在TCP编程中,我们使用协议(protocol)来解决粘包和拆包问题。本文将详解TCP粘包和半包产生的原因,以及如何通过协议来解决粘包、拆包问题。让你知其然,知其所以然。
1 TCP粘包、拆包图解
由于TCP传输协议面向流的,没有消息保护边界。一方发送的多个报文可能会被合并成一个大的报文进行传输,这就是粘包;也可能发送的一个报文,可能会被拆分成多个小报文,这就是拆包。
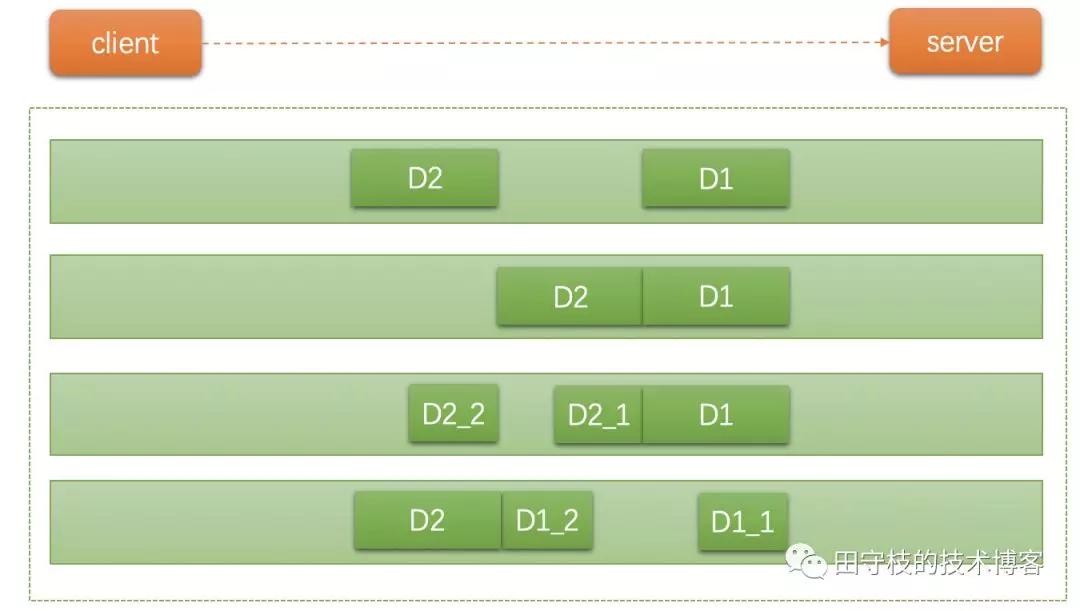
下图演示了粘包、拆包的过程,client分别发送了两个数据包D1和D2给server,server端一次读取到字节数是不确定的,因此可能可能存在以下几种情况:
关于这几种情况说明如下:
server端分两次读取到了两个独立的数据包,分别是D1和D2,没有粘包和拆包
server一次接受到了两个数据包,D1和D2粘合在一起,称之为TCP粘包
server分两次读取到了数据包,第一次读取到了完整的D1包和D2包的部分内容,第二次读取到了D2包的剩余内容,这称之为TCP拆包
Server分两次读取到了数据包,第一次读取到了D1包的部分内容D1_1,第二次读取到了D1包的剩余部分内容D1_2和完整的D2包。
由于发送方发送的数据,可能会发生粘包、拆包的情况。这样,对于接收端就难于分辨出来了,因此必须提供科学的机制来解决粘包、拆包问题,这就是协议的作用。
在介绍协议之前,我们先了解一下粘包、拆包产生的原因。
2 粘包、拆包产生的原因
粘包、拆包问题的产生原因笔者归纳为以下3种:
- socket缓冲区与滑动窗口
- MSS/MTU限制
- Nagle算法
2.1 socket缓冲区与滑动窗口
每个TCP socket在内核中都有一个发送缓冲区(SO_SNDBUF )和一个接收缓冲区(SO_RCVBUF),TCP的全双工的工作模式以及TCP的滑动窗口便是依赖于这两个独立的buffer的填充状态。
SO_SNDBUF:
进程发送的数据的时候假设调用了一个send方法,最简单情况(也是一般情况),将数据拷贝进入socket的内核发送缓冲区之中,然后send便会在上层返回。换句话说,send返回之时,数据不一定会发送到对端去(和write写文件有点类似),send仅仅是把应用层buffer的数据拷贝进socket的内核发送buffer中。
SO_RCVBUF:
把接受到的数据缓存入内核,应用进程一直没有调用read进行读取的话,此数据会一直缓存在相应socket的接收缓冲区内。再啰嗦一点,不管进程是否读取socket,对端发来的数据都会经由内核接收并且缓存到socket的内核接收缓冲区之中。read所做的工作,就是把内核缓冲区中的数据拷贝到应用层用户的buffer里面,仅此而已。
滑动窗口:
TCP连接在三次握手的时候,会将自己的窗口大小(window size)发送给对方,其实就是SO_RCVBUF指定的值。之后在发送数据的时,发送方必须要先确认接收方的窗口没有被填充满,如果没有填满,则可以发送。
