本文转自雷锋网,如需转载请至雷锋网官网申请授权。
《面向神经机器翻译的篇章级单语修正模型》[1]是EMNLP2019上一篇关于篇章级神经机器翻译的工作。针对篇章级双语数据稀缺的问题,这篇文章探讨了如何利用篇章级单语数据来提升最终性能,提出了一种基于目标端单语的篇章级修正模型(DocRepair),用来修正传统的句子级翻译结果。

1、背景
近几年来,神经机器翻译迅速发展,google在2017年提出的Transformer模型[2]更是使得翻译质量大幅提升,在某些领域已经可以达到和人类媲美的水平[3]。然而,如今的大部分机器翻译系统仍是基于句子级的,无法利用篇章级的上下文信息,如何在机器翻译过程中有效利用篇章级信息是当今的研究热点之一。
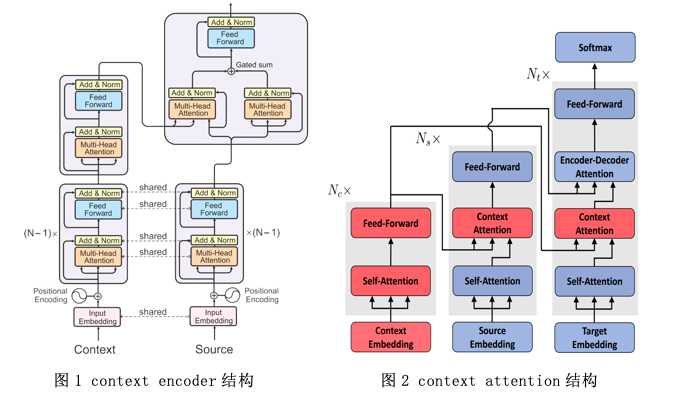
随着基于自注意力机制的Transformer模型在机器翻译任务中广泛应用,许多之前基于循环神经网络(RNN)机器翻译模型的篇章级方法不再适用。最近,许多研究人员尝试对Transformer进行改进,在编码或解码阶段引入上下文信息。Voita等人[4]首先提出了一种基于Transformer的模型(图1)的篇章级翻译模型,在传统的模型之外,额外增加了一个上下文编码器(context encoder)用来编码上下文信息,然后和当前句子的编码结果进行融合,送到解码器。张嘉诚等人[5]采用了另外一种做法,分别在编码器和解码器中增加了一个上下文注意力(context attention)子层(图2)用来引入上下文信息。还有一些研究人员尝试使用二阶段(two-pass)模型的方式[6][7],首先进行句子级解码,然后使用一个篇章级解码器结合句子级解码结果和源语上下文编码来进行篇章级解码。此外,一些工作对篇章级翻译需要引入那些上下文信息进行了探究。
上述工作在机器翻译的过程中引入上下文信息,将篇章级翻译作为一个整体过程。这种方式建模更加自然,但是需要足够的篇章级双语数据进行训练。然而,实际中篇章级双语数据很难获取,作者就是针对篇章级双语数据稀缺的问题提出了DocRepair模型。
2、DocRepair模型
和二阶段的方法类似,DocRepair模型也是对句子级结果的修正,但是不同点在于,DocRepair模型仅仅需要使用单语数据。作为一个单语的序列到序列模型(seq2seq)模型,DocRepair模型需要将上下文不一致的句子组映射到一个一致的结果,来解决上下文的不一致性,过程如图2。

模型的训练语料来自于容易获取的篇章级单语语料。单语数据中上下文一致的句子组作为模型输出,而通过round-trip的方式构建的上下文不一致的句子组作为模型输入。round-trip分为两个阶段,需要正向和反向两个翻译系统。首先使用反向的翻译模型将目标端的篇章级单语数据翻译到源语端,得到丢失了句子间上下文信息的源语结果,然后通过正向的翻译模型将源语结果翻译回目标端,得到最终需要的上下文不一致的目标端数据,整体流程如图3所示。

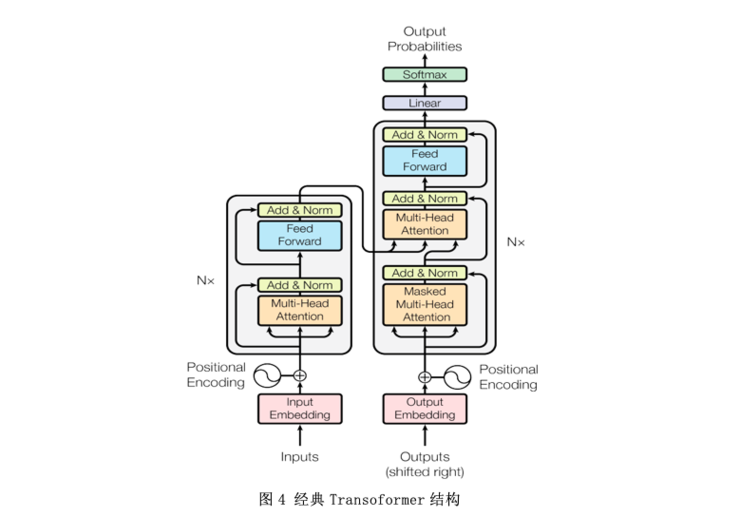
