数据与产品的结合
话题一是数据与产品的结合,以 Stitch Fix 作为例子,阐述数据科学是如何渗透到产品的不同环节的。
Stitch Fix 是一家数据驱动的服装新零售的电商公司,致力帮助用户发现适合他自己的风格款式,主要服务于没时间逛街、对穿搭不在行、想追逐时尚等特征的用户群体。
Stitch Fix 所有的销售都来源于推荐,推荐采用的是盲盒模式,用户在收到商品之前是没有预览过的,这样就意味着需要猜用户会喜欢哪些衣服。如果一旦猜错,消耗的将是造型师服务和双向物流的这些真金白银的成本,所以对准确度的要求非常之高。
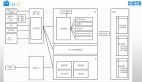
如下图,从普通的用户角度看,使用Stitch Fix 主要分为三步骤。
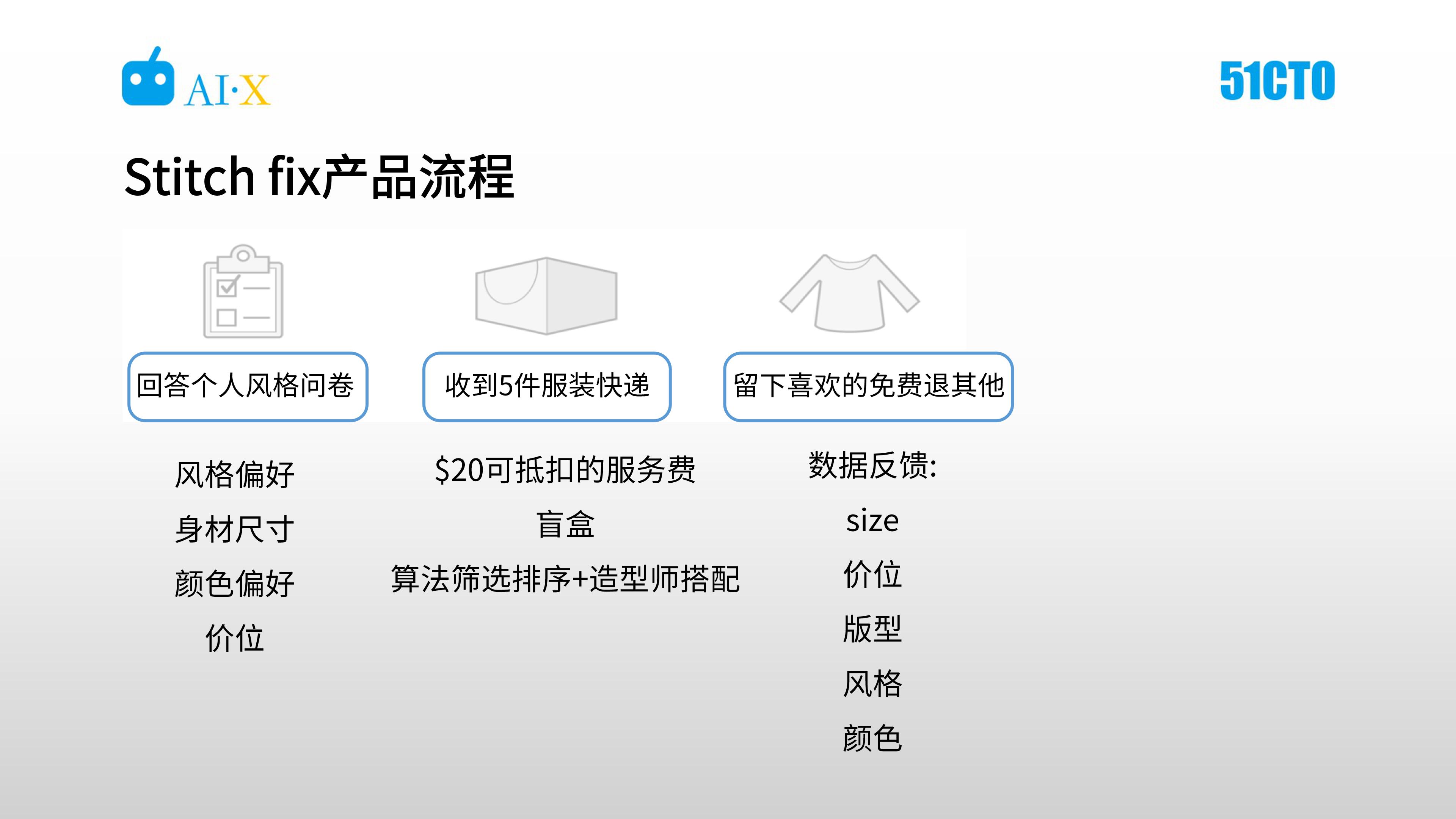
Set.1是回答个人的风格问卷,之后会收到搭配好的五件衣服,试穿后留下喜欢的,免费退回其他不喜欢的。
Stitch Fix 鼓励用户对每一件衣服从尺寸、价位、版型、风格和颜色等维度进行反馈,这些数据将助力数据科学团队更好的了解用户与服装的匹配情况。
数据科学团队人员占员工总数的 1/4,同时也意味着数据科学渗透到产品的很多环节,发挥着应有的价值,例如仓库分配、用户与造型师匹配、用户画像、人货匹配、库存管理等环节。
例一:仓库分配