每次发送数据后,发送方将自己维护的对方的window size减小,表示对方的SO_RCVBUF可用空间变小。
当接收方处理开始处理SO_RCVBUF 中的数据时,会将数据从socket 在内核中的接受缓冲区读出,此时接收方的SO_RCVBUF可用空间变大,即window size变大,接受方会以ack消息的方式将自己最新的window size返回给发送方,此时发送方将自己的维护的接受的方的window size设置为ack消息返回的window size。
此外,发送方可以连续的给接受方发送消息,只要保证对方的SO_RCVBUF空间可以缓存数据即可,即window size>0。当接收方的SO_RCVBUF被填充满时,此时window size=0,发送方不能再继续发送数据,要等待接收方ack消息,以获得最新可用的window size。
2.2 MSS/MTU分片
MTU (Maxitum Transmission Unit,最大传输单元)是链路层对一次可以发送的最大数据的限制。MSS(Maxitum Segment Size,最大分段大小)是TCP报文中data部分的最大长度,是传输层对一次可以发送的最大数据的限制。
要了解MSS/MTU,首先需要回顾一下TCP/IP五层网络模型模型。
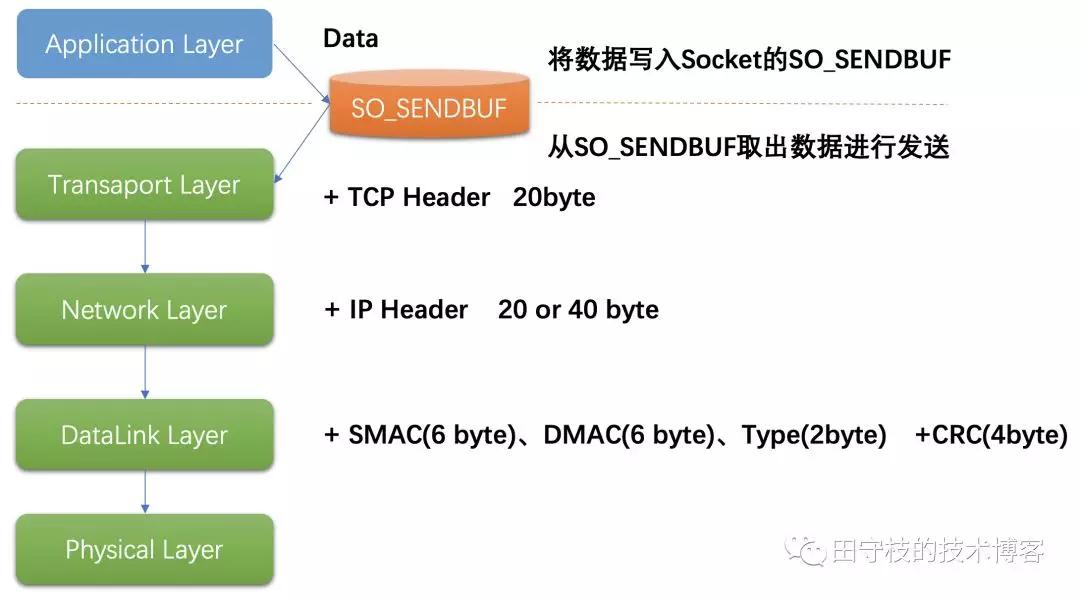
数据在传输过程中,每经过一层,都会加上一些额外的信息:
- 应用层:只关心发送的数据DATA,将数据写入socket在内核中的缓冲区SO_SNDBUF即返回,操作系统会将SO_SNDBUF中的数据取出来进行发送。
- 传输层:会在DATA前面加上TCP Header(20字节)
- 网络层:会在TCP报文的基础上再添加一个IP Header,也就是将自己的网络地址加入到报文中。IPv4中IP Header长度是20字节,IPV6中IP Header长度是40字节。
- 链路层:加上Datalink Header和CRC。会将SMAC(Source Machine,数据发送方的MAC地址),DMAC(Destination Machine,数据接受方的MAC地址 )和Type域加入。SMAC+DMAC+Type+CRC总长度为18字节。
- 物理层:进行传输
在回顾这个基本内容之后,再来看MTU和MSS。MTU是以太网传输数据方面的限制,每个以太网帧最大不能超过1518bytes。刨去以太网帧的帧头(DMAC+SMAC+Type域)14Bytes和帧尾(CRC校验)4Bytes,那么剩下承载上层协议的地方也就是Data域最大就只能有1500Bytes这个值 我们就把它称之为MTU。
MSS是在MTU的基础上减去网络层的IP Header和传输层的TCP Header的部分,这就是TCP协议一次可以发送的实际应用数据的最大大小。
- MSS = MTU(1500) -IP Header(20 or 40)-TCP Header(20)
