我们使用缓存的主要目是提升查询速度和保护数据库等稀缺资源不被占满。而缓存最常见的问题是缓存穿透、击穿和雪崩,在高并发下这三种情况都会有大量请求落到数据库,导致数据库资源占满,引起数据库故障。今天我主要分享一下layering-cache缓存框架在这个三个问题上的实践方案。
概念
缓存穿透
在高并发下,查询一个不存在的值时,缓存不会被命中,导致大量请求直接落到数据库上,如活动系统里面查询一个不存在的活动。
缓存击穿
在高并发下,对一个特定的值进行查询,但是这个时候缓存正好过期了,缓存没有命中,导致大量请求直接落到数据库上,如活动系统里面查询活动信息,但是在活动进行过程中活动缓存突然过期了。
缓存雪崩
在高并发下,大量的缓存key在同一时间失效,导致大量的请求落到数据库上,如活动系统里面同时进行着非常多的活动,但是在某个时间点所有的活动缓存全部过期。
常见解决方案
- 直接缓存NULL值
- 限流
- 缓存预热
- 分级缓存
- 缓存永远不过期
layering-cache实践
在layering-cache里面结合了缓存NULL值,缓存预热,限流、分级缓存和间接的实现"永不过期"等几种方案来应对缓存穿透、击穿和雪崩问题。
直接缓存NULL值
应对缓存穿透最有效的方法是直接缓存NULL值,但是缓存NULL的时间不能太长,否则NULL数据长时间得不到更新,也不能太短,否则达不到防止缓存击穿的效果。
我在layering-cache对NULL值进行了特殊处理,一级缓存不允许存NULL值,二级缓存可以配置缓存是否允许存NULL值,如果配置可以允许存NULL值,框架还支持配置缓存非空值和NULL值之间的过期时间倍率,这使得我们能精准的控制每一个缓存的NULL值过期时间,控制粒度非常细。当NULL缓存过期我还可以使用限流,缓存预热等手段来防止穿透。
示例:
@Cacheable(value = "people", key = "#person.id", depict = "用户信息缓存",
firstCache = @FirstCache(expireTime = 10, timeUnit = TimeUnit.MINUTES),
secondaryCache = @SecondaryCache(expireTime = 10, timeUnit = TimeUnit.HOURS,
isAllowNullValue = true, magnification = 10))
public Person findOne(Person person) {
Person p = personRepository.findOne(Example.of(person));
logger.info("为id、key为:" + p.getId() + "数据做了缓存");
return p;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
在这个例子里面isAllowNullValue = true表示允许换存NULL值,magnification = 10表示NULL值和非NULL值之间的时间倍率是10,也就是说当缓存值为NULL是,二级缓存的有效时间将是1个小时。
限流
应对缓存穿透的常用方法之一是限流,常见的限流算法有滑动窗口,令牌桶算法和漏桶算法,或者直接使用队列、加锁等,在layering-cache里面我主要使用分布式锁来做限流。
layering-cache数据读取流程:
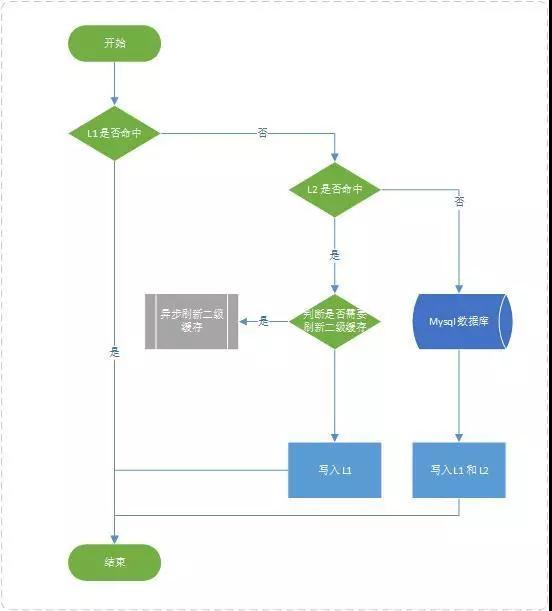
数据读取流程.jpg
下面是读取数据的核心代码:
private <T> T executeCacheMethod(RedisCacheKey redisCacheKey, Callable<T> valueLoader) {
Lock redisLock = new Lock(redisTemplate, redisCacheKey.getKey() + "_sync_lock");
// 同一个线程循环20次查询缓存,每次等待20毫秒,如果还是没有数据直接去执行被缓存的方法
for (int i = 0; i < RETRY_COUNT; i++) {
try {
// 先取缓存,如果有直接返回,没有再去做拿锁操作
Object result = redisTemplate.opsForValue().get(redisCacheKey.getKey());
if (result != null) {
logger.debug("redis缓存 key= {} 获取到锁后查询查询缓存命中,不需要执行被缓存的方法", redisCacheKey.getKey());
return (T) fromStoreValue(result);
}
// 获取分布式锁去后台查询数据
if (redisLock.lock()) {
T t = loaderAndPutValue(redisCacheKey, valueLoader, true);
logger.debug("redis缓存 key= {} 从数据库获取数据完毕,唤醒所有等待线程", redisCacheKey.getKey());
// 唤醒线程
container.signalAll(redisCacheKey.getKey());
return t;
}
// 线程等待
logger.debug("redis缓存 key= {} 从数据库获取数据未获取到锁,进入等待状态,等待{}毫秒", redisCacheKey.getKey(), WAIT_TIME);
container.await(redisCacheKey.getKey(), WAIT_TIME);
} catch (Exception e) {
container.signalAll(redisCacheKey.getKey());
throw new LoaderCacheValueException(redisCacheKey.getKey(), e);
} finally {
redisLock.unlock();
}
}
logger.debug("redis缓存 key={} 等待{}次,共{}毫秒,任未获取到缓存,直接去执行被缓存的方法", redisCacheKey.getKey(), RETRY_COUNT, RETRY_COUNT * WAIT_TIME, WAIT_TIME);
return loaderAndPutValue(redisCacheKey, valueLoader, true);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
当需要加载缓存的时候,需要获取到锁才有权限到后台去加载缓存数据,否则就会等待(同一个线程循环20次查询缓存,每次等待20毫秒,如果还是没有数据直接去执行被缓存的方法,这个主要是为了防止获取到锁并且去加载缓存的线程出问题,没有返回而导致死锁)。当获取到锁的线程执行完成会将获取到的数据放到缓存中,并且唤醒所有等待线程。
