Pandas对数据科学界来说是一份天赐的礼物。问任何一个数据科学家,他们喜欢如何使用Python处理他们的数据集,他们无疑会谈到Pandas。
Pandas是一个伟大的编程库的缩影:简单、直观、功能广泛。
然而,对数据科学家的一项常规任务,使用Pandas进行数千甚至数百万次的计算,仍然是一个挑战。你不能只是将数据放入,编写Python for循环,然后期望在合理的时间内处理数据。
Pandas是为一次性处理整个行或列的矢量化操作而设计的—循环遍历每个单元格、行或列并不是这个库的设计用途。因此,在使用Pandas时,你应该考虑到矩阵操作是高度并行化的。
本指南将教你如何使用Pandas的方式,它被设计用来使用矩阵运算。在此过程中,我将向你展示一些实用的节省时间的技巧和技巧,它们将使你的Pandas代码运行得比那些可怕的Python for循环快得多!
设置
在本教程中,我们将使用经典的鸢尾花数据集。我们通过使用seaborn加载数据集并打印出前5行来开始。
现在让我们建立一个基线,用Python for循环来测量我们的速度。我们将通过循环遍历每一行来设置要在数据集上执行的计算,然后测量整个操作的速度。这将为我们提供一个基准,看看我们的新优化能在多大程度上帮助我们加速。
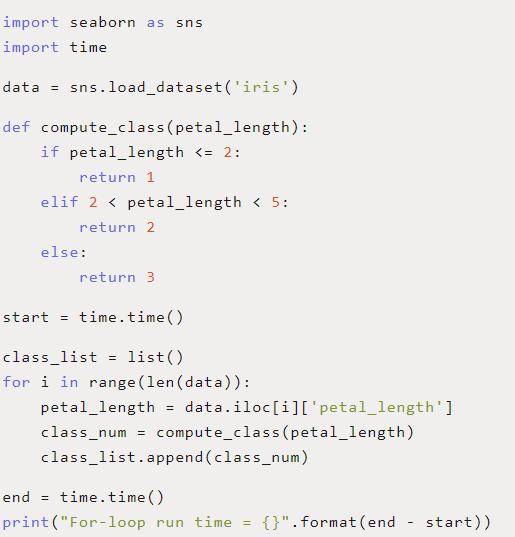
在上面的代码中,我们创建了一个基本函数,它使用If-Else语句根据花瓣的长度选择花的类。我们编写了一个for循环,通过循环dataframe对每一行使用这个函数,然后测量循环的总运行时间。
在我的i7-8700k计算机上,循环运行5次平均需要0.01345秒。
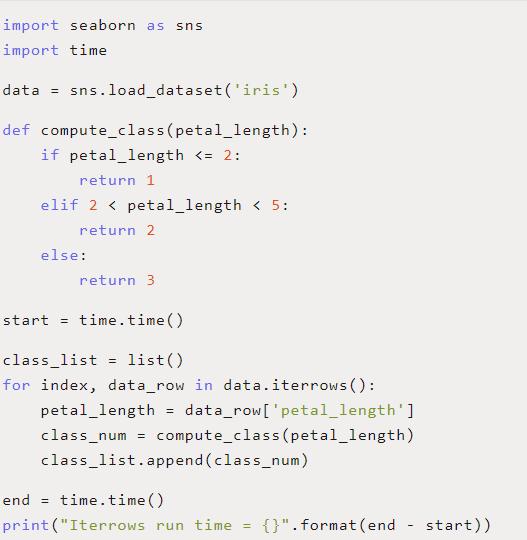
使用.iterrows()来实现循环
我们可以立即做的最简单但非常有价值的加速是使用Pandas的内置 .iterrows()函数。
在上一节中编写for循环时,我们使用了 range()函数。然而,当我们在Python中对大范围的值进行循环时,生成器往往要快得多。在本文中(https://towardsdatascience.com/5-advancedfeaturesof-python-and-how-use-them-73bffa373c84),你可以阅读更多关于生成器如何工作的信息,并加快运行速度。
Pandas中的 .iterrows()函数在内部实现了一个生成器函数,它将在每次迭代中“生成”一行数据。更准确地说, .iterrows()为DataFrame中的每一行生成(index, Series) 的对(元组)。这实际上与在原始Python中使用类似于 enumerate()的东西是一样的,但是运行速度要快得多。
下面我们修改了代码,使用 .iterrows()替常规的for循环。在我上一节测试所用的同一台机器上,平均运行时间为0.005892秒—提高了2.28倍!
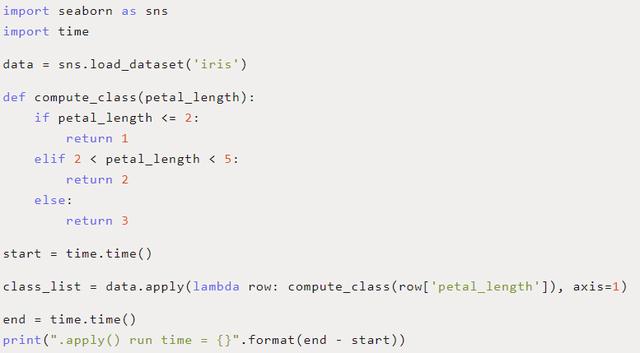
使用.apply()完全丢掉循环
.iterrows()函数极大地提高了速度,但还远远不够。请始终记住,当使用为向量操作设计的库时,可能有一种方法可以在完全没有for循环的情况下很高效地完成任务。
提供这种功能的Pandas函数是 .apply()函数。我们的函数 .apply()接受另一个函数作为它的输入,并沿着DataFrame的轴(行、列等)应用它。在传递函数的这种情况下,lambda通常可以方便地将所有内容打包在一起。
在下面的代码中,我们已经完全用 .apply()和lambda函数替换了for循环来封装我们想要的计算。在我的机器上,这段代码的平均运行时间是0.0020897秒—比原来的for循环快6.44倍。
.apply()之所以要快得多,是因为它在内部尝试遍历Cython迭代器。如果你的函数恰好为Cython进行了很好的优化, .apply()将使你的速度更快。额外的好处是,使用内置函数可以生成更干净、更可读的代码。
最后是使用cut
前面我提到过,如果你正在使用一个为向量化操作设计的库,那么你应该始终寻找一种不使用for循环进行任何计算的方法。
类似地,许多以这种方式设计的库,包括Pandas,都具有方便的内置函数,可以执行你正在寻找的精确计算—但是速度更快。
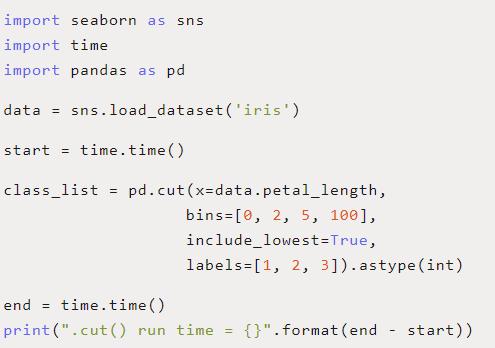
Pandas的 .cut()函数接受一组 bins为输入,其中定义每个If-Else的范围,以及一组 labels作为输入,其中定义为每个范围返回哪个值。然后,它执行与我们用 compute_class()函数手动编写的操作完全相同的操作。
查看下面的代码,看看 .cut()是如何工作的。我们又一次得到了更干净、更可读的代码。最后, .cut()函数平均运行0.001423秒—比原来的for循环快了9.39倍!