方式各有优缺点:
- 独立数据库使得各个服务完全解耦合,并且可以根据需要选用不同种类的数据库,但是没有办法或者很难在服务之间共享数据
- 共享数据库能简化维护和技术栈,但是数据库成为所有服务的依赖,系统更多的耦合,带来了不灵活,没有办法根据业务需要选择不同的数据库种类。
微服务中的反模式
相对于《设计模式》,《反模式》一书可能知道的相对少一点,其实同样的道理,反模式归纳总结了一些常见的容易犯的设计问题,那么,微服务中有哪些反模式呢?
聚合混乱
软件设计的一个主要思想“高内聚,低耦合”同样适用于微服务,随着系统的发展,应该避免某一个服务变的一场庞大,或者服务之间不必要的过多依赖。
不认真对待自动化
持续集成和交付和微服务相辅相成,自动化的测试,集成,交付和部署是微服务成败的关键。一个自动化程度不高的微服务是很难成功的。
层级的软件架构
在设计微服务的时候,应该尽可能避免分层的架构,服务之间更多应该是流式调用。例如为所有的服务提供一个数据接入层的数据服务,似乎不是一个好的选择,因为这样的化就使得所有的服务依赖该数据服务。微服务更多应该基于业务来设计,每个服务应该自包含。
以下的架构虽然是一种层级架构,但也是可以采用的,条件是不同的服务不应该共享数据。
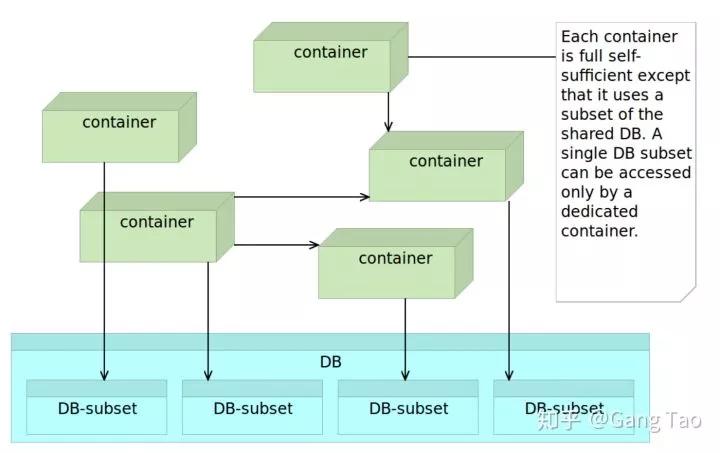
依赖客户签核
当服务有不同的客户渠道来消费的时候,不应该依赖客户的签核,自动化的测试应该覆盖所有的使用场景。
手工化的配置管理
应该尽量避免手工化地配置管理,实现自动化
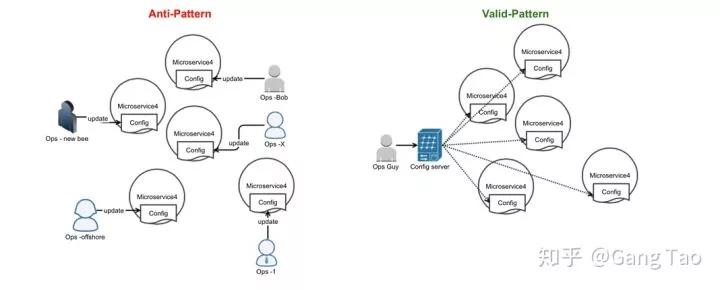
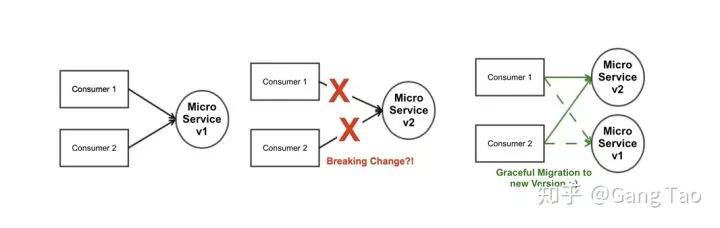
避免版本管理
在微服务中,如果你的系统只有一个版本,那么这肯定是有问题的。前向兼容是一个需要支持的目标,也就是说不同的客户端版本不应该收到服务升级的影响。这也就意味这API一旦发布,就不应该有不兼容的修改。
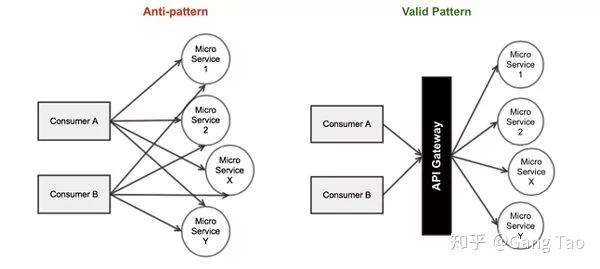
为每一个服务创建网关
这个就不用多说了,看着就很傻
参考
- microservices.io/patter
- infoq.com/articles/seve




