这里需要注意一下让线程等待一定不能用Thread.sleep(),我在使用Spring Redis Cache的时候,我发现当并发达到300左右,缓存一旦过期就会引起死锁,原因是使用的是sleep方法来让没有获取到锁的线程等待,当等待的线程很多的时候会产生大量上下文切换,导致获取到锁的线程一直获取不到cpu的执行权,导致死锁。在layering-cache里面,我们使用的是LockSupport.parkNanos方法,它会释放cpu资源, 因为我们使用的是redis分布式锁,所以也不能使用wait-notify机制。
缓存预热
有效应对缓存的击穿和雪崩的方式之一是缓存预加载。
@Cacheable(value = "people", key = "#person.id", depict = "用户信息缓存",
firstCache = @FirstCache(expireTime = 10, timeUnit = TimeUnit.MINUTES),
secondaryCache = @SecondaryCache(expireTime = 10, preloadTime = 2,timeUnit = TimeUnit.HOURS,))
public Person findOne(Person person) {
Person p = personRepository.findOne(Example.of(person));
logger.info("为id、key为:" + p.getId() + "数据做了缓存");
return p;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
在 layering-cache里面二级缓存会配置两个时间,expireTime是缓存的过期时间,preloadTime 是缓存的刷新时间(预加载时间)。每次二级缓存被命中都会去检查缓存的过去时间是否小于刷新时间,如果小于就会开启一个异步线程预先去更新缓存,并将新的值放到缓存中,有效的保证了热点数据**"永不过期"**。这里预先更新缓存也是需要加锁的,并不是所有的线程都会落到库上刷新缓存,如果没有获取到锁就直接结束当前线程。
/**
* 刷新缓存数据
*/
private <T> void refreshCache(RedisCacheKey redisCacheKey, Callable<T> valueLoader, Object result) {
Long ttl = redisTemplate.getExpire(redisCacheKey.getKey());
Long preload = preloadTime;
// 允许缓存NULL值,则自动刷新时间也要除以倍数
boolean flag = isAllowNullValues() && (result instanceof NullValue || result == null);
if (flag) {
preload = preload / getMagnification();
}
if (null != ttl && ttl > 0 && TimeUnit.SECONDS.toMillis(ttl) <= preload) {
// 判断是否需要强制刷新在开启刷新线程
if (!getForceRefresh()) {
logger.debug("redis缓存 key={} 软刷新缓存模式", redisCacheKey.getKey());
softRefresh(redisCacheKey);
} else {
logger.debug("redis缓存 key={} 强刷新缓存模式", redisCacheKey.getKey());
forceRefresh(redisCacheKey, valueLoader);
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
/**
* 硬刷新(执行被缓存的方法)
*
* @param redisCacheKey {@link RedisCacheKey}
* @param valueLoader 数据加载器
*/
private <T> void forceRefresh(RedisCacheKey redisCacheKey, Callable<T> valueLoader) {
// 尽量少的去开启线程,因为线程池是有限的
ThreadTaskUtils.run(() -> {
// 加一个分布式锁,只放一个请求去刷新缓存
Lock redisLock = new Lock(redisTemplate, redisCacheKey.getKey() + "_lock");
try {
if (redisLock.lock()) {
// 获取锁之后再判断一下过期时间,看是否需要加载数据
Long ttl = redisTemplate.getExpire(redisCacheKey.getKey());
if (null != ttl && ttl > 0 && TimeUnit.SECONDS.toMillis(ttl) <= preloadTime) {
// 加载数据并放到缓存
loaderAndPutValue(redisCacheKey, valueLoader, false);
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
} finally {
redisLock.unlock();
}
});
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
在缓存总量和并发量都很大的时候,这个时候缓存如果同时失效,缓存预热将是一个非常慢长的过程,就比如说服务重启或新上线一个新的缓存。这个时候我们可以采用切流的方式,让缓存慢慢预热,如开始切10%流量,观察没有异常后,再切30%流量,观察没有异常后,再切60%流量,然后全量。这种方式虽然有点繁琐,但是一旦遇到异常我们可以快速的切回流量,让风险可控。
总结
总体来说layering-cache在缓存穿透、击穿和雪崩上是以预防为主,补救为辅。而在应对缓存的这些问题上其实也没有一个完全完美的方案,只有最适合自己业务系统的方案。目前如果直接使用layering-cache缓存框架已经基本能应对大部分的缓存问题了。
源码
https://github.com/wyh-chenfeng/layering-cache
layering-cache
为监控而生的多级缓存框架 layering-cache这是我开源的一个多级缓存框架的实现,如果有兴趣可以看一下。
作者:xiaolyuh
原文地址:https://my.oschina.net/u/3748347/blog/2995017