DocRepair模型采用了标准的Transformer结构(图4),模型输入为不包含上下文信息的句子序列,通过一个分隔令牌连接成一个长序列,模型输出为修正后的上下文一致的序列,去掉分隔令牌得到最终结果。
作者提出的这种结构可以看作一个自动后编辑系统,独立于翻译模型,最大的优点就在于只需要使用目标端单语数据就能构造训练集。相对应的,这种方法引入了额外的结构,增加了整体系统的复杂度,使得训练和推理代价变大。同时,由于仅仅在目标端根据翻译结果进行修正,完全没有引入源语端的信息,DocRepair模型可能没有充分考虑到上下文信息。之前的一些工作也证实了源语端上下文信息在篇章级机器翻译中的作用,如何利用源语端的单语数据来更好地提取上下文信息也是未来一个值得研究的方向。
3、实验
为了验证方法的有效性,作者从BLEU、篇章级专用测试集和人工评价三个角度进行了对比实验。实验在英俄任务上进行,数据集使用了开放数据集OpenSubtitles2018。
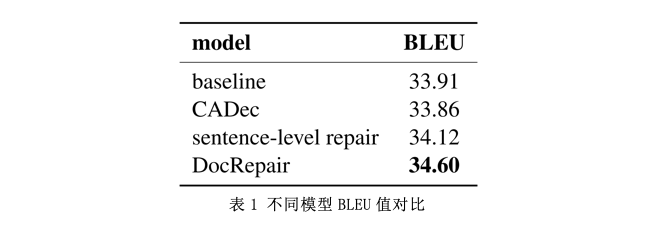
表1是DcoRepair的对比实验结果。其中,baseline采用了Transformer base模型,CADec[7]为一个两阶段的篇章级翻译模型。同时,为了验证DocRepair模型在篇章级翻译上有效性,而不仅仅是因为对句子进行后编辑使得翻译质量提升,同样训练了一个基于句子级的repair模型。可以看到,DocRepair在篇章级机器翻译上是有效的,比sentence-level repair模型高出0.5 BLEU,同时对比baseline和CADec有0.7 BLEU的提升。
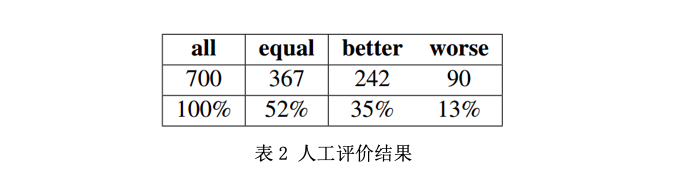
人工评价使用了来自通用测试集的700个样例,不包含DocrePair模型完全复制输入的情况。如表2所示,52%的样例被人工标注成具有相同的质量,剩余的样例中,73%被认为DocrePair输出更有优势,同样证实了模型的有效性。
为了分析DocRepair对篇章级翻译中特定问题的有效性,作者在专为英俄篇章级翻译现象构造的数据集[9]上进行了验证,结果如表3。deixis代表了句子间的指代问题,lex.c表示篇章中实体翻译的一致性问题,ell.infl和ell.VP分别对应了源语端中包含而目标语端不存在的名词形态和动词省略现象。

在指代、词汇选择和名词形态省略问题中,DocRepair具有明显优势,而在动词省略问题中,DocRepair模型对比CADec低了5百分点。可能的原因是DocRepair模型仅仅依赖于目标端单语,而采用round-trip方式构造的训练集中很少包含动词缺失的样本,使得模型很难做出正确预测。
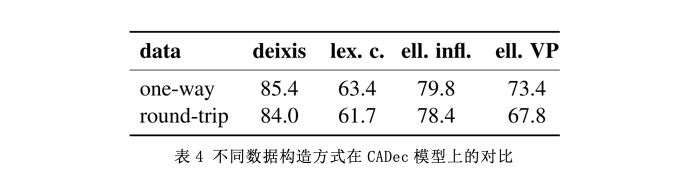
为了验证单语数据的局限性,作者在DocRepair模型上进行了不同数据构造方式的对比实验,结果如表4。one-way表示拿双语数据中的源语替换round-trip的第一步反向过程。可以看出,one-way的方式要整体高于round-trip方式,而其中对于round-trip方式最难的问题就是动词省略。
4、总结
