在利用 Python 与 R 的数据科学堆栈工作了几个礼拜之后,我开始问自己:有没有可能存在一种通用的中间表示形式(类似于 CUDA),能够在多种语言之间同时起效?现在我必须得在不同语言中重新实现并优化已经存在的方法,难道就不能更高效一点?除此之外,我希望通过通用的运行对程序进行整体优化,而不是像现在这样只能针对函数进行优化。经过几天的研究和测试,我发现了 Weld。令我意外的是,Weld 的缔造者之一正是 Matei Zaharia,也就是 Spark 的发明者。
正因为如此,我联系并采访了 Weld 项目的主要贡献者 Shoumik Palkar。Shoumik 目前是斯坦福大学计算机科学系的博士生,在 Matei Zaharia 的推荐下加入了 Weld 项目。
Weld 还远没有达到生产就绪级别,但其发展愿景却是一片光明。如果大家对数据科学的未来以及 Rust 抱有兴趣,相信这次访谈会给你带来不少启示。
开发 Weld 项目的动机是什么,它又能够解决哪些问题?
项目的开发动机,在于为依赖现有高级 API(例如 NumPy 与 Pandas)的应用程序提供裸机级别的性能表现。其解决的主要问题,是实现跨函数与跨库层面的优化,而这正是目前其他库所无法实现的。具体来讲,当下有不少常用库以各个函数为基础提供算法的最新实现(例如以 C 语言在 Pandas 中实现的快速连接算法,或者以 NumPy 语言实现的快速矩阵乘法),但市面上却还不存在能够跨越这些函数实现优化的可用工具(例如在执行矩阵乘法后进行聚合时,防止不必要的内存扫描)。Weld 希望提供一个可通用的运行时,使各个库能够在通用 IR 当中进行计算表达;接下来,开发人员还可以利用编译器优化程序对 IR 进行优化,而后通过循环融合、矢量化等优化手段将 JIT 与并行本机代码加以对接。Weld 的 IR 具备本机并行特性,因此开发人员可以随时对其中表示的程序进行常规并行化处理。
我们还建立了一个名为拆分注释(split annotations)的新项目,该项目将与 Weld 相集成,旨在降低对现有库进行优化的实施门槛。
对 Numpy、Pandas 以及 Scikit 进行优化困难吗?速度方面能有多大提升?
Weld 跨越各个函数对这些库进行优化,而对库的整体优化也能让单一函数的调用速度更快。实际上,不少此类数据库都已经立足函数层面进行了高度优化,只是由于其没有充分利用并行性或者内存结构,所以性能表现仍然低于现代硬件的极限水平。举例来说,目前已经有不少 Numpy ndarray 函数可以在 C 语言中实现,但调用每一项函数都需要对每一条输入进行完整扫描。如果这些数组不适用于 CPU 缓存,那么大多数执行时间就都被耗费在了从主内存中加载数据上,计算的执行反而成了次要耗时因素。Weld 能够查看各个函数调用并执行优化,例如循环融合,从而将数据保留在 CPU 缓存或者寄存器当中。凭借着更好的扩展能力,这些类型的优化能够在多核心系统上将性能提升一个数量级甚至更高。
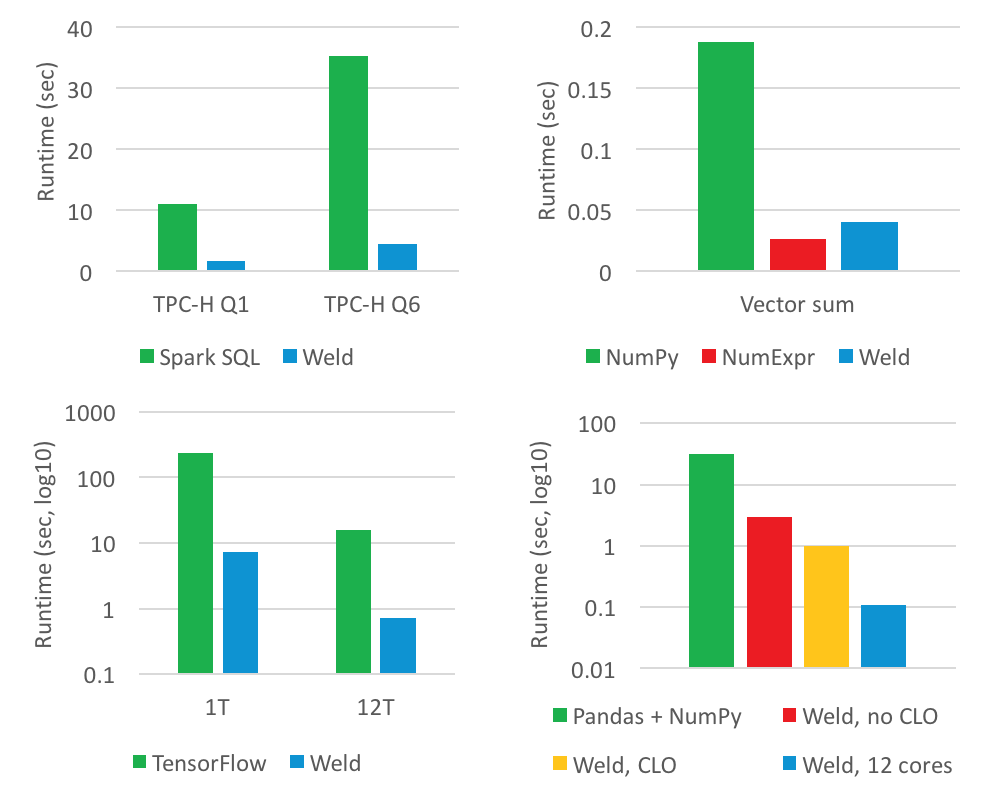
与 Weld 原型方案进行集成之后,Spark(左上)、NumPy(右上)以及 TensorFlow(左下)的性能相较于原始框架提高了 30 倍,且无需对用户的应用程序代码做出任何调整。此外,Pandas 与 NumPy 之间的跨库优化(右下)则可将性能提升达两个数量级。
Baloo 是什么?