当有用户请求发出,需要决定从哪一个仓库为用户发货。选仓发货需要综合考虑多个因素,包括运费,投运时间,仓库风格和用户风格匹配情况等,基于这些因素建立仓库和用户之间的匹配度指标。
例二:用户和造型师的匹配
当用户发出请求,依据用户和造型师之间的交易历史,用户打分、以及资料匹配进行造型师匹配。
例三:用户画像
在 Stitch Fix 用户画像既服务于算法,也服务于造型师,故需要一些可解释、可以为人读懂的用户画像。

用户画像大部分来源于用户填写的个人问卷,其中包括基础的纬度画像,以及跟穿搭相关,如说用户的身材尺寸、颜色、价格偏好等。
在处理用户风格上,把穿搭的风格分成七个纬度:经典、浪漫、波希米亚风等,每个用户在每个纬度上有 1 到 4 的打分,基于用户打分可以大概看出来用户的穿搭风格。
例四:人货匹配
这里主要分享数据和模型两个层面,数据层面有:用户画像、商品 ID、商品泛化特征(图像、标签),以及多维度的反馈。推荐算法的数据存在挑战,如 item 的样本不均衡、数据回流带来的误差、特征和反馈数据缺失、折扣带来的偏差等。模型层面(2016 年)有混合效应模型、Factorization machine、DNN、word2vec,、LDA 等。
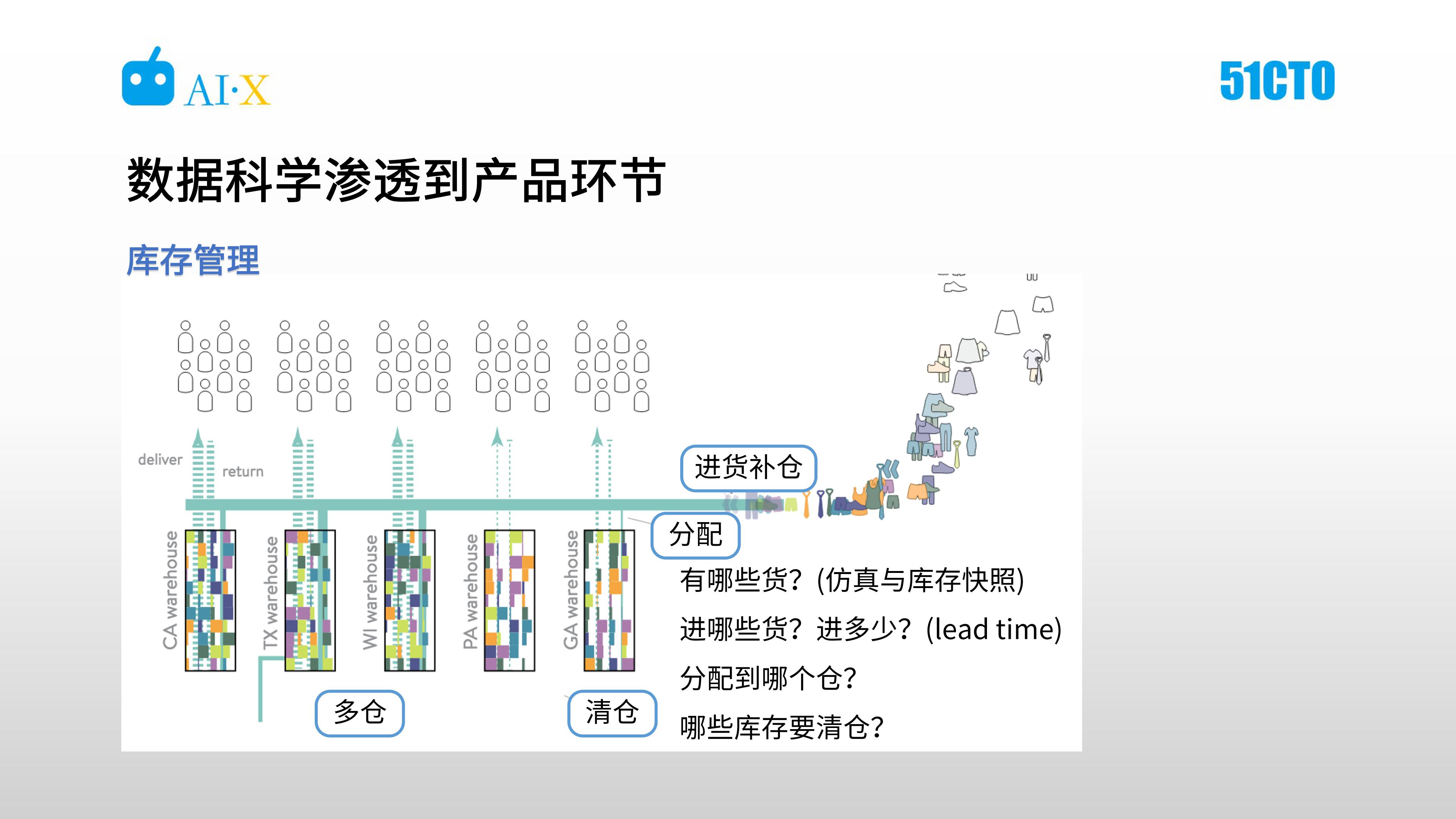
例五:库存管理
