













面临的场景
金融风控
- 用户画像库
- 爬虫抓取信息
- 反欺诈系统
- 订单数据
个性化推荐
- 用户行为分析
- 用户画像
- 推荐引擎
- 海量实时数据处理
社交Feeds
- 海量帖子、文章
- 聊天、评论
- 海量实时数据处理
时空时序
- 监控数据
- 轨迹、设备数据
- 地理信息
- 区域分布统计
- 区域查询
大数据
- 维表和结果表
- 离线分析
- 海量实时数据存储
新的挑战
Apache HBase(在线查询) 的特点有:
- 松散表结构(Schema free)
- 随机查询、范围查询
- 原生海量数据分布式存储
- 高吞吐、低延迟
- 在线分布式数据库
- 多版本、增量导入、多维删除
面临的新的挑战:
- 流式及批量入库
- 复杂分析
- 机器学习、图计算
- 生态及联邦分析
选择Spark的原因
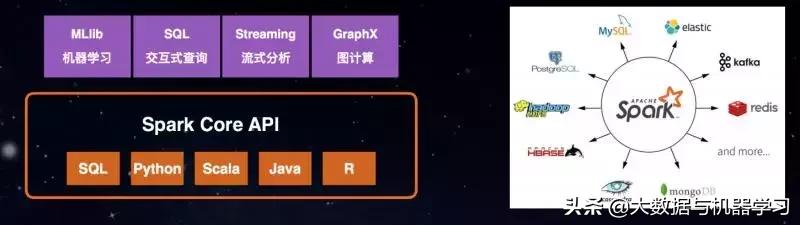
- 快:通过query的执行优化、Cache等技术,Spark能够对任意数据量的数据进行快速分析。逻辑回归场景比Hadoop快100倍
- 一站式:Spark同时支持复杂SQL分析、流式处理、机器学习、图计算等模型,且一个应用中可组合上面多个模型解决场景问题
- 开发者友好:同时友好支持SQL、Python、Scala、Java、R多种开发者语言
- 优秀的生态:支持与Ka=a、HBase、Cassandra、MongoDB、Redis、MYSQL、SQL Server等配合使用
平台机构及案例
一站式数据处理平台架构
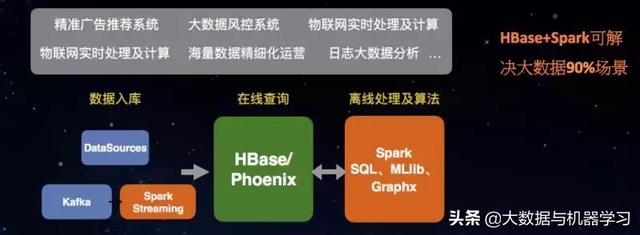
- 数据入库:借助于Spark Streaming,能够做流式ETL以及增量入库到HBase/Phoenix。
- 在线查询:HBase/Phoenix能够对外提供高并发的在线查询
- 离线分析及算法:如果HBase/Phoenix的数据需要做复杂分析及算法分析,可以使用Spark的SQL、机器学习、图计算等
典型业务场景:爬虫+搜索引擎
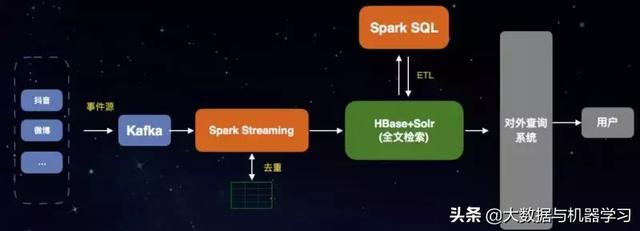
- 性能:流吞吐 20万条/秒
- 查询能力:HBase自动同步到solr对外提供全文检索的查询
