相比于依靠创作者手绘的动画,木偶动画的制作是个非常繁琐的过程,我们需要将一个动作分解成若干个环节,逐帧拍摄再连续放映为影片。近日,Adobe 和康奈尔大学提出了一种名为「变形木偶模板」的动画制作方法,可实现基于少量卡通角色样本生成新角色动作,和木偶动画的制作方法倒是有异曲同工之妙。
近日,Adobe 和康奈尔大学的研究人员提出一种基于学习的动画制作方法——基于卡通角色的少量图像样本就可生成新动画。
传统动画制作中,每一帧都是由创作者亲手绘制完成的,因而输入的图像缺乏共同结构、配准或标签。研究人员将动画角色的动作变化演绎为一个层级 2.5D 模板网格的变形,并设计了一种新型架构,来学习预测能够匹配模板和目标图像的网格变形,从而实现由多样化的角色动作集合中抽象出共同的低维结构。研究人员将可微渲染和网格感知(mesh-aware)模型结合起来对齐通用模板,哪怕只有少量卡通角色图像可以用来训练也没关系。
除了动作,卡通角色的外观也会因为阴影、离面运动(out-of-plane motion)和图片艺术效果而呈现细微的差异。研究人员使用图像平移网络(image translation network)来捕捉这些细微变化,并改进了网格渲染结果。他们还为了生成更高质量的卡通角色新动画搭建了一个端到端的模型,这个模型可用于合成中间帧和创建数据驱动的变形,其模板拟合(template fitting)步骤在检测图像配准方面的效果明显优于当前的通用技术。
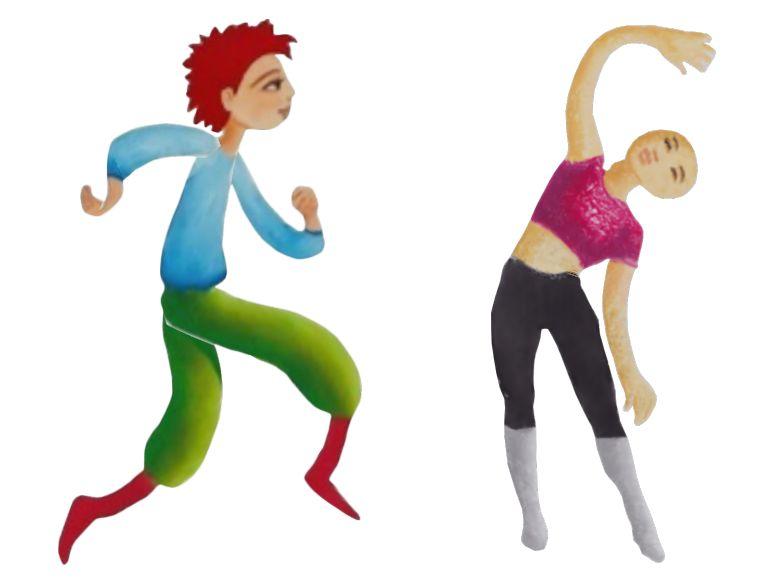
Adobe 新方法生成图像的 1024 × 1024 版本示例。
卡通角色动画制作的难点
传统的角色动画制作过程较为繁琐,需要多名创作者合力,并且要非常细致地完成每一帧动作的绘制。
在《起风了:1000日的创作记录》中,宫崎骏透露,这几秒钟的镜头耗时1年零3个月。
人类在观察多个动作序列后,很容易想象出这个角色在做其他姿势时的细节样貌,但这对于算法而言没那么容易:关节接合、艺术效果和视角变化等都会对图像外观产生大量细微差别,这些极大增加了提取底层角色结构的复杂度。人类的自然图像尚且可以依赖大量标注或数据来提取共同结构,但这种方法不适用于卡通角色,因为拓扑结构、几何和绘画风格不具备那么强的一致性。
Adobe 的解决之道