由于IPV4和IPV6的长度不同,在IPV4中,以太网MSS可以达到1460byte;在IPV6中,以太网MSS可以达到1440byte。
发送方发送数据时,当SO_SNDBUF中的数据量大于MSS时,操作系统会将数据进行拆分,使得每一部分都小于MSS,也形成了拆包,然后每一部分都加上TCP Header,构成多个完整的TCP报文进行发送,当然经过网络层和数据链路层的时候,还会分别加上相应的内容。
另外需要注意的是:对于本地回环地址(lookback)不需要走以太网,所以不受到以太网MTU=1500的限制。linux服务器上输入ifconfig命令,可以查看不同网卡的MTU大小,如下:
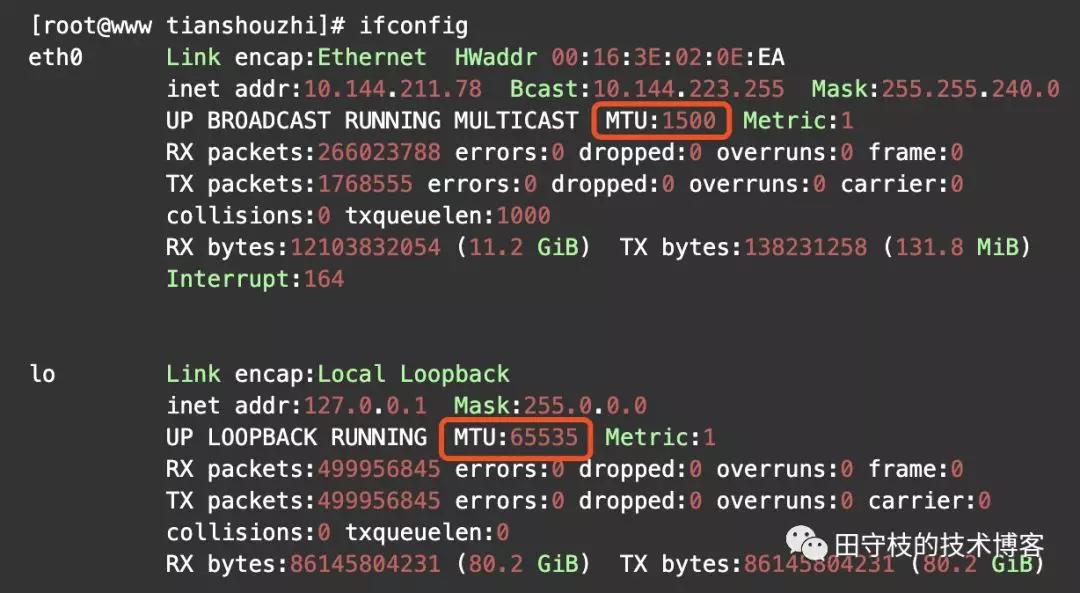
上图显示了2个网卡信息:
- eth0需要走以太网,所以MTU是1500;
- lo是本地回环,不需要走以太网,所以不受1500的限制。
2.3 Nagle算法
TCP/IP协议中,无论发送多少数据,总是要在数据(DATA)前面加上协议头(TCP Header+IP Header),同时,对方接收到数据,也需要发送ACK表示确认。
即使从键盘输入的一个字符,占用一个字节,可能在传输上造成41字节的包,其中包括1字节的有用信息和40字节的首部数据。这种情况转变成了4000%的消耗,这样的情况对于重负载的网络来是无法接受的。称之为"糊涂窗口综合征"。
为了尽可能的利用网络带宽,TCP总是希望尽可能的发送足够大的数据。(一个连接会设置MSS参数,因此,TCP/IP希望每次都能够以MSS尺寸的数据块来发送数据)。Nagle算法就是为了尽可能发送大块数据,避免网络中充斥着许多小数据块。
Nagle算法的基本定义是任意时刻,最多只能有一个未被确认的小段。 所谓“小段”,指的是小于MSS尺寸的数据块,所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。
Nagle算法的规则:
- 如果SO_SNDBUF中的数据长度达到MSS,则允许发送;
- 如果该SO_SNDBUF中含有FIN,表示请求关闭连接,则先将SO_SNDBUF中的剩余数据发送,再关闭;
- 设置了TCP_NODELAY=true选项,则允许发送。TCP_NODELAY是取消TCP的确认延迟机制,相当于禁用了Negale 算法。正常情况下,当Server端收到数据之后,它并不会马上向client端发送ACK,而是会将ACK的发送延迟一段时间(假一般是40ms),它希望在t时间内server端会向client端发送应答数据,这样ACK就能够和应答数据一起发送,就像是应答数据捎带着ACK过去。当然,TCP确认延迟40ms并不是一直不变的,TCP连接的延迟确认时间一般初始化为最小值40ms,随后根据连接的重传超时时间(RTO)、上次收到数据包与本次接收数据包的时间间隔等参数进行不断调整。另外可以通过设置TCP_QUICKACK选项来取消确认延迟。
