












获取数据
其实逻辑并不复杂:
- 爬取歌单列表里的所有歌单url。
- 进入每篇歌单爬取所有歌曲url,去重。
- 进入每首歌曲首页爬取热评,汇总。
歌单列表是这样的:
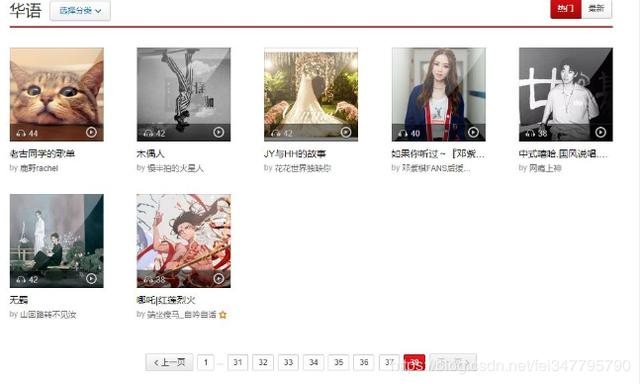
翻页并观察它的url变化,注意下方动图,每次翻页末尾变化35。
采用requests+pyquery来爬取:
- def get_list():
- list1 = []
- for i in range(0,1295,35):
- url = 'https://music.163.com/discover/playlist/?order=hot&cat=%E5%8D%8E%E8%AF%AD&limit=35&offset='+str(i)
- print('已成功采集%i页歌单\n' %(i/35+1))
- data = []
- html = restaurant(url)
- doc = pq(html)
- for i in range(1,36): # 一页35个歌单
- a = doc('#m-pl-container > li:nth-child(' + str(i) +') > div > a').attr('href')
- a1 = 'https://music.163.com/api' + a.replace('?','/detail?')
- data.append(a1)
- list1.extend(data)
- time.sleep(5+random.random())
- return list1
这样我们就可以获得38页每页35篇歌单,共1300+篇歌单。
下面我们需要进入每篇歌单爬取所有歌曲url,并且要注意最后“去重”,不同歌单可能包含同一首歌曲。
点开一篇歌单,注意红色圈出的id。
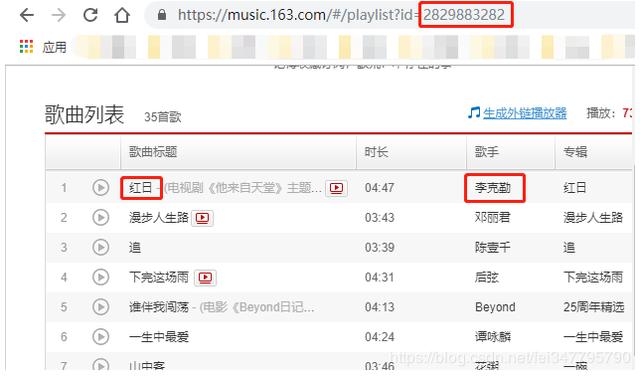
观察一下,我们要在每篇歌单下方获取的信息也就是红框圈出的这些,利用刚刚爬取到的歌单id和网易云音乐的api可以构造出:
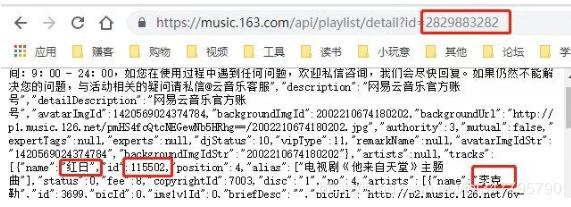
不方便看的话我们解析一下json。
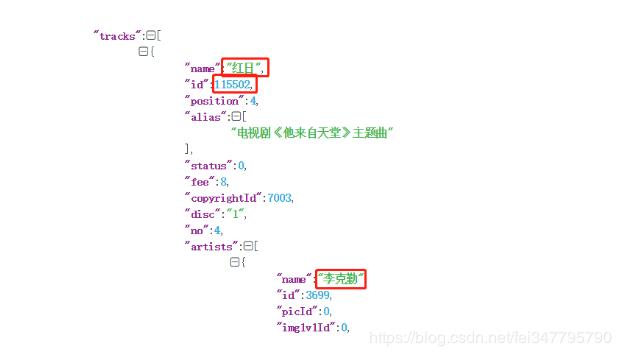
- def get_playlist(url):
- data = []
- doc = get_json(url)
- obj=json.loads(doc)
- jobs=obj['result']['tracks']
- for job in jobs:
- dic = {}
- dic['name']=jsonpath.jsonpath(job,'$..name')[0] #歌曲名称
- dic['id']=jsonpath.jsonpath(job,'$..id')[0] #歌曲ID
- data.append(dic)
- return data
这样我们就获取了所有歌单下的歌曲,记得去重。
- #去重
- data = data.drop_duplicates(subset=None, keep='first', inplace=True)
剩下就是获取每首歌曲的热评了,与前面获取歌曲类似,也是根据api构造,很容易就找到了。
- def get_comments(url,k):
- data = []
- doc = get_json(url)
- obj=json.loads(doc)
- jobs=obj['hotComments']
- for job in jobs:
- dic = {}
- dic['content']=jsonpath.jsonpath(job,'$..content')[0]
- dic['time']= stampToTime(jsonpath.jsonpath(job,'$..time')[0])
- dic['userId']=jsonpath.jsonpath(job['user'],'$..userId')[0] #用户ID
- dic['nickname']=jsonpath.jsonpath(job['user'],'$..nickname')[0]#用户名
- dic['likedCount']=jsonpath.jsonpath(job,'$..likedCount')[0]
- dic['name']= k
- data.append(dic)
- return data
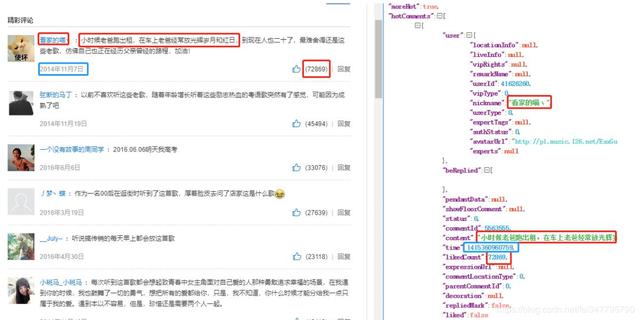
汇总后就获得了44万条音乐热评数据。
数据分析
清洗填充一下。
- def data_cleaning(data):
- cols = data.columns
- for col in cols:
- if data[col].dtype == 'object':
- data[col].fillna('缺失数据', inplace = True)
- else:
- data[col].fillna(0, inplace = True)
- return(data)
按照点赞数排个序。
- #排序
- df1['likedCount'] = df1['likedCount'].astype('int')
- df_2 = df1.sort_values(by="likedCount",ascending=False)
- df_2.head()

