












Elasticsearch用于构建高可用和可扩展的系统。扩展的方式可以是购买更好的服务器(纵向扩展(vertical scale or scaling up))或者购买更多的服务器(横向扩展(horizontal scale or scaling out))。
Elasticsearch虽然能从更强大的硬件中获得更好的性能,但是纵向扩展有它的局限性。真正的扩展应该是横向的,它通过增加节点来均摊负载和增加可靠性。
对于大多数数据库而言,横向扩展意味着你的程序将做非常大的改动才能利用这些新添加的设备。对比来说,Elasticsearch天生就是分布式的:它知道如何管理节点来提供高扩展和高可用。这意味着你的程序不需要关心这些。
ES 如何实现分布式
添加索引
es 中存储数据的基本单位是索引,我们为了将数据添加到ES中,就需要添加索引(index)
这里需要说一下ES中索引与分片(shard)的关系:一个分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分;所有的文档均存在分片中,而直接与应用程序进行交互的再而三索引。
下面我们以酒店搜索为例,添加所有酒店索引hotel_idx
- PUT /hotel_idx
- {
- "settings" : {
- "number_of_shards" : 3,
- "number_of_replicas" : 1
- }
- }
我们启动三个ES节点,当前hotel_idx 分配3个主分片(primary shard),每个主分片1个副本分片(replica shard)。
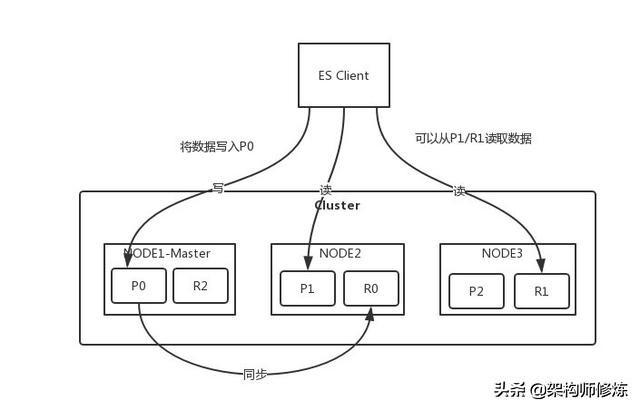
1,ES Client 会挑一个Node,上面挑选了NODE1,则成为协调节点,进行写入数据,此时ES怎么才能知道将一个文档(一条酒店数据)路由到哪个分片中呢,实际上,他是根据这个公式:
- shard=hash(routing)%number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值,这里可以是酒店的hotel_id。routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到 余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
2,写完P0后就会同步到他的副本R0中去,同步成功则会返回给协调节点Node1,最后返回Client
3,ES client读取数据均可以读取主副分片
如何保证高可用
- 如上NODE1-master节点宕机了,ES则会进行重新选举(如果需要后面考虑分享一下分布式选举专题),假如选了NODE2为master。
- 如果是非master宕机(node2),master节点node1则会将Node3的R1副本转为主分片P1接收写操作,如果NODE2恢复了,则之前的P1转为R1副本。
如何可扩展
ES在创建索引时就需要指定主分片的数量,所以主分片指定了是不能再扩充的,当存储容量超过了目前的ES节点,一般有些生产做法是,重新再建立了新索引比目前多一点shard,然后导入数据,但这种也是有些缺点的:这样做将消耗的时间是我们无法提供的;
我们一般的做法是事先进行预分配,通过事先规划,我们可以使用 预分配 的方式来完全避免这个问题。
其中,副本分片是可以动态扩展的,在读取很大的场景下,适当的扩充副本会增加吞吐量。
- PUT /hotel_idx/_settings
- {
- "number_of_replicas" : 2
- }
如何预估分片容量
其实这个是不好解释的,因为实在有太多相关的因素了:你使用的硬件、文档的大小和复杂度、文档的索引分析方式、运行的查询类型、执行的聚合以及你的数据模型等等。
生产中经验建议:
1,基于你准备用于生产环境的硬件创建一个拥有单个节点的集群。
2,创建一个和你准备用于生产环境相同配置和分析器的索引,但让它只有一个主分片无副本分片。索引实际的文档(或者尽可能接近实际)。
3,运行实际的查询和聚合(或者尽可能接近实际)。
基本来说,你需要复制真实环境的使用方式并将它们全部压缩到单个分片上直到它“挂掉。” 实际上 挂掉 的定义也取决于你:一些用户需要所有响应在 50 毫秒内返回;另一些则乐于等上 5 秒钟。
所以,一旦你定义好了单个分片的容量,很容易就可以推算出整个索引的分片数。用你需要索引的数据总数加上一部分预期的增长,除以单个分片的容量,结果就是你需要的主分片个数。



