在库存管理上,需要解决的问题有很多,如有哪些货、要进哪些货、进多少、分配到哪个仓、及哪些库存需要清仓等。有哪些货看似是一个简单的问题,但在 Stitch Fix 比较特殊,因为库存商品其实仅占所有商品的 40%,有大量的商品存在用户寄回到仓库的路上,或是从仓库寄到用户的路上,这里就需要做仿真与库存快照来应对。
透过上述这些产品的环节发现可以用数据提升效率的机会,定义并解决问题,那么是通过哪些技术实现的呢?这里主要分享普遍关心的三大问题,度量指标的选择及分析,AB 测试和用户画像。
度量指标的选择及分析

在 Stitch Fix 专注转化率、GMV、留存这三大核心指标,对于选择度量指标可参考三点:数据源的可靠性、指标与结果的相关度以及信号质量和敏感度。
Stitch Fix 常用分析主要有漏斗、群组、多纬等,如下图以群组分析示例。

如可以把用户按照获客时间、首单时间分成等标签并分成群组,然后观测在一定时间范围内某些指标的变动,对于时间的跨度可以选择相对比较短的,也可以选择相对比较长的。
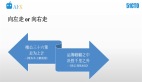
如下图,为不同的获客时间的用户留存对比。
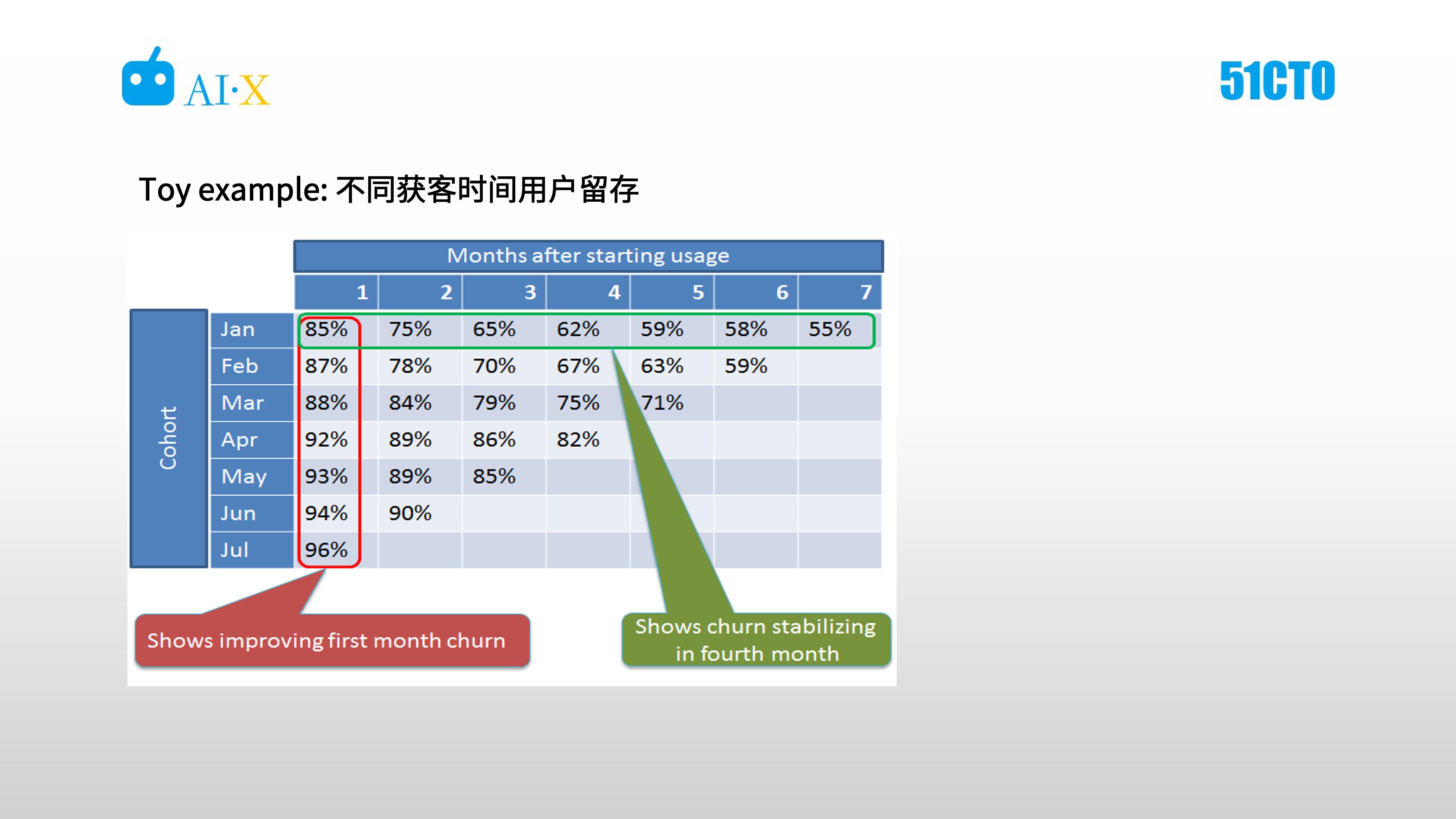
综合看,从 1 月到 7 月,首月的留存在提升,这意味着在渠道获取上,获取的用户质量有待提升。另外也可以看到随着时间的推移,用户留存会有一个平台效应,头四个月,月到月的用户流失是比较显著的,后续的用户留存趋于稳态。
