可见性问题
可见性是指一个线程对共享变量进行了修改,其他线程能够立马看到该共享变量更新后的值,这视乎是一个合情合理的要求,但是在多线程的情况下,可能就要让你失望了,由于每个 CPU 都有自己的缓存,每个线程使用的可能是不同的 CPU ,这就会出现数据可见性的问题,先来看看下面这张图:
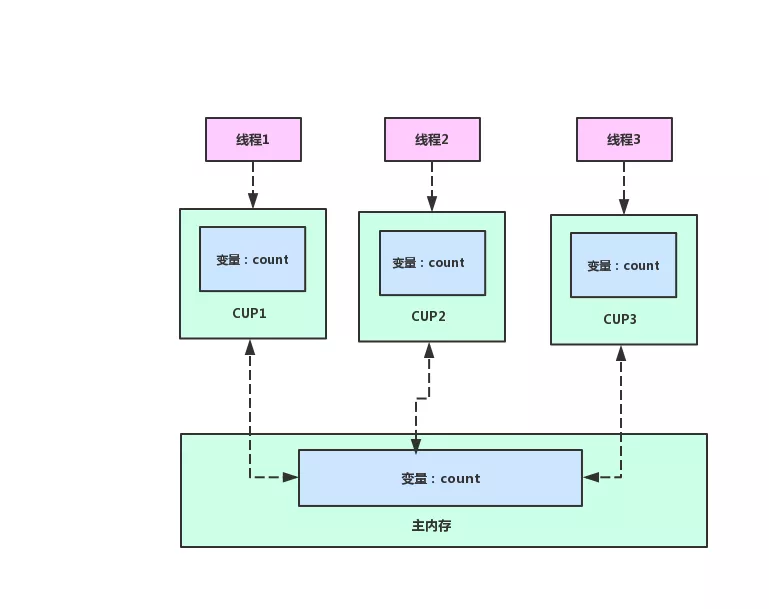
CUP 缓存与主内存的关系
对于一个共享变量 count ,每个 CPU 缓存中都有一个 count 副本,每个线程对共享变量 count 的操作的只能操作自己所在 CPU 缓存中的副本,不能直接操作主存或者其他 CPU 缓存中的副本,这也就产生了数据差异。由于可见性在多线程情况下造成程序问题的典型案例就是变量的累加,如下面这段程序:
- public class Demo {
- private int count = 0;
- // 每个线程为count + 10000
- public void add() {
- for (int i = 0; i < 10000; i++) {
- count += 1;
- }
- }
- public static void main(String[] args) throws InterruptedException {
- for (int i = 0; i < 10; i++) {
- Demo demo = new Demo();
- Thread t1 = new Thread(() -> {
- demo.add();
- });
- Thread t2 = new Thread(() -> {
- demo.add();
- });
- t1.start();
- t2.start();
- t1.join();
- t2.join();
- System.out.println(demo.count);
- }
- }
- }
我们使用了 2 个程序对 count 变量累加,每个线程累加 10000 次,按道理来说最终结果应该是 20000 次,但是你多次执行后,你会发现结果不一定是 20000 次,这就是由于共享变量的可见性造成的。
我们启动了两个线程 t1 和 t2,线程启动的时候会把当前主内存的 count 读入到自己的 CPU 缓存当中,这时候 count 的值可能是 0 也可能是 1 或者其他,我们就默认为 0,每个线程都会执行 count += 1 操作,这是一个并行操作,CPU1 和 CPU2 缓存中的 count 都是 1,然后他们分别将自己缓存中的count 写回到主内存中,这时候主内存中的 count 也是 1 ,并不是我们预计的 2,。这个原因就是数据可见性造成的。