正是为了解决这一难题,Adobe 提出了一种依靠「变形木偶模板(deformable puppet template)」去基于少量图像样本生成动画角色新外观的方法。
研究人员先假设所有的角色姿势都可以通过扭曲变形模板来生成,开发出一个变形网络(deformation network),以及这个网络编码图像和解码模板的变形参数;然后在可微渲染层中使用这些参数,渲染出与输入帧相匹配的图像。重建损失可在所有阶段中进行反向传播,从而学习如何对所有训练帧登记该模板。
不过,渲染结果的姿势虽然合理,但这个结果相对于创作者绘制成的图像还是有些逊色,因为它们仅仅扭曲了一个参考输入,没有捕捉到阴影、艺术效果等因素造成的轻微外观差别。为了进一步改善渲染结果的视觉质量,研究人员使用图像平移网络来合成最终外观。
这项研究用到的是学界和工业界常用的层级 2.5D 变形模型(layered 2.5D deformable model),再匹配上多种传统人工绘制动画风格。如此一来,相对于需要大量专业知识才能使用的 3D 建模模板,用户会轻松许多。假如用户想生成木偶,选择单个帧,再将前景角色分割成多个身体构成组件,然后就可以使用标准三角剖分(triangulation)工具将其转化为网格。
在六个动画角色的制作任务中,研究人员使用 70%-30% 的训练-测试分割比例去评估了这个新方法:
首先,评估模型重建输入帧的效果,发现其输出的结果比当前最优的光流和自编码器技术更加准确。
其次,评估登记模板(registered template)估计出的配准质量,发现其效果优于图像配准方法。
最后,证明该模型可用于数据驱动的动画制作,即合成动画帧由训练时获取的角色外观决定。研究人员构建了合成中间帧和根据用户指定变形制作动画的原型应用,根据角色生成合理变形后的新图像。相比于计算机图形学基于能量的传统优化技术,这一数据驱动方法得到的角色姿势更加逼真,也更加接近创作者绘画水准。
方法
这项研究的目标是学习一个变形模型,基于一组无标注图像集合生成卡通角色。首先,用户通过分割一个参考帧来创建层级变形模板木偶;然后训练一个两阶神经网络:第一阶段学习如何扭曲木偶模板来重新设计角色外观,从而将变形木偶与输入序列中的每一帧进行匹配;第二阶段改进变形木偶的渲染结果,实现上个 2D 扭曲阶段无法呈现的纹理变化和动作效果。
层级变形木偶
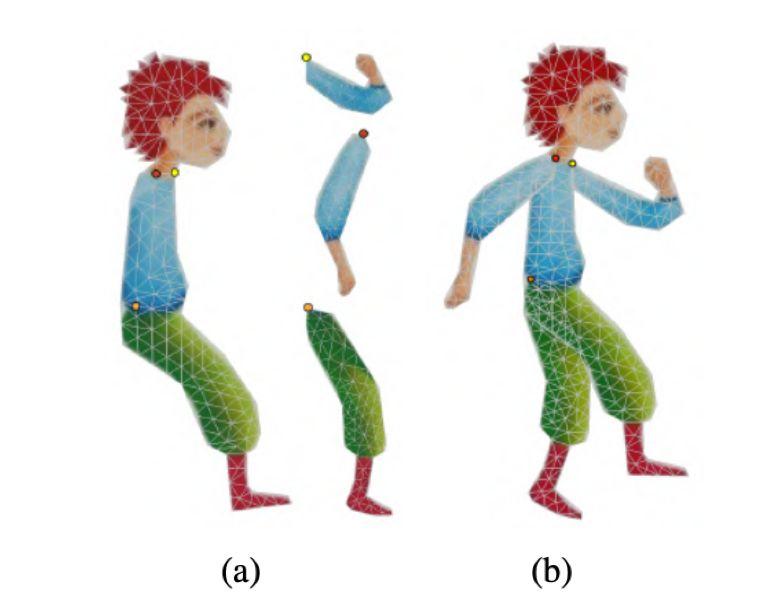