Baloo 是一个库,负责利用 Weld 实现 Pandas API 中的一个子集。Baloo 由阿姆斯特丹 CWI 研究所硕士生 Radu Jica 开发完成,其目标是在 Pandas 当中完成之前提到的各项优化,从而提高其单线程性能、减少内存占用量并引入并行性。
Weld/Baloo 是否支持利用核外计算(例如 Dask)处理不适合驻留在内存中的数据?
Weld 与 Baloo 目前都还不支持核外计算,但我们欢迎更多开源贡献者能够实现这一功能!
你们为什么选择利用 Rust 与 LLVM 来实现 Weld?Rust 一直是你们的第一选择吗?
我们之所以选择 Rust,是因为:
- Rust 的运行时很小(基本上只负责对数组进行边界检查),而且易于嵌入到其他语言(例如 Java 与 Python)当中。
- Rust 包含函数式编程范式,例如模式匹配,能够使代码编写(例如模式匹配编译器优化)更轻松。
- Rust 拥有强大的技术社区与高质量的工具包(在 Rust 中被称为“crates”),这使我们能够更容易地进行系统开发。
在另一方面,之所以选择 LLVM,是因为它拥有一套用途广泛且广受支持的开源编译器框架。我们能够直接生成 LLVM 以替代 C/C++,因此不必依赖于 C 编译器,从而缩短编译时间(过程中不需要解析 C/C++ 代码)。
Rust 并不是 Weld 采用的第一款实现语言;最初,我们选择的是 Scala,当时主要考虑到它拥有代数数据类型以及强大的模式匹配机制。这能够极大简化编译器核心部分优化器的编写过程。我们最初的优化器基于 Catalyst 设计,该设计器属于 Spark SQL 的可扩展优化器。但最终之所以放弃了 Scala,是因为我们发现很难将基于 JVM 的语言嵌入至其他运行时与语言当中。
如果 Weld 主要针对 CPU 与 GPU,那么它与 RAPIDS 这类专门面向 GPU 的 Python 数据科学实现库有什么不同?
Weld 项目与 RAPIDS 等其它系统的最大区别,在于它专注于跨越多种由 JIT 编译代码编写的内核实现应用程序优化,而非针对每一项独立函数提供优化效果。举例来说,Weld 的 GPU 后端能够为端到端应用程序 JIT 编译出经过优化的单一 CUDA 内核,而不像其它系统那样直接调用现有独立内核。此外,Weld 的 IR 意欲设计为硬件无关的,使其既能够面向 GPU,也可以面向 CPU 或者矢量加速器等其它定制化硬件。当然,Weld 也与其它系统有着不少交集,同时也受到了 RAPIDS 等其他同类项目的影响与启发。Bohrium(一种懒惰评估式的 NumPy)以及 Numba(一套可实现数字代码 JIT 编译的 Python 库)就与 Weld 有着相同的高级目标,而 Spark SQL 等优化器系统则直接影响着 Weld 的优化器设计思路。
除了数据科学库优化之外,Weld 项目是否还有其他应用?
Weld 的 IR 最令人兴奋的优势之一,在于其自身就支持数据并行性。这意味着在 Weld IR 当中表达的循环将始终可以安全实现并行化。这使 Weld 成为一种对新型硬件极具吸引力的 IR 解决方案。举例来说,NEC 公司的合作者们演示了如何利用 Weld 在自定义高内存带宽矢量加速器上运行 Python 工作负载——过程非常简单,只需要向现有 Weld IR 添加新的后端即可。此外,IR 还可用于在数据库内实现物理执行层,我们也在计划添加一系列新的功能,使开发人员能够将 Python 的部分子集编译为 Weld 代码。
这些库是否已经准备好应用于实际项目?如果还没有,你认为大概什么时候能够做好准备?
我们测试过的大部分库示例与基准都提取自真实工作负载。因此,如果用户愿意在自己的应用程序当中试用我们发布的当前版本,提供反馈甚至编写开源补丁,我们将不胜感激。换句话说,我们并不指望所有功能都能在现实应用程序当中立即使用。在接下来的几个月内,我们将发布一系列发行版,专门关注 Python 库的可用性与健壮性。我们的目标是努力提升这些库的质量,将其逐步引入现实项目当中,并在无法支持的情况下允许用户顺利回退至非 Weld 库版本。
正如我在回答第一个问题时所提到,简化整个流程的途径之一,在于拆分注释这个重要的相关项目。拆分注释是一套系统,允许用户对现有代码进行注释以定义其具体拆分、传递与并行化方法。根据我们的观察,该系统能够发现 Weld 有望带来最佳效果的优化方向(例如在函数调用之间将大量数据保留在 CPU 缓存中,而非扫描完整数据集);更重要的是,由于其重用现有库代码,而非依赖于编译器 IR,因此其集成难度要比 Weld 低得多。正因为如此,拆分注释能够使作为优化目标的库更易于维护与调试,从而提高健壮性水平。当无法支持 Weld 时,这些库也可退回至拆分注释,让我们根据用户提出的反馈以增量方式添加 Weld 支持,同时继续采取可行的优化操作。