













边缘计算对势头正盛的物联网的发展至关重要。近日,机器学习和数据科学咨询公司 Tryolabs 发布了一篇基准评测报告,测试比较了英伟达 Jetson Nano、谷歌 Coral 开发板(内置 Edge TPU)、英特尔神经计算棒这三款针对机器学习设计的边缘计算设备以及与不同的机器学习模型的组合。结果表明,无论是在推理时间还是准确度方面,英伟达的 Jetson Nano 都是当之无愧的赢家。另外他们也给出了在树莓派 3B 与英伟达 2080ti GPU 上的结果以供参考。
为什么需要边缘计算?
人类产生和收集的数据超过了以往任何时候。我们口袋中的设备就能产生巨量数据,比如照片、GPS 坐标、音频以及我们有意无意泄漏的各种个人信息。
此外,我们不仅会产生与个人相关的数据,也会从很多其它地方收集未知的数据,比如交通和出行控制系统、视频监控单元、卫星、智能汽车以及其它不胜枚举的智能设备。
数据增长的趋势已然形成,并还将继续呈指数级发展。在数据点方面,国际数据咨询公司(IDC)预计世界数据总量将从 2019 年的 33 ZB 增长至 2025 的 175 ZB,年增长率 61%。
尽管我们一直在处理数据,起先是在数据中心,然后是在云中,但这些解决方案不适用于数据量很大的高要求的任务。网络的性能和速度不断推进新的极限,随之而来的是对新型解决方案的需求。现在正是边缘计算和边缘设备时代的起点。
本报告是对五种新型边缘设备的基准评测。我们使用了不同的框架和模型来测试哪些组合表现最佳。我们将重点关注边缘机器学习的性能结果。
什么是边缘计算?
边缘计算包含把数据处理任务放至网络边缘的设备上,使其尽可能地靠近数据源。这种计算方式能以非常高的速度实现实时的数据处理,对很多具备机器学习能力的复杂物联网方案而言是必备能力。在此基础上,边缘计算能够缓解网络压力、降低能耗、提升安全性以及改善数据隐私。
使用这种新范式,针对边缘机器学习而优化的专用硬件和软件库组合到一起,能造就最前沿的应用和产品,进而实现大规模部署。
构建这类应用面临的最大难题源自音频、视频和图像处理任务。事实表明,深度学习技术在克服这些困难方面做得非常成功。
实现边缘深度学习
以自动驾驶汽车为例。自动驾驶汽车需要快速且持续不断地分析传入的数据,以便能在数毫秒内解析周围的世界并采取行动。这种时间限制使得我们不能依靠云来处理数据流,而是必须在本地完成处理。
但在本地处理有个缺点:硬件没有云中的超级计算机那么强大,而我们又不能在准确度和速度上妥协。
解决这个问题的方案要么使用更强更高效的硬件,要么就不要使用那么复杂的 深度神经网络 。为了得到最佳结果,必须在两者之间找到平衡。
因此,真正要解答的问题是:
为了最大化深度学习算法的准确度和速度,我们应该组合使用哪款边缘硬件和哪种类型的网络?