AB 测试
在 Stitch Fix,AB 测试主要面临两个挑战,分别是线下交易带来的延时和造型师人为因素。
当线上算法发生改变时,需要造型师针对每一个用户做出匹配,再加上物流,会产生七到十天的延时。
造型师的人为因素主要是由于造型师的惯性带来的,举一个比较极端的例子,如果算法想重推高单价产品,但造型师却希望给用户推荐一些价格适中的商品,这样就会对结果产生影响。
这里需要提醒的是 AB 测试需谨慎,如下四点要注意:
实验正交设计:实验 1: uid 尾号为奇数 vs 偶数 实验 2: uid 尾号 (0,1) vs 2
用户适应曲线
小流量实验与全流量上线的区别
实验效果叠加:季度上线了 6 个+1% 的实验,但整体提升只有 3%
用户画像
用户画像是在公司范围内基础数据的搭建,也就是大家现在经常提到的数据中台,画像对于推荐业务、用户运营、渠道画像都会有相当的指导意义。
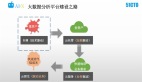
这就意味着画像在公司是需要多部门协作的事情,也会因为多部门协作带来挑战,主要体现在数和应用脱节、多业务需求近似两种情况。实际在生成画像时需要三步走,依次是收集画像需求、构建标签框架和填充数据。
在实用过程中,如果希望破局,有下面三个建议:
放弃大而全的框架,业务场景倒推 (价值)
自动化生成标签 (手段):规则或算法