这篇工作提出了完全基于目标端单语的DocRepair模型,用来修正机器翻译结果,解决篇章级不一致性。同时对DcoRepair在具体篇章级问题中的性能进行了分析,指出了仅仅依赖于单语数据和round-trip的构造方式的局限性。
以往的工作大多关注于在解码过程中如何融合上下文信息,但是性能往往受限于篇章级双语数据的稀缺。这篇工作为我们提供了一个新思路,可以避免双语数据稀缺的问题,但是也引出了一个新的问题。篇章级翻译的目标是解决传统句子级翻译中丢失句子间上下文信息的问题,而在这种后编辑的方法中,仅仅使用了目标端的一组没有上下文一致性的翻译结果就可以通过单语修正模型获得一致性的结果,缺乏对源语的关注。笔者认为,在双语稀缺的情况下,如何更好的引入源语上下文信息也是一个有趣的问题。
参考文献
[1] Voita, Elena, Rico Sennrich, and Ivan Titov. "Context-Aware Monolingual Repair for Neural Machine Translation." arXiv preprint arXiv:1909.01383 (2019).
[2] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
[3] Hassan, Hany, et al. "Achieving human parity on automatic chinese to english news translation." arXiv preprint arXiv:1803.05567 (2018).
[4] Voita, E., Serdyukov, P., Sennrich, R., & Titov, I. (2018). Context-aware neural machine translation learns anaphora resolution. arXiv preprint arXiv:1805.10163.
[5] Zhang, J., Luan, H., Sun, M., Zhai, F., Xu, J., Zhang, M., & Liu, Y. (2018). Improving the transformer translation model with document-level context. arXiv preprint arXiv:1810.03581.
[6] Xiong, H., He, Z., Wu, H., & Wang, H. (2019, July). Modeling coherence for discourse neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, pp. 7338-7345).
[7] Voita, E., Sennrich, R., & Titov, I. (2019). When a Good Translation is Wrong in Context: Context-Aware Machine Translation Improves on Deixis, Ellipsis, and Lexical Cohesion. arXiv preprint arXiv:1905.05979.