- 未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送;
- 上述条件都未满足,但发生了超时(一般为200ms),则立即发送。
3 通信协议
在了解了粘包、拆包产生的原因之后,现在来分析接收方如何对此进行区分。道理很简单,如果存在不完整的数据(拆包),则需要继续等待数据,直至可以构成一条完整的请求或者响应。
通过定义通信协议(protocol),可以解决粘包、拆包问题。协议的作用就定义传输数据的格式。这样在接受到的数据的时候:
如果粘包了,就可以根据这个格式来区分不同的包
如果拆包了,就等待数据可以构成一个完整的消息来处理。
3.1 定长协议
定长协议:顾名思义,就是指定一个报文的必须具有固定的长度。例如,我们规定每3个字节,表示一个有效报文,如果我们分4次总共发送以下9个字节:
- +---+----+------+----+
- | A | BC | DEFG | HI |
- +---+----+------+----+
那么根据协议,我们可以判断出来,这里包含了3个有效的请求报文,如下:
- +-----+-----+-----+
- | ABC | DEF | GHI |
- +-----+-----+-----+
在定长协议中:
- 发送方,必须保证发送报文长度是固定的。如果报文字节长度不能满足条件,如规定长度是1024字节,但是实际需要发送的内容只有900个字节,那么不足的部分可以补充0。因此定长协议可能会浪费带宽。
- 接收方,每读取到固定长度的内容时,则认为读取到了一个完整的报文。
提示:Netty中提供了FixedLengthFrameDecoder,支持把固定的长度的字节数当做一个完整的消息进行解码
3.2 特殊字符分隔符协议
在包尾部增加回车或者空格符等特殊字符进行分割 。例如,按行解析,遇到字符\n、\r\n的时候,就认为是一个完整的数据包。对于以下二进制字节流:
- +--------------+
- | ABC\nDEF\r\n |
- +--------------+
那么根据协议,我们可以判断出来,这里包含了2个有效的请求报文
- +-----+-----+
- | ABC | DEF |
- +-----+-----+
在特殊字符分隔符协议中:
- 发送方,需要在发送一个报文时,需要在报文尾部添加特殊分割符号;
- 接收方,在接收到报文时,需要对特殊分隔符进行检测,直到检测到一个完整的报文时,才能进行处理。
在使用特殊字符分隔符协议的时候,需要注意的是,我们选择的特殊字符,一定不能在消息体中出现,否则可能会出现错误的拆包。例如,发送方希望把”12\r\n34”,当成一个完整的报文,如果是按行拆分,那么就会错误的拆分为2个报文。一种解决策略是,发送方对需要发送的内容预先进行base64编码,由于base64编码只包含64个字符:0-9、a-z、A-Z、+、/,我们可以选择这64个字符之外的特殊字符作为分隔符。