有效的标签管理机制 (可持续性)
数据与人的结合
第二个话题是数据与人的结合,在 Stitch Fix 是通过算法和造型师结合起来帮用户做推荐搭配,可以认为这是一个人机耦合的系统,那么,人机耦合系统会有哪些挑战呢?

在算法方面,Set.1要对大量的库存进行 SKU 筛选和排序,第二分从大规模数据中找到规律。第三是降噪,因为造型师会存在相当大的个体差异,需要制定一个相对一致的标准,使得最终筛选的结果不会产生很大的偏差。
在人机耦合的系统,造型师承担人的角色,对非结构化数据进行处理,进行 1v1 情感沟通、还具有创造性,这样算法开发时候就可以免于考虑边缘情况。
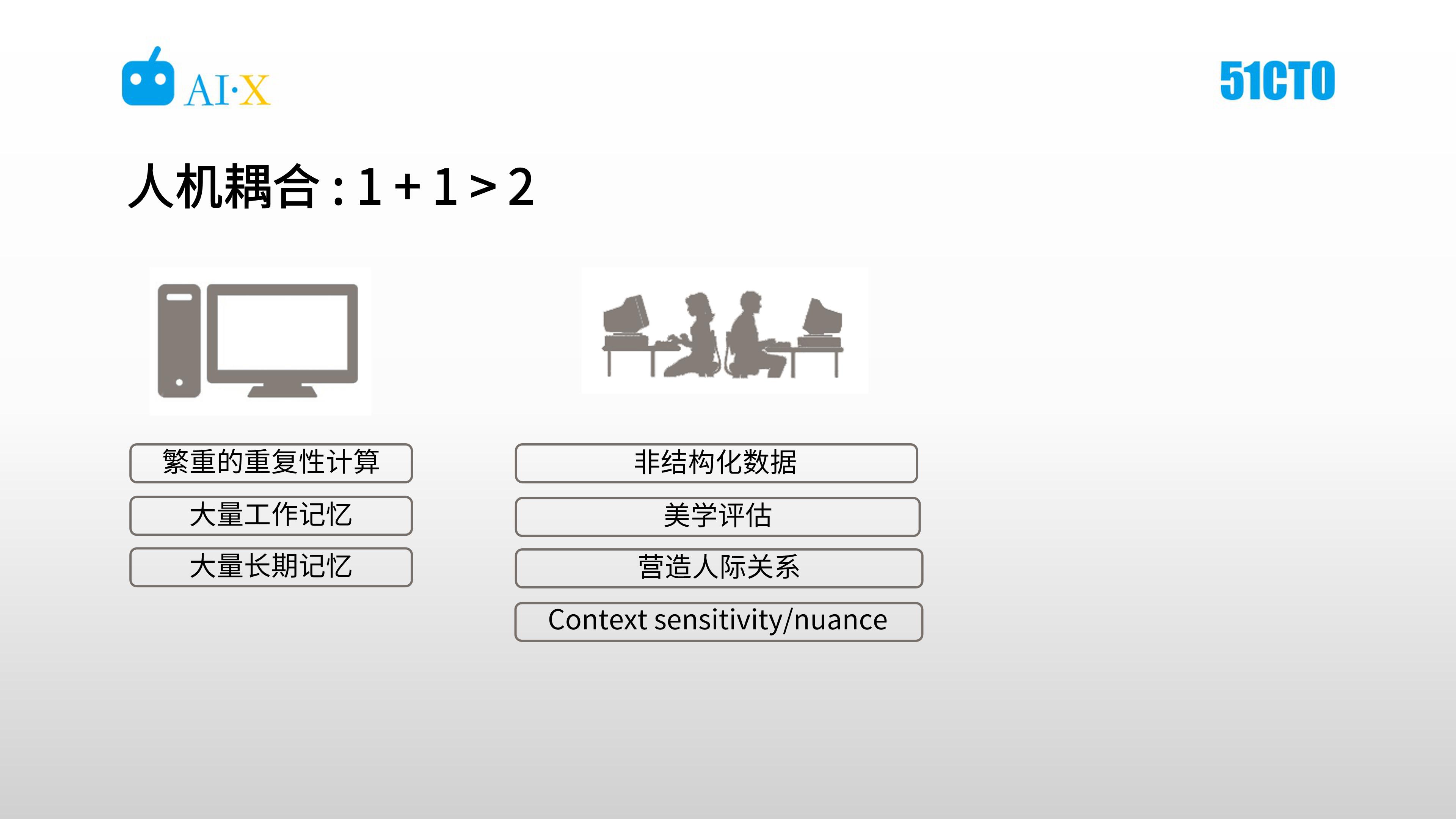
这种人机协同的方式,不是纯粹靠机器算法,也不是纯粹靠人工。机器可以承担更多的繁重的重复性的劳动工作,还拥有大量的工作记忆、长期记忆,而人可以更好的处理非结构化数据,可以进行美学评估,也可以跟客户建立良好的人机关系。
另外人对场景也会有比较强的敏感度,比如说秋天到了,在中西部的人适合穿什么样的衣服,造型师对这个会有比较强的敏感度,进而做比较好的推荐。
在人机耦合中,虽然 1+1 是大于 2 的,但人机耦合也面临如下问题:
人会成为速度和规模的瓶颈:订单分布跟造型师工作时间不匹配
衡量人和机器彼此的价值
对算法多反馈渠道:用户反馈与造型师挑选
算法的优化目标要慎重选择
数据与团队的结合
