












如果用一句话,描述运维团队的工作状态
那大概就是
“在机房里面机房外面,有一群男精灵,
他们熬夜很清醒,他们加班到天明。”
每一个稳定运行的系统,
都是因为有这样一群运维团队在背后
夜以继日、全年无休地
处理成千上万条系统预警
但是呢?就算是这么努力
一年365天中
总难免碰到那么一两次系统延迟
遭受来自四野八荒的疯狂轰炸
“为什么系统登不上去了?”
“为什么访问速度这么慢?”
“为什么页面加载不出来?”
.......
但是,还是要弱弱地跟用户爸爸们
说一句:系统宕机就和人会感冒一样
难以百分百完全避免
真的
先来看几条新闻
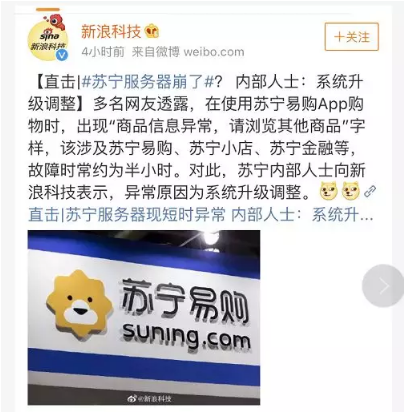
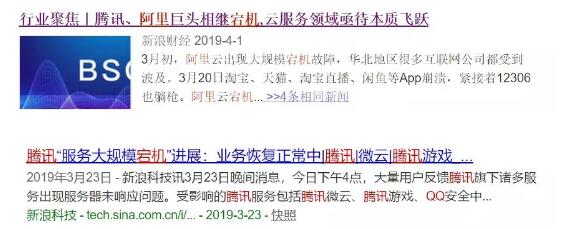
再来看一组数据
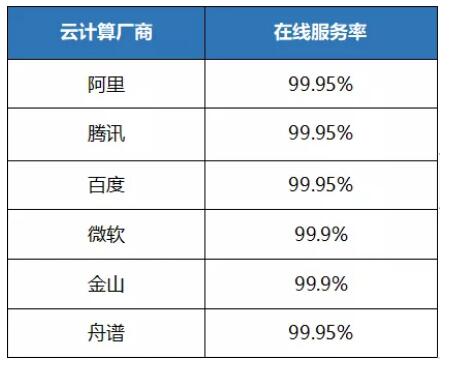
你会发现
想要系统永不宕机,简直是一个世纪难题
毕竟两个马爸爸都没有解决掉
但是,好的运维就像高明的医生一样
可以做到立刻恢复
好在我们舟谱(99.95%)也没有拖后腿
和BAT处在了一样的水平
让客户用上更好用更稳定的系统
是我们一直以来的追求,
为此,我们也付出不懈的努力
并取得了一定的成效
除了我们的99.95%在线服务率
在过去半年里,
我们的千人周问题数下降了4-5倍;
(每1k人使用一周可能碰到的缺陷数)
在线问题响应时间最快可达5分钟;
问题处理时间也有了大幅度提升,
95%的问题可在24小时内解决......
而这一切都离不开
我们的整个研发团队和运维保障体系
在背后的全力支撑
什么是运维保障体系
运维保障体系是为了提高软件的开发效率及稳定性,降低软件的运行成本。换句话说就是只帮忙,不添乱。
舟谱数据技术总监王宏祥指出:“实际上,基于这个目的,舟谱运维团队要做两件事。在研发层面,运维要为研发提供最优质的工具,提升产品迭代效率,让用户需求得以及时满足;在系统保障层面,为保障用户使用流畅,运维一方面要协助客户处理操作难题;另一方面,运维需要进行不间断的系统监控及优化,保证整套系统持续稳定。”
01
提升研发效率
让用户迅速获得最好用的产品
为保证产品/功能以最快的速度、最优的品质交付用户,运维要为研发提供最高效的工具。除了采用Gitlab+Jenkin+Nexus自建仓库自动化构建自动化集成平台等工具外,运维还提供了CI/CD自动化工具,通过自动化的校检,促进软件项目的持续集成与交付的速度,使得开发团队可以保持软件更新并将其迅速的投入实践中,大大提升了产品的迭代效率。
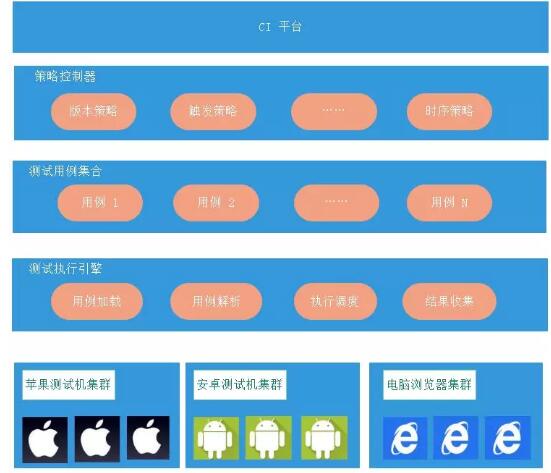
也正基于此,舟谱整套技术解决方案能够得以快速落成,并且产品保持每2周迭代一次的频率,每年满足客户需求近千条。在不断的更新和优化之下,产品功能更加完善,系统也更稳定更好用。
02
提升监控密度及问题响应速度
保证用户使用流畅
为了保证用户使用顺畅,舟谱运维团队还提供全天在线的技术支持。比如,在帮助客户处理误删数据上,我们做到了数据秒级回滚,数据在时间上可以精确到秒还原,无缝衔接;在处理删除销售单问题处理上,我们不仅可以精确还原单据,还可以追踪到具体操作时间,帮助客户找到管理上的漏洞。对于用户比较关注的数据安全问题,我们采用最先进的网络安全协议,机密传输及备份,并且为每一位客户单独分配一个数据库来隔离,全面保护用户的数据安全。
“运维并不是系统能跑起来,用户用起来就万事大吉,第一时间发现问题,能第一时间预警,能第一时间自动化解决才是运维最终目标。”
为此,舟谱引入了云监控+自建监控多层级告警的方式 ,能更细力度监控各项资源的可用性以及性能,可以实时感知到业务的任何变化,并且做出实时决策,早用户一步发现故障或性能瓶颈。不仅如此,我们还采用了备用服务器,当某一集群或地区出现故障,能够迅速响应,第一时间切换到另一地区,正常提供服务;与此同时,实行集群化部署策略,自动消除单点服务保障。除了自动化解决问题外,为了及时应对0.05%可能出现的故障,我们的7x24小时oncall排班策略还在持续发挥着作用,最快5分钟迅速响应,快速恢复,95%的问题保证在24小时内解决。
一直以来,舟谱行进在一条高速迭代的快车道。从2016年第一款产品舟谱云管家上线,到目前舟谱形成了整套技术解决方案,在这期间,我们不断收集新的诉求,运用新的技术,并以每月2-3次高速迭代的频率来逐步丰富和完善产品。在一段时间里,相较于低频迭代来说,高速迭代会增加系统的不稳定性,因为相对而言不动的东西最稳定;但从长远来看,软件更新换代,匹配不断变化的业态才是正确的姿态,所以舟谱一如既往坚持走在快车道上。
而我们运维保障体系也在不断地迭代,追求以更为轻便、高效的方式保证用户使用更流畅,即便在出现故障时,也能保障用户的使用不受影响或者受影响的程度可以降到最低。为客户能够持续获得更好的产品及服务,我们还在持续努力着。
【本文是51CTO专栏机构“舟谱数据”的原创文章,微信公众号“舟谱数据( id: zhoupudata)”】
















