












素描作为一种近乎完美的表现手法有其独特的魅力,随着数字技术的发展,素描早已不再是专业绘画师的专利,今天这篇文章就来讲一讲如何使用python批量获取小姐姐素描画像。文章共分两部分:
1.获取素描图的两个思路
本部分介绍的两个思路都是基于opencv来实现,不涉及深度学习相关内容。基本思想是读入一张照片图,然后通过各种变换转化成素描图。为了演示方便,我们先找来一张小姐姐的照片作为实验素材。
1)漫画风格
先来说第一种方法,这种方法的核心思想是利用了名为“阈值化”的技术,这种技术是基于图像中物体与背景之间的灰度差异,而进行的像素级别的分割。
如果想要把一张图片转化为只呈现黑色和白色的素描图,就需要对其进行二值化操作,opencv中提供了两种二值化操作方法:threshold()和adaptiveThreshold()。相比threshold(),adaptiveThreshold()能够根据图像不同区域亮度分布进行局部自动调节,因此被称为自适应二值化。下面这幅图就是对彩色图片进行二值化操作后的效果。

上面提到的概念可能比较晦涩,不理解也没有关系,下面我们重点讲讲怎么进行实际操作。
第一步,读入图片并转化为灰度图。这一步算是常规操作了,相信使用过opencv的同学都写过类似的代码。
- img_rgb = cv2.imread(src_image)
- img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_RGB2GRAY)
第二步,使用adaptiveThreshold()方法对图片进行二值化操作,函数中的参数大多用于设置自适应二值化的算法和阈值等。
- img_edge = cv2.adaptiveThreshold(img_gray, 255,
- cv2.ADAPTIVE_THRESH_MEAN_C,
- cv2.THRESH_BINARY, blockSize=3, C=2)
第三步,保存转换后的图片
- cv2.imwrite(dst_image, img_edge)
经过上述步骤的操作,我们得到了一幅新的黑白图片,一起来看看转换后的图片效果。

从转换后的图片来看,虽然大概轮廓没有问题,但是效果很不理想,并不能够称之为素描图。这主要是因为adaptiveThreshold()会在图片的每一个小的局部区域内进行二值化操作,因此对于一些清晰度比较高、色彩区分比较细腻的图片,就会出现上面这样密密麻麻的情况。
这个问题解决起来其实也很简单,只要在进行二值化之前加入下面这行代码对原图进行模糊化就可以了。
- img_gray = cv2.medianBlur(img_gray, 5)
再来看看这次生成的素描图(下图),是不是看起来舒服多了,还有一种手绘漫画的感觉。

2)写实风格
通过上面这种方法,虽然最终也获得了一幅还算不错的素描图,但是看起来多少有些“失真”,为了获取看起来更加真实的素描图,我们尝试另外一种方法。
这种方法的核心思想是通过“底片融合”的方式获取原图中一些比较重要的线条,具体实现步骤如下:
第一步,跟上面的方法一样,使用opencv读取图片并生成灰度图。
第二步,对灰度图进行模糊化操作。经过试验,使用上面提到的中值滤波函数cv2.medianBlur()进行模糊化操作最终得到的素描图效果并不好,这里我们尝试使用高斯滤波进行图片模糊化,代码如下:
- img_blur = cv2.GaussianBlur(img_gray, ksize=(21, 21),
- sigmaX=0, sigmaY=0)
其中,参数ksize表示高斯核的大小,sigmaX和sigmaY分别表示高斯核在 X 和 Y 方向上的标准差。
第三步,使用cv2.divide()方法对原图和模糊图像进行融合,cv2.divide()本质上进行的是两幅图像素级别的除法操作,其得到的结果可以简单理解为两幅图之间有明显差异的部分。来看代码:
- cv2.divide(img_gray, img_blur, scale=255)
第四步,保存生成的图片,代码跟上一个方法中一样,我们直接来看获取到的素描图效果。