提示:netty中提供了DelimiterBasedFrameDecoder根据特殊字符进行解码。事实上,我们熟悉的的缓存服务器redis,也是通过换行符来区分一个完整的报文。
3.3 变长协议
将消息区分为消息头和消息体,在消息头中,我们使用一个整形数字,例如一个int,来表示消息体的长度。而消息体实际实际要发送的二进制数据字节。以下是一个基本格式:
- header body
- +--------+----------+
- | Length | Content |
- +--------+----------+
在变长协议中:
- 发送方,发送数据之前,需要先获取需要发送内容的二进制字节大小,然后在需要发送的内容前面添加一个整数,表示消息体二进制字节的长度。
- 接收方,在解析时,先读取内容长度Length,其值为实际消息体内容(Content)占用的字节数,之后必须读取到这么多字节的内容,才认为是一个完整的数据报文。
提示:Netty中提供了LengthFieldPrepender给实际内容Content进行编码添加Length字段,接受方使用LengthFieldBasedFrameDecoder解码。
3.4 序列化
序列化本质上已经不是为了解决粘包和拆包问题,而是为了在网络开发中可以更加的便捷。在变长协议中,我们看到可以在实际要发送的数据之前加上一个length字段,表示实际要发送的数据的长度。这实际上给我们了一个很好的思路,我们完全可以将一个对象转换成二进制字节,来进行通信,例如使用一个Request对象表示请求,使用一个Response对象表示响应。
序列化框架有很多种,我们在选择时,主要考虑序列化/反序列化的速度,序列化占用的体积,多语言支持等。下面列出了业界流行的序列化框架:
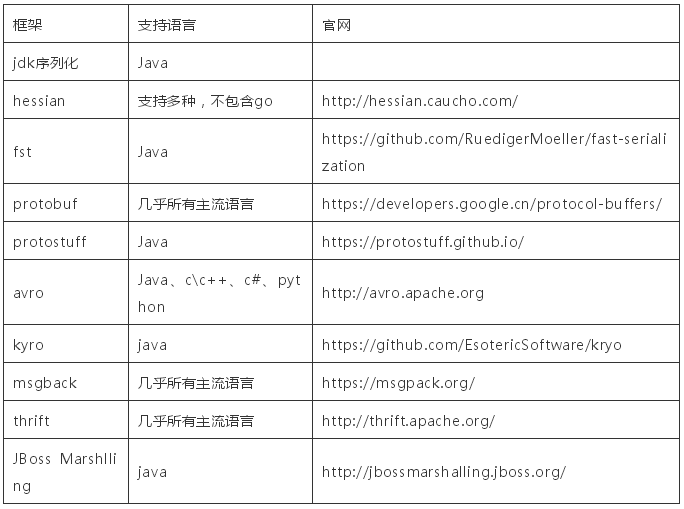
提示:xml、json也属于序列化框架的范畴,上面的表格中并没有列出。
一些网络通信的RPC框架通常会支持多种序列化方式,例如dubbo支持hessian、json、kyro、fst等。在支持多种序列化框架的情况下,在协议中通常需要有一个字段来表示序列化的类型,例如,我们可以将上述变长协议的格式改造为:
- +--------+-------------+------------+
- | Length | serializer | Content |
- +--------+-------------+------------+
这里使用1个字节表示Serializer的值,使用不同的值代表不同的框架。
发送方,选择好序列化框架后编码后,需要指定Serializer字段的值。
接收方,在解码时,根据Serializer的值选择对应的框架进行反序列化;
3.5 压缩