第三部分是数据和团队的结合,这部分主要介绍在整个数据团队里,包括分析、算法、数据开发是如何结合在一起,及整个数据团队在公司的架构体系下,又是如何和业务团队结合起来协作的。

数据和团队的结合,其实在聊大数据时,聊了很多方法论、思维框架,但最终实施起来,还是要靠数据团队的人来实现以及给公司提供价值。
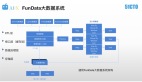
Stitch Fix 数据团队主要分成四部分,底层数据开发团队,可以搭建数据平台、数据仓库,数据科学家提升效率或者做部署工具。
上面三个团队是跟业务一一对应的,客户团队、推荐团队,还有库存团队。
数据团队的搭建上,这里给出三个定位原则,供参考:
以业务与产品为核心。聚焦在产品和业务,使得数据产生实际价值
数据科学团队要结合基础设施部门与业务部门,尤其是业务跨度很大的公司
公司决策层的耐心支持,并与具体工程与产品团队成为有机的一体, 目标对齐一致
在实际操作中,请注意还将面临如下问题:
分析结果如何落地,如何做能够落地的分析
分析处理数据需求与数据驱动业务,处理数据相当于是一个被动的事情,数据团队经常会面临要为业务部门拉数据的任务,但同时数据团队也需要主动去驱动业务,可以认为是被动和主动之间如何做一个协调。
保障数据平台稳定性的同时,数据平台团队也尽可能开发,尽可能帮数据科学家更好的做数据流程,部署代码和线上化的工具。