从结果来看,这种方法获得的素描图线条更加细腻,素描效果也更好。
2.批量获取小姐姐素描画像
在这一部分,我们要实现批量获取小姐姐素描画像的功能,基于上文中两种素描图效果比对,这里采用第二种方法来实现图片到素描图的转换。
那么,接下来要解决的就是图片源的问题了。最近很多项目都成功实现了从抖音或者知乎获取漂亮小姐姐这一操作,其实除了这些平台之外还有好多网站能获取到漂亮小姐姐的图片。
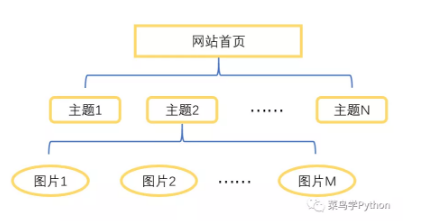
网站的具体内容我就不在文中展示了,为了指定图片爬取的思路,大概讲下页面结构:网站的主页罗列了N个主题,每个主题页面中都包含了M张小姐姐的图片,结构示意图如下:
各页面url的构建也很明了,例如下图中的页面url是http://www.waxjj.cn/2794.html,其中2794就是主题页的ID号。查看页面的html代码(下图),发现每张图片都在一个<li>标签下面。
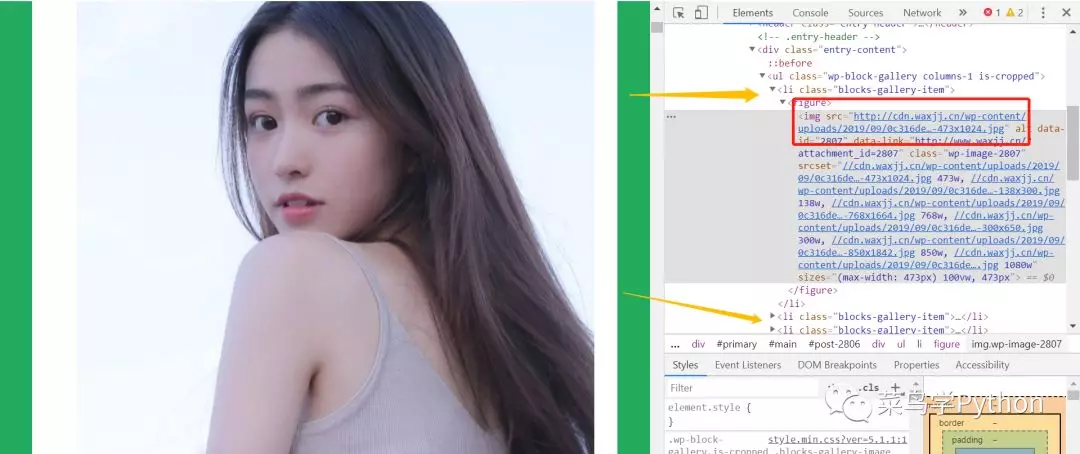
遇到这种情况,一般来说我们可以通过某种解析器来获取每张图片的url。但是,经过仔细观察发现整个网页的html代码中只有涉及图片url的部分带有完整的http连接,因此可以考虑使用正则表达式来提取图片url,实现这部分功能的代码如下。
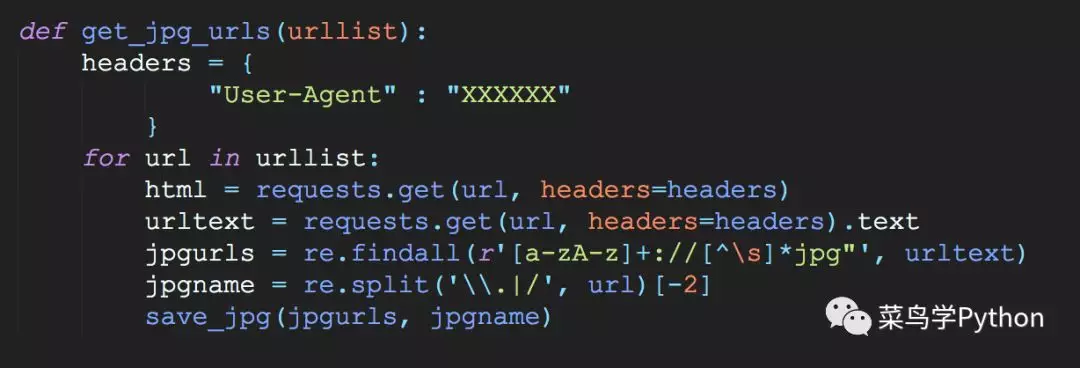
在上面这段代码中,我们提取主题页的ID作为待保存图片名称的一部分,save_jpg()函数中会把每张图片转换为素描图并保存到本地。
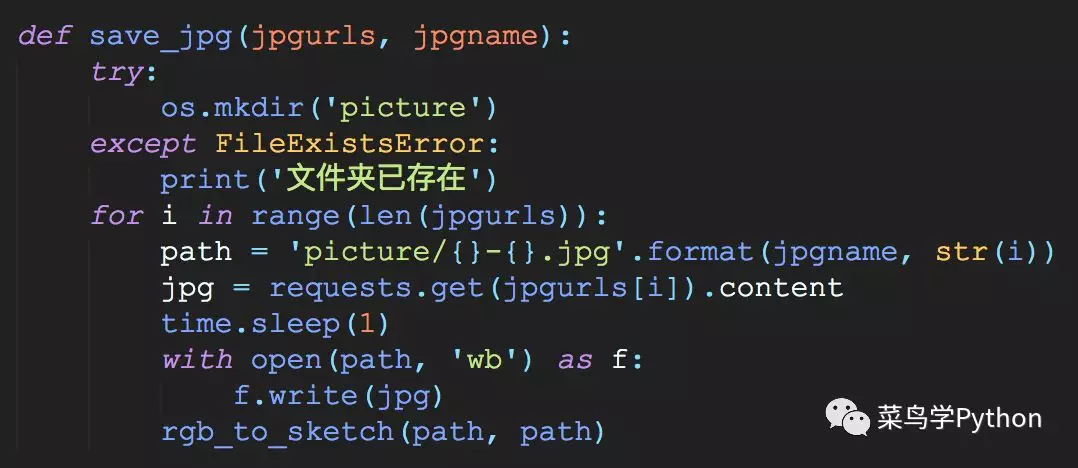
由于我们要使用opencv对抓取到的图片进行各种运算转换,因此使用requests获取的图片必须先保存到本地,再用opencv重新读入后才行。基于上述思想,我们构建了如下所示的save_jpg()函数,其中rgb_to_sketch()函数是对上文第一部分中所说的第二种素描图的获取方法进行的封装。
而在主函数中,我们只需要指定想要获取主题页面的id号,构建一组url列表就可以了:
- def main():
- idlist = ['id1', 'id2']
- urllist = ['http://www.waxjj.cn/'+x+'.html' for x in idlist]
- jpgurls = get_jpg_urls(urllist)
以上就是完整代码,来看看运行后的效果吧~~

其实程序员要想防止脱发程序员还在担心脱发,我觉得还是要多锻炼身体,少熬夜,当然多看看养眼的小姐姐也不是不错的!


