图 1:变形木偶。a)为每一个身体部位创建单独的网格,并标记关节(见图中圆圈);b)将这些网格连接起来,最终网格的 UV 图像包括分割纹理图的平移版本。
与 3D 建模不同,层级 2D 木偶的使用方法要简单得多,即使没有经验的用户也可以使用。首先,用户选择一个参考帧,提供不同身体部位及其顺序的轮廓,然后用标准三角剖分算法为每个部位生成网格,并在两个部位重叠区域的质心处创建关节点;之后运行中间点网格细分(midpoint mesh subdivision),就可以调整更多细节,得到更加精细的网格了。
变形网络
获得变形网络模板后,就可以学习如何使模板变形以匹配目标角色图像的新姿势了。
图 2 展示了训练架构:
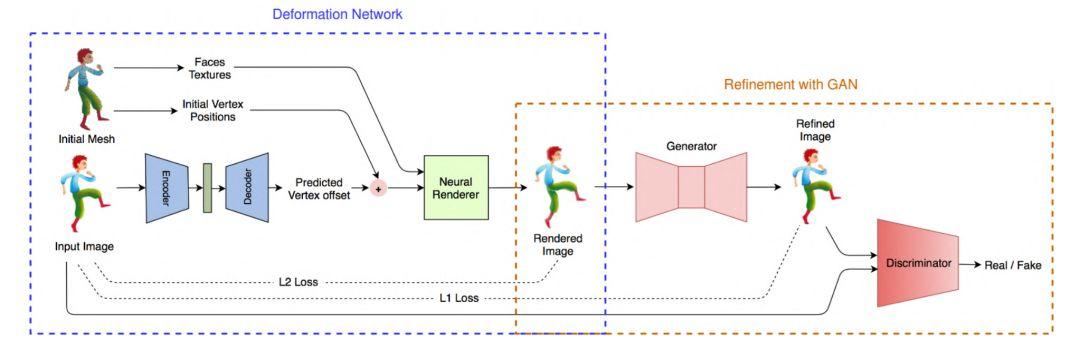
图 2:训练架构。编码器-解码器网络学习网格变形,条件生成对抗网络改进渲染图像,以捕捉纹理变化。
变形网络的输入指的是初始网格和使用新姿势的目标角色图像,编码器-解码器网络通过卷积滤波器将目标图像编码至瓶颈层,然后通过全连接层将其解码为顶点位置偏移(vertex position offset)。这样一来,网络就能够识别输入图像中的姿势,并推断出生成这一姿势的合适模板变形。
外观改进网络
尽管变形网络可以捕捉到大部分关节,但还是有一些细微的外观效果变化(如艺术风格、阴影效果和离面运动)无法通过以上步骤来实现。
所以研究人员跟进推出了「外观改进网络」,对变形得到的图像再进行细化处理。该架构和训练步骤类似于条件生成对抗网络。生成器对渲染图像进行精细处理,使其更加自然贴合。
实验结果及应用

图 3:输入图像、Adobe 方法的渲染结果和最终结果,以及 PWC-Net [55] 和 DAE [52] 的结果。(输入图像中前三个角色由 Zuzana Studena 绘制,第四个角色由 Adobe Character Animator 绘制。)
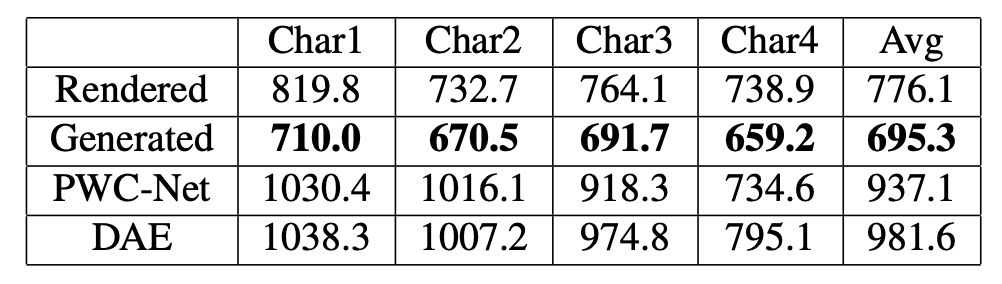
表 1:目标图像和生成图像之间的平均 L2 距离。该表展示了 Adobe 方法的渲染图像和生成图像与 PWC-Net [55]、Deforming Autoencoders [52] 的对比结果。最后一列表示六个不同角色的平均 L2 距离。
图 4:将 Adobe 方法的输出结果渲染为 1024 × 1024 图像的示例。