在我们寻找两者的最佳组合的旅程中,我们将比较多种当前最佳的边缘设备与不同的 深度神经网络 模型的组合。
新型边缘设备基准测试
我们探讨的是最具创新性的用例。这里我们将通过一次一张的图像分类任务来测量实时的推理吞吐量,从而得到近似的每秒处理帧数。
我们的具体做法是在 ImagenetV2 数据集的一个特定子集上评估在所有类别上的 top-1 推理准确度,并将结果与某些 卷积神经网络 模型进行比较。我们还尽量实验了不同的框架和优化过的版本。
硬件加速器
尽管过去几年人们在提升现有边缘硬件方面做了很多工作,但我们选择拿下面这几种新型设备做实验:
-
英伟达 Jetson Nano
-
谷歌 Coral 开发板
-
英特尔神经计算棒
-
树莓派(参考上限)
-
英伟达 2080ti GPU(参考下限)
实验将包含树莓派和英伟达 2080ti,以便将所测试硬件与广为人知的系统进行对比,其中树莓派是边缘设备,英伟达 2080ti GPU 常用在云中。
这个下限很简单,我们 Tryolabs 会设计和训练我们自己的深度学习模型。因此,我们有很多算力可用。所以我们当然也就用了。为了确定推理时间的下限,我们在一台英伟达 2080ti GPU 上运行了测试。但是,由于我们仅将其用作参考,所以我们只使用了未经优化的基本模型运行测试。
至于上限,我们选择了卫冕冠军:最流行的单板计算机:树莓派 3B。
神经网络模型
我们这次基准评测主要包含了两种网络:更古老一点的众所周知的 Resnet-50 和谷歌今年推出的全新的 EfficientNet 。
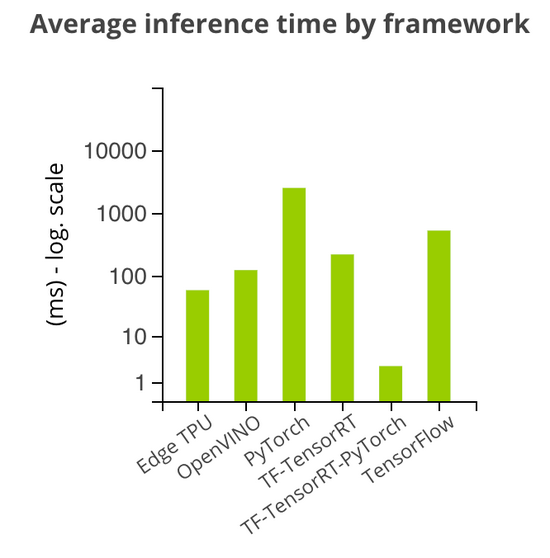
对于所有基准,我们都使用了公开可用的预训练模型,并且使用了不同的框架运行它们。对于英伟达 Jetson,我们尝试了 TensorRT 优化;对于树莓派,我们使用了TensorFlow和 PyTorch 变体;对于 Coral 设备,我们实现了 S、M 和 L 型 EfficientNet 模型的 Edge TPU 引擎版本;至于英特尔神经计算棒,我们使用的是用 OpenVINO 工具包编译的 Resnet-50。
数据集
由于所有模型都是在 ImageNet 数据集上训练的,所以我们使用了 ImageNet V2 MatchedFrequency。其中包含 10000 张图像,分为 1000 类。
我们在每张图像上运行一次推理,保存推理时间,然后求平均。我们计算了所有测试的 top-1 准确度以及特定模型的 top-5 准确度。
top-1 准确度:这是常规的准确度,即模型的答案(概率最高的答案)必须等同于确切的期望答案。
top-5 准确度:即模型的概率最高的前五个答案中任意一个与期望答案匹配。
要记住,在比较结果时,对于更快速的设备-模型组合,我们运行的测试囊括整个数据集,而对于速度更慢的组合我们仅使用了部分数据集。
结果与分析
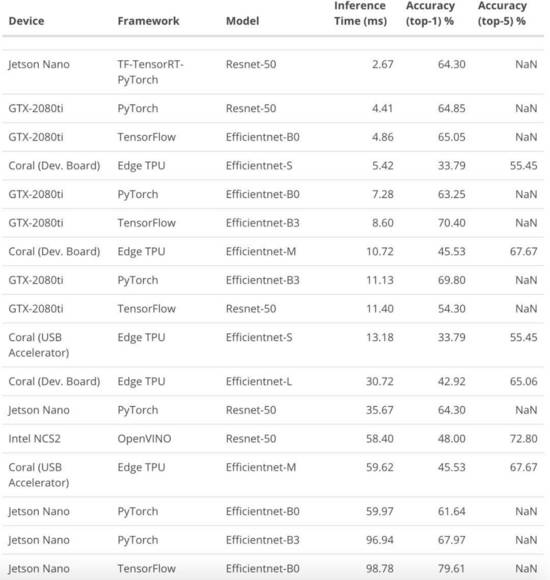
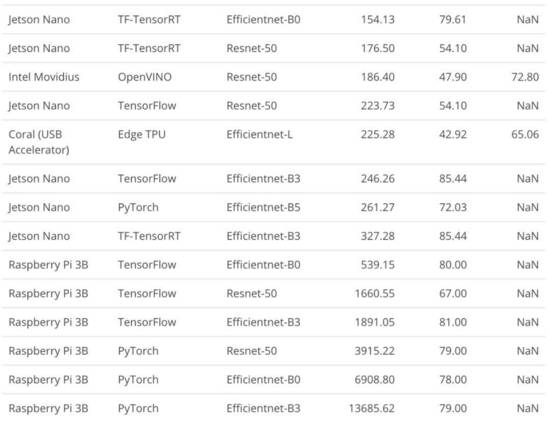