原子性问题
原子性:即一个操作或者多个操作,要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。这个原子性针对的是 CPU 级别的,并不是我们 Java 代码里面的原子性,拿我们可见性 Demo 程序中的 count += 1;命令为例,这一条 Java 命令最终会被编译成如下三条 CPU 指令:
- 把变量 count 从内存加载到 CPU 的寄存器,假设 count = 1
- 在寄存器中执行 count +1 操作,count = 1+1 =2
- 将结果 +1 后的 count 写入内存
这是一个典型的 读-改-写 的操作,但是它不是原子性的,因为 多核CPU 之间有竞争关系,并不是某一个 CPU 一直执行,他们会不断的抢占执行权、释放执行权,所以上面三条指令就不一定是原子性的,下图是两个线程 count += 1命令的模拟流程:
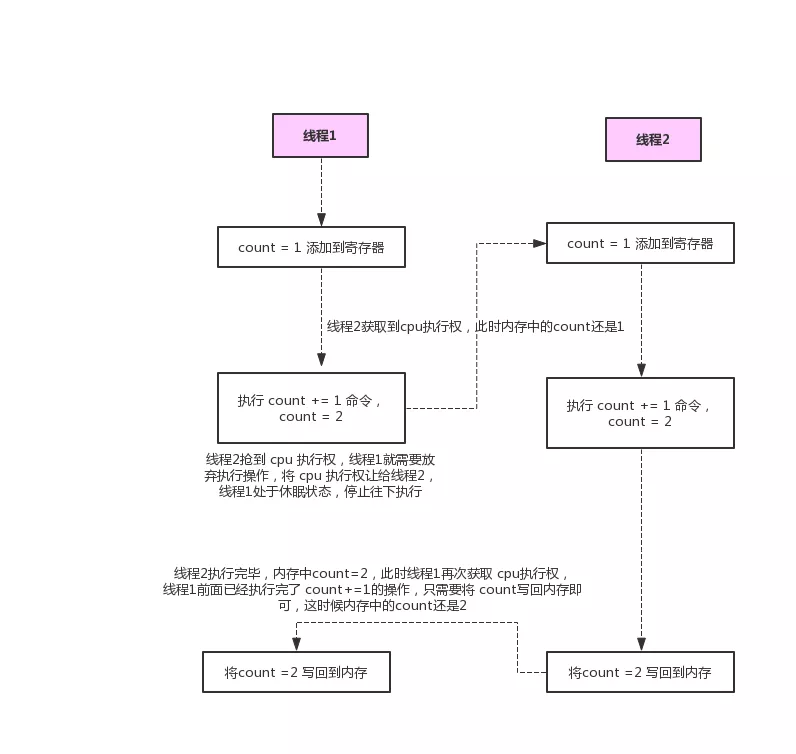
非原子性操作
线程1 所在的 CPU 执行完前两条指令后,执行权被 线程2 所在的 CPU 抢占了,这时候线程1 所在的 CPU 执行挂起等待再次获取执行权,线程2 所在的 CPU 获取到执行权之后,先从内存中读取 count,此时内存中的 count 还是 1,线程2 所在的 CPU 恰好执行完了这三条指令,线程2 执行完之后内存中的 count 就等于 2 了,这时候线程1 再次获取了执行权,这时候线程1 只剩下最后一条将 count 写回内存的命令,执行完之后,内存中的 count 的值还是 2 ,并不是我们预计的 3。
有序性问题
有序性:程序执行的顺序按照代码的先后顺序执行,比如下面这段代码
- 1 int i = 1;
- 2 int m = 11;
- 3 long x = 23L;
按照有序性的话就需要按照代码的顺序执行下来,但是执行结果不一定是按照这个顺序来的,因为 JVM 为了提高程序的运行效率,会对上面的代码按照 JVM 编译器认为较好的顺序执行,从而可能打乱代码的执行顺序,是它会保证程序最终执行结果和代码顺序执行的结果是一致的,这也就是我们所说的指令重排序
