我们在 MySQL数据库进行表设计时,为了防止表中存在重复数据,我们通常会设置指定的字段为 主键索引(PRIMARY KEY)或者 唯一索引(UNIQUE KEY)索引来保证数据的唯一性。
如果我们设置了唯一索引,当在写入重复数据时,SQL 语句将无法执行成功,并抛出错误。
因此,我们通常在进行 MySQL数据库写入数据操作时,会考虑如何避免数据的重复写入或者因重复数据写入导致运行出错,抛出异常。
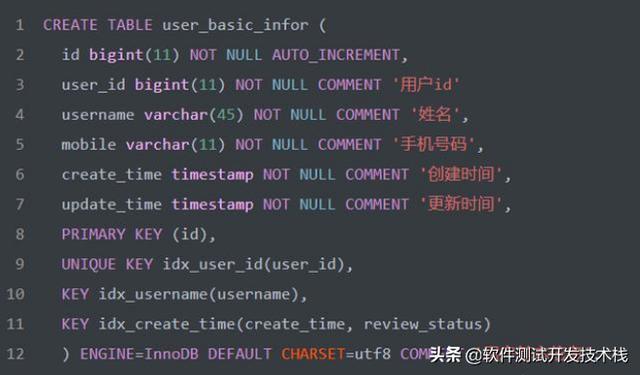
在 MySQL数据库中通常使用以下4种方式可以防止数据的重复写入。本文我们将以 user_basic_infor 表为例(建表SQL语句如下),分别分享如何使用这几种方式避免重复数据的写入。
insert ignore into
如上建表语句,在 user_basic_infor表中使用主键索引(PRIMARY KEY)以及唯一索引(UNIQUE KEY)确保数据具的唯一性,为避免重复写入数据可以使用 insert ignore into 语法,如下:
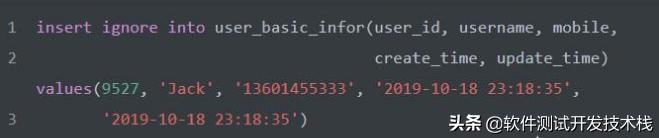
当使用 insert ignore 写入数据时,如果出现错误,如重复数据,将不返回错误,仅以警告形式返回。也就是 insert ignore 会忽略数据库中已经存在的数据,如果写入新数据后不会导致重复,那么写入新的数据,如果写入新数据后会导致重复,那么就跳过这行新数据。
需要注意的是,使用 insert ignore 时,请确保SQL语句本身没有问题,否则也将会被忽略掉。
on duplicate key update
同样,在 user_basic_infor表中使用主键索引(PRIMARY KEY)以及唯一索引(UNIQUE KEY)确保数据具的唯一性,为避免重复写入数据也可以使用 on duplicate key update 语法,如下:
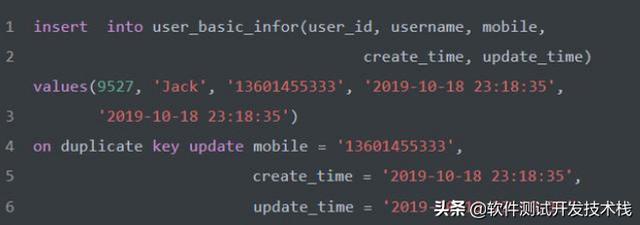
如果在 insert 语句末尾指定了on duplicate key update ……,并且写入行后将导致在主键索引(PRIMARY KEY)或者唯一索引(UNIQUE KEY)中出现重复值时,则对重复值所在的行执行update ,如果不会导致唯一值列重复的问题,则写入该新行。
replace into
同样,在 user_basic_infor表中使用主键索引(PRIMARY KEY)以及唯一索引(UNIQUE KEY)确保数据具的唯一性,为避免重复写入数据也可以使用replace into 语法,如下:
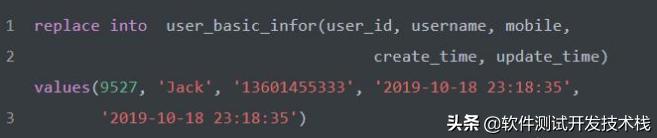
replace 尝试把新行写入到表中,当如果写入数据的主键索引(PRIMARY KEY)以及唯一索引(UNIQUE KEY)出现重复,导致报错而造成写入失败时,会先从表中删除原有涉及到重复的行,然后再次尝试把新行写入到表中,这种方法就是无论原来有没有相同的数据,都会先删除再执行写入。
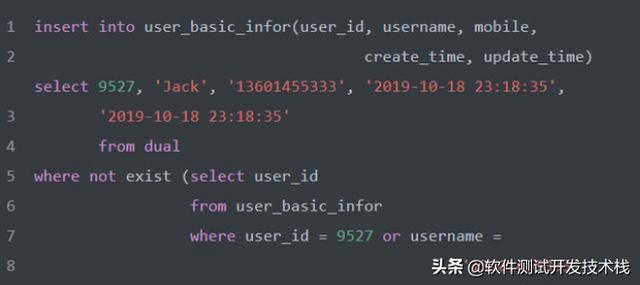
insert … select … where not exist ……
除此之外,在 MySQL数据库中,写入一条数据,我们可以先检查这条数据是否已经存在,当数据不存在时再执行写入操作,这样可以不只通过主键索引(PRIMARY KEY)或者唯一索引(UNIQUE KEY)来判断,也可通过其它条件,如下: