在 2011 年,Marc Andressen 写了一篇文章,题目是《为什么软件正在吞噬整个世界》。其中心思想是如果流程可以通过软件来实现,那么就一定会实现。这已经成为一种投资理论简略的表达方式,这种理论隐藏在硅谷目前独角兽初创企业浪潮的背后。它还是我们如今看到的更广泛的技术趋势背后的统一思想,这些技术包括机器学习、物联网、无处不在的 SaaS 以及云计算。这些趋势都在用不同的方法使软件变得更丰富和功能强大,并在企业间扩大其影响范围。
我认为,伴随而来的变化容易被忽视但同样重要。这不仅仅是企业使用更多的软件,而且越来越多的企业通过软件重新定义。也即,企业执行的核心过程(从生产产品的方式到与客户交互的方式、交付服务的方式)正变得越来越多地在软件中指定、监控和执行。这已经是大多数硅谷技术公司的事实情况,但是,这种转变正在蔓延到所有类型的公司,无论其提供什么产品或服务。
为了澄清我的意思,让我们来看一个例子:消费银行的贷款批准流程。这是一个在计算机出现以前就存在的业务流程。传统上,这是一个需要几个星期才能完成的流程,其中涉及银行代理人、抵押贷款官员和信贷官员等,各自以手动过程进行协作。如今,该流程趋向于以半自动化的方式执行,这些功能都有一些独立的软件应用程序,可以帮助使用者更有效地执行。
然而现在,在很多银行中这个操作正在变为一个完全自动化的流程,其中信贷软件、风险软件和 CRM 软件之间相互通信并在几秒内提供决策。这里,银行贷款业务部门基本上变为软件了。当然,这不是说公司将只变为软件(即使在最以软件为中心的公司中还是有很多人的),只是整个业务在用软件定义过程。
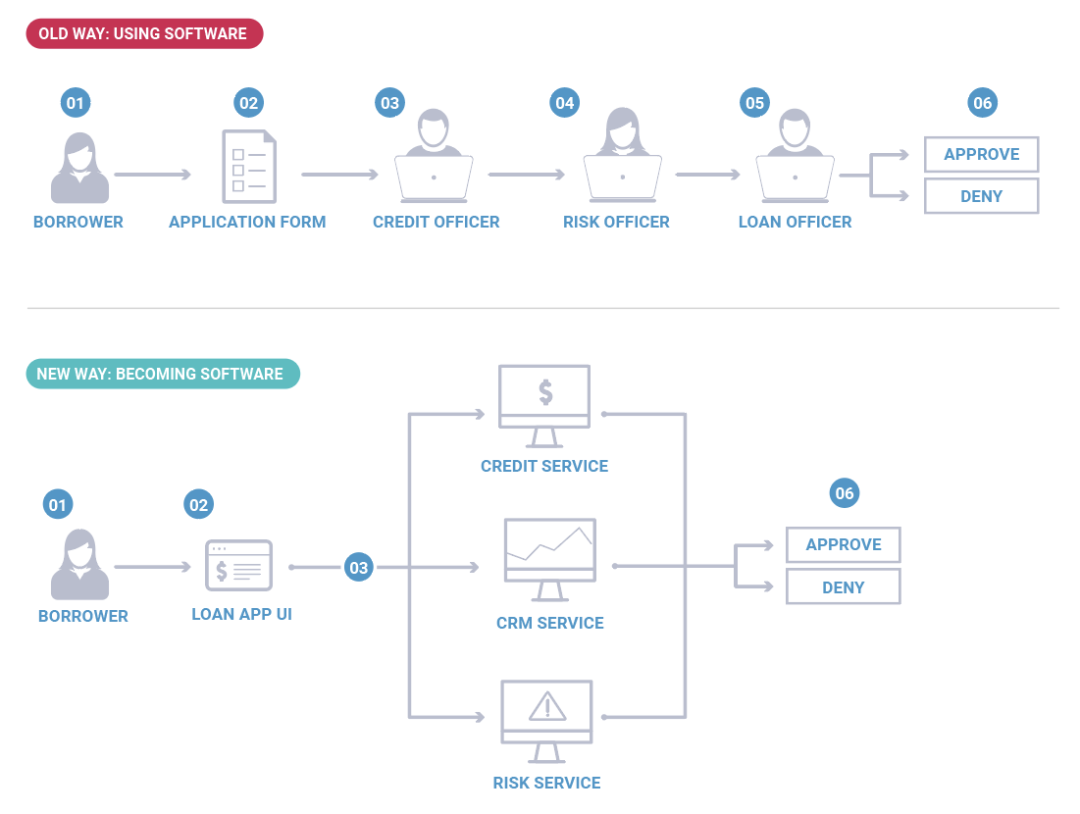
企业不只是把软件用作人工流程生产力的辅助手段,他们正在用代码构建整个业务部分。
这个转变具有很多重要的意义,但是,我关注的是,这对软件本身的角色和设计有什么意义。在这个新兴的世界上,应用程序的目的不太可能是为 UI 提供服务来帮助人们开展业务,更可能的是触发操作或对软件的其他部分作出反应以直接开展业务。尽管这很容易理解,但是,它引发了一个大问题。
传统的数据库架构是否适合这个新兴的世界?
毕竟,数据库一直是应用程序开发中最成功的基础结构层。然而,所有的数据库,从最完善的关系数据库到最新的键值存储,都遵循一种范式,在该范式中,数据是被动存储的,数据库等待命令对它进行检索或修改。被遗忘的是,这种范式的兴起是由一种特定类型的面向用户的应用程序来驱动的,在这种应用程序中,用户可以查看 UI 并启动将其转换为数据库查询的操作。在我们上面提到的例子中,很显然构建了一个关系数据库以支持有助于在这为期 1 到 2 周的贷款批准流程中人为因素的应用程序,但是,是否适合把包括实时贷款批准流程在内的全套软件组合在一起,而该实时贷款批准流程是基于不断变化的数据进行持持续查询而建立的?
实际上,值得注意的是,随着 RDBMS(CRM、HRIS、ERP 等等)的兴起,所有的应用程序都是在软件时代作为人类生产力辅助工具出现的。CRM 应用程序使销售团队更有效率,HRIS 让 HR 团队更有效率等等。这些应用程序都是软件工程师所谓的“CRUD”应用程序。它们帮助用户创建、更新及删除数据库记录,并在该流程上管理业务逻辑。这其中固有的假设是,在网络的另一端有人在驱动和执行该业务过程。这些应用程序的目标是给人们看一些东西(他们会查看结果),给应用程序输入更多的数据。
该模式与公司采用软件的方式相匹配:一点一点地增加由人执行的组织和过程。但是,数据基础设施本身并不知道如何互连或对公司内部其他地方发生的事情做出反应。这导致产生了围绕数据库构建的所有类型的解决方案,其中包括集成层、ETL 产品、消息传递系统,以及大量代码,这些代码是大规模软件集成的标志。
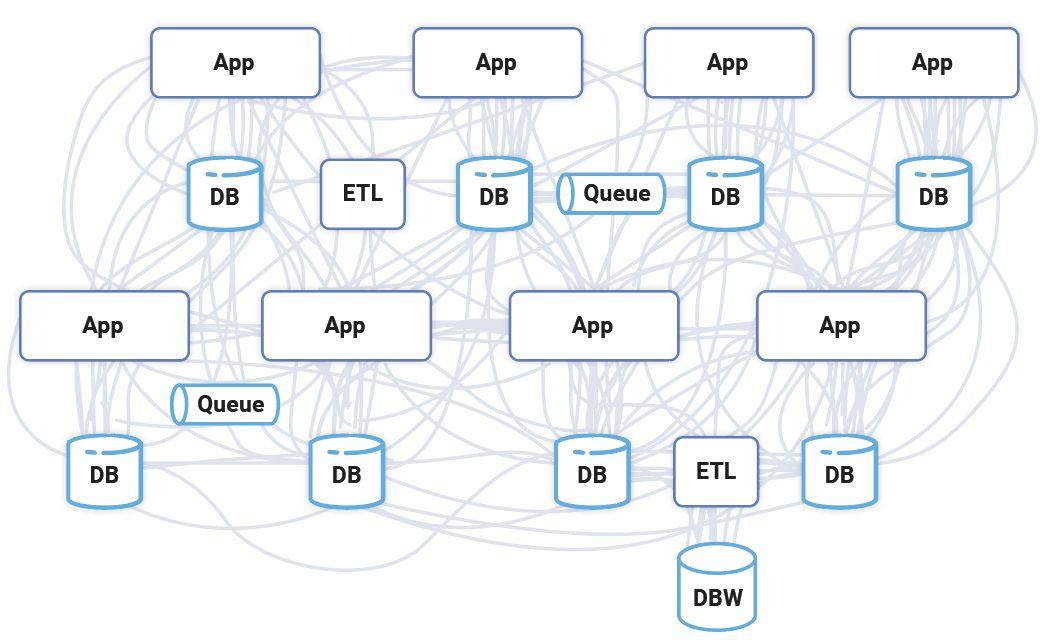
由于数据库没有为数据流建模,因此,公司内部系统之间的互连是一团乱麻。
事件流的兴起
当软件的主要角色不是为 UI 提供服务,而是直接触发操作或对软件的其他部分做出反应时,那么,我们的数据平台需要什么新功能呢?
我认为,要从事件和事件流的概念开始来回答这个问题。什么是事件?发生的任何事情,包括用户登录尝试、购买行为、价格的变化等等。什么是事件流?一系列不断更新的事件,代表了过去发生的事情和现在正在发生的事情。
事件流为传统数据库的数据提供了一种非常不同的思考范式。基于事件构建的系统不再被动地存储数据集和等待来自 UI 驱动的应用程序的命令。与之相反,它的设计目的是支持贯穿整个业务中的数据流以及实时响应和处理发生在业务中的每个事件的反应。这似乎与数据库的领域相去甚远,但是,我认为,数据库的一般概念对未来的发展来说过于狭隘。
Apache Kafka 及其用途
通过分享我自己的背景知识,我将概述一些事件用例。Confluent 的创始人最初在 LinkedIn 工作的时候创建了这个开源项目 Apache Kafka,近年来,Kafka 已经成为事件流运动的基础技术。我们的动机很简单:尽管 LinkedIn 所有的数据是通过一天 24 小时永不停止的流程不断生成的,但是,利用这些数据的基础设施限于每天结束时缓慢的大型批处理数据转储和简单的查找。“一天结束后的批处理”概念似乎是过去穿孔卡片和大型机时代的遗产。事实上,对于一个全球性的企业来说,每天没有结束的概念。
很显然,当我们投入这个挑战时,这个问题没有现成的解决方案。此外,在构建了支持实时网站的 NoSQL 后,我们知道,分布式系统研究和技术的复兴为我们提供了一套工具,以过去不可能的方式来解决这个问题。我们注意到“流处理”的学术文献,流处理是一个研究领域,可以把数据库的存储和数据处理技术扩展到静态表之外,并把它们应用于这类持续、永不停息的数据流,这种数据流是像 LinkedIn 那样的数字业务的核心。
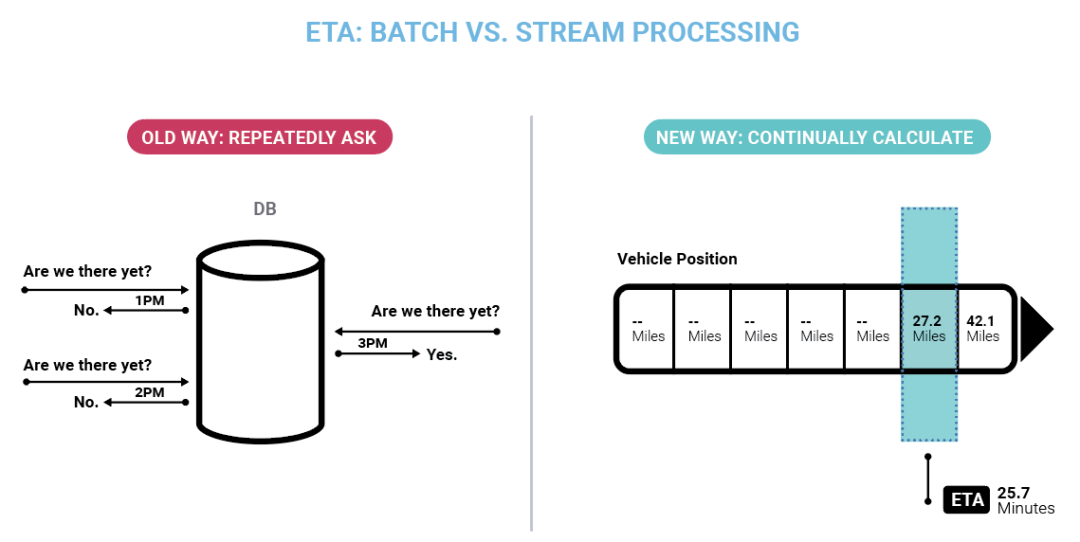
我们都熟悉这个古老的问题:“我们到了吗?”传统数据库有点像个孩子,要回答这个问题除了不断询问,别无选择。借助流处理,ETA 变成一个连续的计算,总是和问题的位置保持同步。
在社交网络中,一个事件可以代表一次点击、一封电邮、一次登录、一个新的连接,或者一次个人资料的更新。把这些数据作为不断发生的流来对待,可以让 LinkedIn 所有的其他系统都可以访问这些数据。
我们的早期用例涉及为 LinkedIn 的社交图片、搜索、Hadoop、数据仓库环境,以及像推荐系统、新闻提要、广告系统的面向用户的应用程序及其他产品功能提供填充数据。随着时间的流逝,Kafka 的使用扩展到安全系统、低级应用程序监控、电邮、新闻提要以及数以百计的其他应用程序。这些都发生在这样一个大规模要求的背景下:每天都有数以万亿计的消息流经 Kafka,并且数以千计的工程师围绕着它工作。
在我们开源 Kafka 后,它在 LinkedIn 外开始了广泛的传播,在 Netflix、Uber、Pinterest、Twitter、Airbnb 等公司出现了类似的架构。
随着我于 2014 年离开 LinkedIn,创办了 Confluent 后,Kafka 和事件流已经开始引起硅谷科技公司以外的广泛关注,并从简单数据管道转变为直接为实时应用程序提供支持。
如今,全球最大的银行中有一些把 Kafka 和 Confluent 用于欺诈检测、支付系统、风险系统和微服务架构。Kafka 是 Euronext 下一代证券交易平台的核心,用于处理欧洲市场数十亿笔交易。
在零售行业,Walmart、Target 和 Nordstrom 等公司已经采用了 Kafka。项目包括实时库存管理,另外还有电子商务和实体设施的整合。零售业传统上建立于每日缓慢的批处理的基础之上,但是,来自电子商务的竞争已经推动了一体化和实时化。
包括 Tesla 和 Audi 在内的多家汽车公司已经为其下一代联网的汽车构建了物联网平台,把汽车数据建模为实时事件流。他们并不是唯一这么做的。火车、船舶、仓储和重型机械也都开始在事件流中捕获数据了。
从硅谷开始的现象现在成了主流,成千上万的组织都在使用 Kafka,其中包括 60% 的财富 100 强公司。
事件流作为中枢神经系统
这些公司中的大多数最初采用 Kafka 是为了一个特定用例启用单个可扩展的实时应用程序或数据管道。这种最初的用法往往可以在公司内部迅速传播到其他应用程序。
这种迅速传播的原因是,事件流都是有多个读者的:一个事件流可以有任意数量的“订阅者”,可以对它进行处理、做出反应或回复。
以零售业为例,零售商可能首先捕获单个用例在商店中发生的销售流,比如,加快仓库管理。每个事件可能表示和一次销售有关的数据:售出的商品、售出商品的商店等等。但是,尽管使用可能从单个应用程序开始,相同的销售流对于定价、报告、折扣系统以及数十个其他用例至关重要的。实际上,在全球零售业务中,有数百个甚至数千个软件系统管理着业务的核心流程,包括库存管理、仓库操作、发货、价格变动、分析及采购。有多少个核心流程受产品销售这个简单事件的影响?答案是很多或大多数,因为销售商品是零售行业中最基本的活动之一。
这是采用的良性循环。第一个应用程序带来其关键数据流。新的应用程序加入平台以访问这些数据流,并带来它们自己的数据流。数据流带来应用程序,而应用程序又带来更多的数据流。
其核心思想是,事件流可以作为已发生事件的记录加以处理,并且,任何系统或应用程序都可以实时利用它来对数据流做出反应、响应或进行处理。
这有着非常重要的意义。在公司内部,通常是一团乱麻似的相互连接的系统,每个应用程序都临时与另外一个连接。这是非常昂贵耗时的方法。事件流提供了一种替代方法:可以有一个中央平台,支持实时处理、查询和计算。每个应用程序都可以发布与其业务部分相关的流,并以完全解耦的方式依赖其他流。
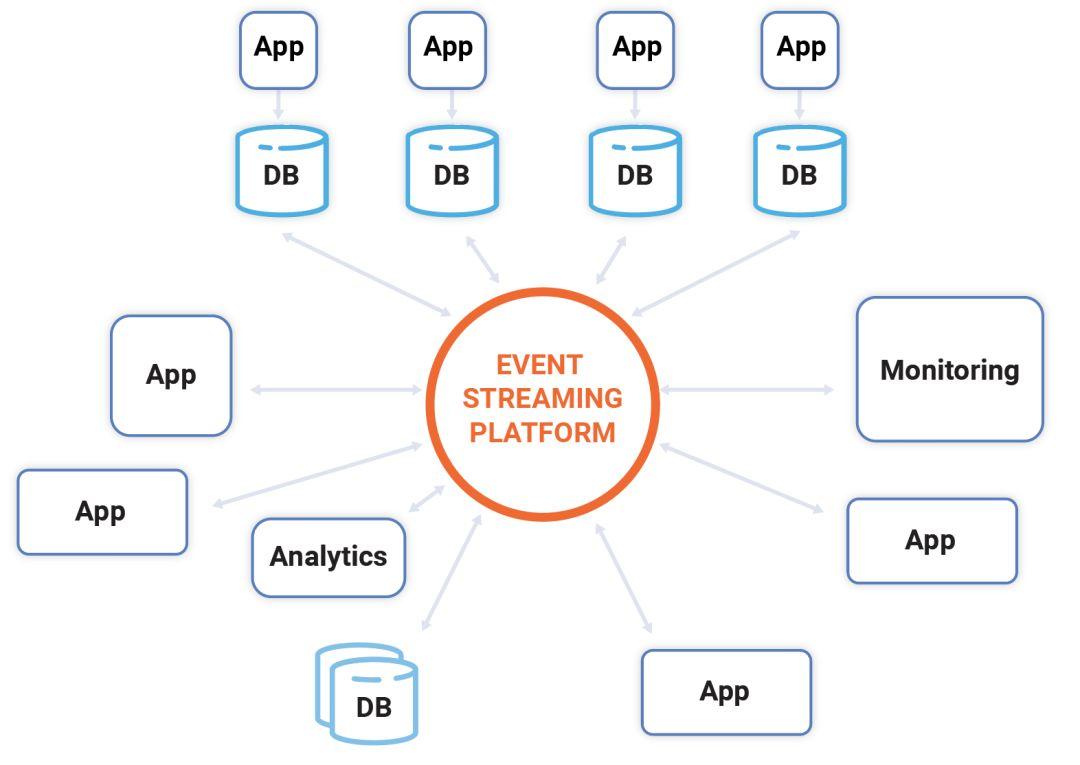
为了驱动内部连接,事件流平台充当新兴软件定义的公司的中枢神经系统。我们可以把单独的、以 UI 为中心、离线的应用程序看作一种软件世界的单细胞生物。通过很多这类单细胞动物的简单堆叠不可能形成一个综合的数字公司,就像一条狗不能从一堆没有差异的阿米巴变形虫中创造出来一样。一个多细胞动物有神经系统,协调所有单个细胞成为一个整体,可以对其在任何组成部分中所经历的任何事情做出反应、计划和即时行动。数字公司需要相当于这种神经系统的软件,以连接其所有的系统、应用程序和流程。
这让我们相信,这个新兴的事件流平台将会是现代企业中最具战略意义的单一数据平台。
事件流平台:数据库和数据流必须结合在一起
正确地做这件事不仅仅是管道胶带公司为特别集成构建的生产问题。就现状来说,这是不够的,更别说新兴的潮流了。所需的是实时数据平台,可以把数据库的全部存储和查询处理能力整合到一个现代的、水平可扩展的数据平台中。
对这个平台的需求不仅仅是对这些事件流进行读写。事件流不只是关于正在发生的事情短暂的、有损的数据喷射,它是对业务从过去到现在的过程中所发生事情的完整的、可靠的、持久的记录。为了充分利用事件流,需要一个用于存储、查询、处理和转换这些流的实时数据平台,而不只是一个短暂的事件数据的“哑巴管道”。
把数据库的存储和处理能力与实时数据结合起来似乎有点古怪。如果我们把数据库看作一种含有一大堆被动数据的容器,那么,事件流看起来离数据库的领域还很远。但是,流处理的想法颠覆了这一点。如果我们把在公司内部发生的任何东西的流看作“数据”,并允许持续“查询”对它的处理、响应和反应,会发生什么事呢?这导致了根本不同的数据库功能框架。
在传统的数据库中,数据是被动地放置的,等待应用程序或人来发出其要响应的查询。在流处理中,这个过程倒过来了:数据是持续的,活动的事件流,馈送到被动的查询中,该查询只是对数据流做出反应和处理。
在某些方面,数据库已经在内部设计中展示了其在表和事件流上的二元性,即使不是其外部特征也是如此。大多数数据库都是围绕提交日志构建的,提交日志充当数据修改事件的持久流。通常,这些日志仅仅是传统数据库中的实现细节,查询无法访问。然而,在事件流的世界,这些日志及其填充的表需要成为一等公民。
但是,集成这两件事的理由不只是基于数据库内部。基本上,应用程序是用存储在表中的数据对世界上发生的事件做出反应 。在我们的零售示例中,销售事件会影响库存事件(数据库表中的状态),从而影响重新订购事件(另一个事件!)。整个业务流程可以由这些应用程序和数据库交互的菊花链形成,创建新事件的同时也改变这个世界的状态(减少库存数量,更新余额等等)。
传统数据库只支持这个问题的一半,剩下的一半嵌入应用程序代码。KSQL 等现代流处理系统正在把这些抽象集合到一起,以开始完成数据库需要跨事件和传统存储数据表进行的操作,但是,事件与数据库的统一只是一个刚开始的运动。
Confluent 的使命
Confluent 的使命是构建这个事件流平台,帮助企业围绕这个事件流平台开始重构自身。创始人和很多早期员工甚至在公司诞生之前就已经开始为这个项目工作了,并一直工作至今。
我们构建该平台的方法是由下而上。通过帮助 Kafka 的核心可靠地进行大规模的存储、读写事件流开始。然后,我们将堆栈移到连接器和 KSQL 上,让事件流变得容易及易于使用,我们认为这对于构建新的主流开发范式是至关重要的。
我们已经在主要的公共云供应商以软件产品和完全托管的云服务形式让这个堆栈变得可用。这使事件流平台可用跨越企业运营的整个环境,并在所有环境中集成数据和事件。
整个生态系统有大量机会在这个新的基础设施上进行构建:从实时监控和分析,到物联网、微服务、机器学习管道和架构,数据移动和集成。
随着这个新的平台和生态系统的兴起,我们认为,它可以成为正在通过软件定义和执行其业务的转型公司的主要部分。随着它成长为这个角色,我认为,无论是在其范围还是战略重要性上,事件流平台将会和关系数据库平起平坐。在 Confluent,我们的目标是使之实现。
作者介绍
Jay Kreps,Confluent 的首席执行官,也是 Apache Kafka 的联合创始人之一。他曾是 LinkedIn 的资深架构师。