通常,为了节省网络开销,在网络通信时,可以考虑对数据进行压缩。常见的压缩算法有lz4、snappy、gzip等。在选择压缩算法时,我们主要考虑压缩比以及解压缩的效率。
我们可以在网络通信协议中,添加一个compress字段,表示采用的压缩算法:
- +--------+-----------+------------+------------+
- | Length | serializer| compress | Content |
- +--------+-----------+------------+------------+
通常,我们没有必要使用一个字节,来表示采用的压缩算法,1个字节可以标识256种可能情况,而常用压缩算法也就那么几种,因此通常只需要使用2~3个bit来表示采用的压缩算法即可。
另外,由于数据量比较小的时候,压缩比并不会太高,没有必要对所有发送的数据都进行压缩,只有再超过一定大小的情况下,才考虑进行压缩。如rocketmq,producer在发送消息时,默认消息大小超过4k,才会进行压缩。因此,compress字段,应该有一个值,表示没有使用任何压缩算法,例如使用0。
3.6 查错校验码
一些通信协议传输的数据中,还包含了查错校验码。典型的算法如CRC32、Adler32等。java对这两种校验方式都提供了支持,java.util.zip.Adler32、java.util.zip.CRC32。
- +--------+-----------+------------+------------+---------+
- | Length | serializer| compress | Content | CRC32 |
- +--------+-----------+------------+------------+---------+
这里并不对CRC32、Adler32进行详细说明,主要是考虑,为什么需要进行校验?
有人说是因为考虑到安全,这个理由似乎并不充分,因为我们已经有了TLS层的加密,CRC32、Adler32的作用不应该是为了考虑安全。
一位同事的观点,我非常赞同:二进制数据在传输的过程中,可能因为电磁干扰,导致一个高电平变成低电平,或者低电平变成高电平。这种情况下,数据相当于受到了污染,此时通过CRC32等校验值,则可以验证数据的正确性。
另外,通常校验机制在通信协议中,是可选的配置的,并不需要强制开启,其虽然可以保证数据的正确,但是计算校验值也会带来一些额外的性能损失。如Mysql主从同步,虽然高版本默认开启CRC32校验,但是也可以通过配置禁用。
3.7 小结
本节通过一些基本的案例,讲解了在TCP编程中,如何通过协议来解决粘包、拆包问题。在实际开发中,通常我们的协议会更加复杂。例如,一些RPC框架,会在协议中添加唯一标识一个请求的ID,一些支持双向通信的RPC框架,如sofa-bolt,还会添加一个方向信息等。当然,所谓复杂,无非是在协议中添加了某个字段用于某个用途,只要弄清楚这些字段的含义,也就不复杂了。