再看看哪些热评是被复制粘贴搬来搬去的。
- #排序
- df_line = df.groupby(['content']).count().reset_index().sort_values(by="name",ascending=False)
- df_line.head()

第一个和第三个只是末尾有没有句号的区别,可以归为一类。这样的话,重复次数最多个这句话竟然重复了412次,额~~
看看上热评次数次数最多的是哪位大神?从他的身上我们能学到什么经验?
- df_user = df.groupby(['userId']).count().reset_index().sort_values(by="name",ascending=False)
- df_user.head()
按照 user_id 汇总一下,排序。
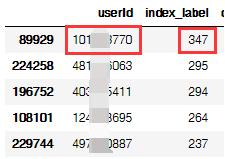
成功“捕获”一枚“段子手”,上热评次数高达347,我们再看看这位大神究竟都评论些什么?
- df_user_max = df.loc[(df['userId'] == 101***770)]
- df_user_max.head()

这位“失眠的陈先生”看来各种情话娴熟于手啊,下面就以他举例来看看如何成为网易云音乐评论里的热评段子手吧。
数据可视化
先看看这347条评论的赞数分布。
- #赞数分布图
- import matplotlib.pyplot as plt
- data = df_user_max['likedCount']
- #data.to_csv("df_user_max.csv", index_label="index_label",encoding='utf-8-sig')
- plt.hist(data,100,normed=True,facecolor='g',alpha=0.9)
- plt.show()
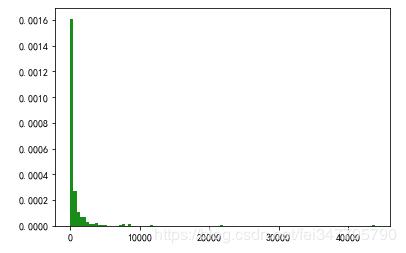
很明显,赞数并不多,大部分都在500赞之内,几百赞却能跻身热评,这也侧面说明了这些歌曲是比较小众的,看来是经常在新歌区广撒网。
我们使用len() 求出每条评论的字符串长度,再画个分布图:
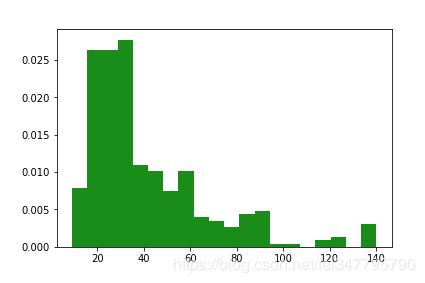
评论的字数集中在18—30字之间,这说明在留言时要注意字数,保险的做法是不要太长让人读不下去,也不要太短以免不够经典。
做个词云。




