下图展示了实验获得的指标。由于不同模型和设备在推理时间上有较大的差异,所以平均推理时间以对数形式展示。
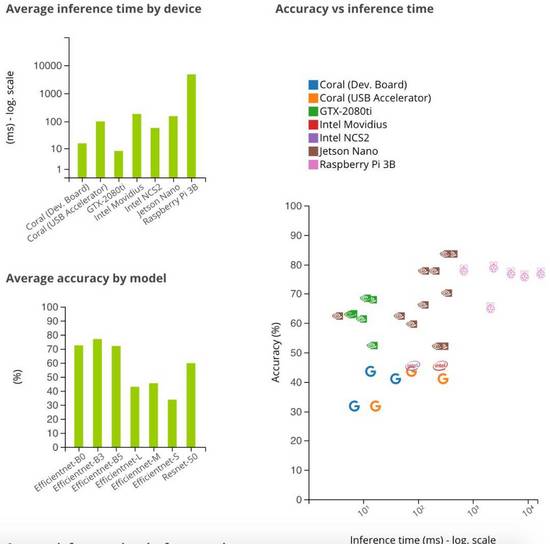
推理时间第一名: Jetson Nano
在推理时间方面,组合使用 ResNet-50、TensorRT 和 PyTorch 的 Jetson Nano 获胜。该组合用 2.67 毫秒处理一张图像,即每秒处理 375 帧。
这个结果很让人惊讶,因为其超过英伟达公布的推理速度十倍之多。结果差异的原因很可能是英伟达使用的是TensorFlow,而非 PyTorch。
推理时间第二名: Coral 开发板
排在第二的是与 EfficientNet-S 搭档的 Coral 开发板。其 5.42 秒完成一张图像处理,即每秒处理 185 帧。
这个结果与谷歌公布的速度差不多,即 5.5 毫秒完成一张,每秒处理 182 帧。
虽然这个组合速度挺高,但准确度却不好。我们没法得知谷歌报告准确度所使用的确切的验证集,但我们猜想他们使用的图像预处理变换方法与我们用的不一样。因为量化的 8 位模型对图像预处理非常敏感,这可能对结果产生很大影响。
准确度第一名: Jetson Nano
准确度方面,最佳结果来自 Jetson Nano 与 TF-TRT 和 EfficentNet-B3 的组合,其实现了 85% 的准确度。但是,这些结果是相对的,因为我们训练模型时,有的模型使用的数据集比其它模型更大一些。
可以看到,当我们向模型输入更小的数据集时,准确率会更高;而当使用完整数据集时,准确度更低。这个结果的原因是我们没有对更小的数据集进行随机排序,因此其中的图像没有实现合理的平衡。
硬件加速器的可用性
关于这些设备的可用性,开发者注意到一些重要的差异。
当涉及到选择和部署预编译的模型和框架时。Jetson 是最灵活的。英特尔神经计算棒紧随其后,因为其提供了很好的库、很多模型和很好的项目。此外,这款计算棒的第二代相比第一代有重大改进。唯一的缺点是他们那庞大的软件库 OpenVINO 仅支持在 Ubuntu 16.04,不支持更新的 Linux操作系统版本。
相比于 Jetson 和英特尔计算棒,Coral 设备存在一些局限性。如果你想在上面运行非官方的模型,你必须将其转换到TensorFlowLite,然后再针对 Edge TPU 进行量化和编译。取决于模型的不同,这种转换有可能无法实现。尽管如此,我们预计谷歌今后会改进这款设备的未来版本。
总结
这里的研究基于我们对为深度学习算法设计的当前最佳边缘计算设备的探索。
我们发现 Jetson Nano 和 Coral 开发板在推理时间方面表现非常好。
而在准确度方面,Jetson Nano 表现也很出色,尽管这个结果是相对的。
从总体表现看,Jetson Nano 是当之无愧的赢家。
但是,必须指出,由于 Jetson Nano 和 Coral 的设计不同,我们没法在两者之上测试同样的模型。我们相信每种设备都有最适合自己的场景,这取决于所要完成的具体任务。




