由于指令重排序造成程序出 Bug 的典型案例就是:未加 volatile 关键字的双重检测锁单例模式,如下代码:
- public class Singleton {
- static Singleton instance;
- public static Singleton getInstance(){
- // 第一次判断
- if (instance == null) {
- // 加锁,只有一个线程能够获取锁
- synchronized(Singleton.class) {
- // 第二次判断
- if (instance == null)
- // 构建对象,这里面就非常有学问了
- instance = new Singleton();
- }
- }
- return instance;
- }
- }
双重检测锁方案看上去非常完美,但是在实际运行时却会出 Bug,会出现对象逸出的问题,可能会得到一个未构建完的 Singleton 对象, 这个就是在构建 Singleton 对象时指令重排序的问题。我们先来看看构建对象理想型的操作指令:
- 指令1:分配一块内存 M;
- 指令2:在内存 M 上初始化 Singleton 对象;
- 指令3:然后 M 的地址赋值给 instance 变量。
但是实际在 JVM 编译器上可能不是这样,可能会被优化成如下指令:
- 指令1:分配一块内存 M;
- 指令2:将 M 的地址赋值给 instance 变量;
- 指令3:最后在内存 M 上初始化 Singleton 对象。
看上去一个小小的优化,也就是这么一个小小的优化就会使你的程序不安全,假设抢到锁的线程执行完指令2 之后,此时的 instance 已经不为空了,这时候来了线程C,线程C 看到的 instance 已经是不为空的了,就会直接返回 instance 对象,这时候的 instance 并未初始化成功,调用 instance 对象的方法或者成员变量时将有可能触发空指针异常。可能的执行流程图:
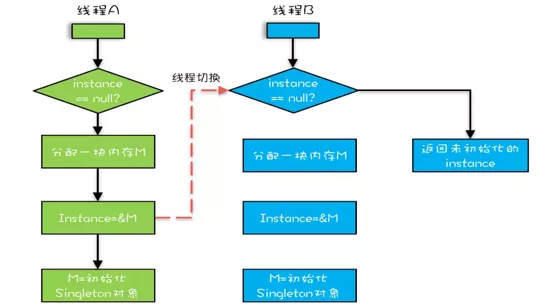
未加 volatile 关键字的双重检测锁单例模式
上面就是造成 Java 程序在多线程情况下出 Bug 的三种原因,关于这些问题 JDK 公司也给出了相应的解决办法,具体如下图所示,这些解决办法的更多细节,我们后面在细细道来。
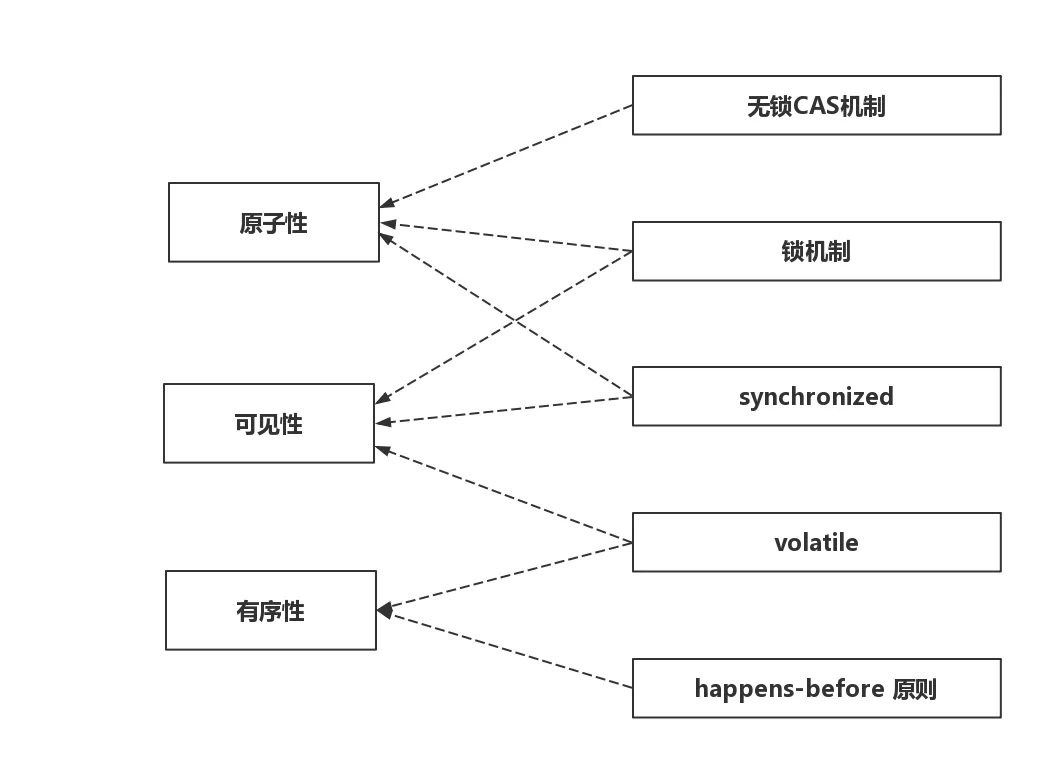
并发解决机制