- 一站式解决方案:Spark服务原生支持通过SQL读取HBase 数据能力进行ETL,Spark + HBase +Solr一站式数据处理平台
典型业务场景:大数据风控系统
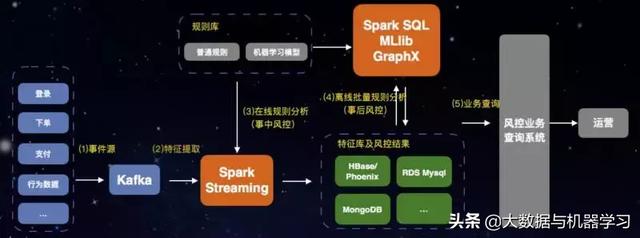
- Spark同时支持事中及事后风控
- Spark友好对接HBase、RDS、MongoDB多种在线库
典型业务场景:构建数据仓库(推荐、风控)
- 毫秒级识别拦截代充订单,并发十万量级
- Spark优秀的计算能力:Spark基于列式存储Parquet的分析在数据量大的情况下比Greenplum集群有10倍的性能提升
- 一站式解决方案:Spark服务原生支持通过SQL读取
- HBase SQL(Phoenix)数据能力
- 聚焦业务:全托管的Spark服务保证了作业运行的稳定性,释放运维人力,同时数据工作台降低了spark作业管理成本
原理及实践
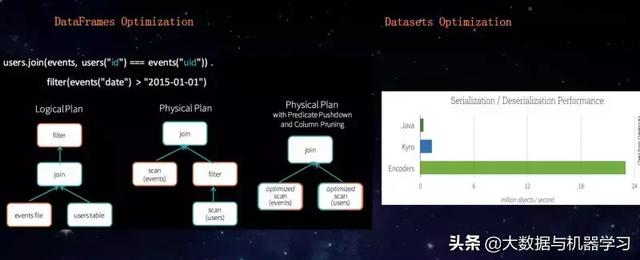
Spark API的发展经历了RDD、DataFrame、DataSet
Spark Streaming采用的是Micro-Batch方式处理实时数据。
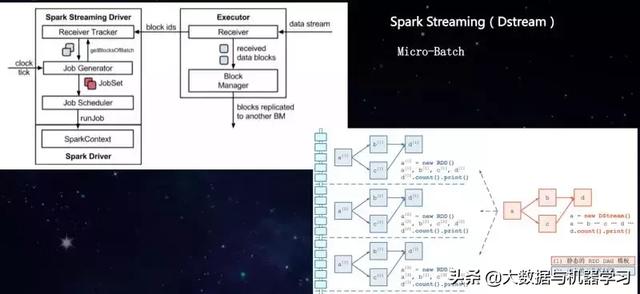
作业堆积、延迟高、并发不够?
- 每批次的并发:调大kafka的订阅的分区、spark.streaming.blockInterval
- 代码热点优化:查看堆栈、broadcast、代码优化
Spark流式处理入库HBase
Micro-Batch Processing:100ms延迟ConKnuous Processing:1ms延迟
Spark HBase Connector的一些优化
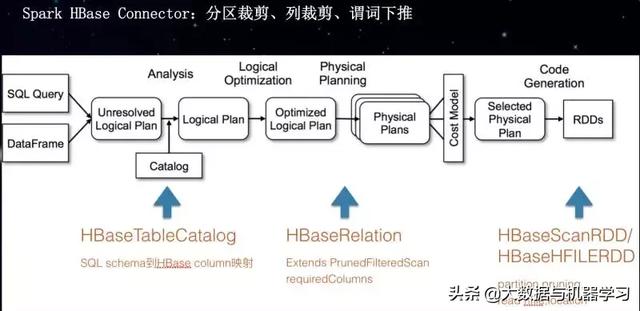
代码托管在:https://github.com/aliyun/aliyun-apsaradb-hbase-demo (包含Spark操作Hbase和Phoenix)
本文整理自来自阿里巴巴的沐远的分享,由大数据技术与架构进行整理和分享。场景需求和挑战






















