今天的文章,咱们会通过图的方式,来深入学习和理解分布式一致性的实现原理。
开始的时候,咱们先来灵魂一问:什么是分布式一致性?
- 你的应用是单节点吗?
- 你的系统用户多吗、支持扩容吗?
- 你的系统扩容后数据能保持一致吗?
- 你的系统是否使用Raft、Paxos?
- ……
是否理解都没关系,后面开始咱们的例子,通过图的方式,来描述一致性的工作原理。
一、前奏
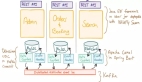
假设咱们有个系统。是个单节点的系统,只部署在一个实例上。可以把它理解成一个数据库服务(Database Server),实例上只有一个数据X,咱们后续的故事都是要围绕操作变更X的值开展的。
咱们还有个客户端(Client),它要向节点 (Server) 写数据,这个时候应用代码写起来也简单,这个数据的一致性很容易保证。


写请求执行后,客户端和服务端的X数据都变成了8。
在用户量少的时候,还天天操心啥时候来个百万千万用户,等用户稍微一多起来才发现,原来的一个实例扛不住了。这个时候为了支持更多用户访问,又扩容出来了更多的实例。

那么这下问题来了,当我们有多个实例节点间的时候,客户端向其中一个节点写了数据,如何再同步给其他节点呢?怎样保证节点间数据的一致性呢?这就是分布式一致性问题。
二、 Raft 协议概览
Raft 就是一个解决上述分布式一致性问题的协议。类似的协议还有Paxos、Zab等等。相比 Paxos,Raft 更易理解和实现。
咱们本次会俯瞰 Raft , 来了解其工作原理。
在 Raft 里, 节点可能存在三种状态:
- Follower
- Candidate
- Leader
在后面的图里内容中,上述三种状态分别和下面三个图一一对应。
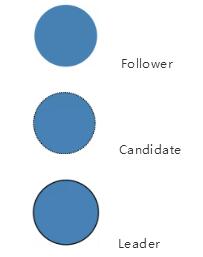
任何时候,都只会处于上述三种状态中的一种。初始时候,所以节点都处于 Follower状态。

如果follower 节点不再能接收到 leader 节点的消息, 他们的状态就会变成 Candidate。

Candidate 节点会向其他节点发起投票请求,

其他节点也会投票进行响应。

如果获得了多数节点的投票,那 Candidate节点会成为Leader。

上面的这个过程就是分布式一致性协议中的「选举」(Leader Election)。
后续所有对于系统的变更,都是通过Leader进行的。经由 Leader 再到达其他节点。
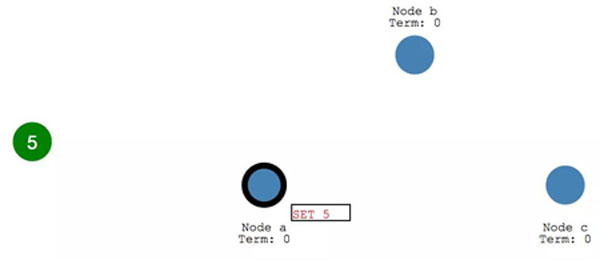
每次 Client 的变更请求到达 leader 时,都会视为一个 Entry ,先添加到节点的日志 (Log)里。这个新增的 log entry,目前还并没有提交,所以不会真的更新节点里 X 的值。

leader 首先会复制 log entry 给所有 follower节点。

然后, leader 会等待,直到多数节点都写入了entry。

在收到多数节点的写入响应之后, leader 节点会将 entry 提交,此时 leader节点的值变成了 5.
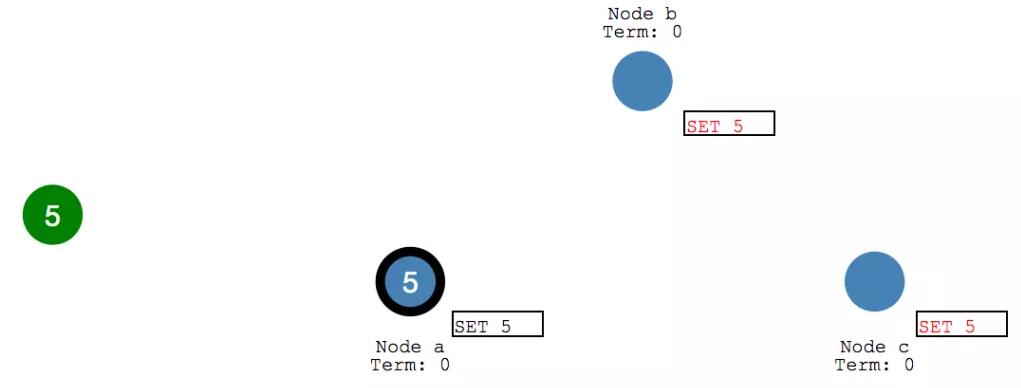
然后 leader 会通知 follower 节点 自己的 entry 已经提交了。

此时各个 follower 节点也会将之前收到的entry 进行提交。

整个系统目前所有的集群节点都达到了一致的状态。这个过程一般称为日志复制(Log Replication)。
三、 Leader Election
Raft 里有项控制选举的超时时间设置。选举超时时间是一个follower变成 candidate 的等待时间。值是150ms到300ms间的一个随机值.

在选举超时后, follower 会变成 candidate 开始一个新的选举周期(term),同时会给自己投一票。

并且给其他节点发送请求投票的消息。

如果收到消息的节点在这一个周期还没有投过票,那他需要给 candidate 投一票,并且该节点重置他的选举超时时间。

如果 candidate 收到大多数节点的投票,就会成为leader。

leader 此时会在心跳检测的周期内,给给所有的follower发送Append Entries messages 。检测的频率是通过心跳超时时间设置的。

然后 每个 follower 也会给 Append Entries message 发送响应。

这个选举周期会一直持续直到某个 follower 停止心跳消息接收变成 candidate。

我们停掉 leader 再来看一下重新选举的情况。
此时 节点 B 已经停止,所以 节点A 和节点C 都收不到心跳消息。咱们前面说收不到心跳消息的话,节点的状态会从 Follower 变成 Candidate,所以A 和C 在各自的选举超时时间设置内会改变状态,

此时,节点 A 和 节点 C 都在等待,由于节点C先超时,所以会先开始一轮选举。和上面的选举过程一样,会先新增Term,给自己投一票,并发送投票请求给其他节点。
在收到节点A的投票后,节点C现在升级为 term 2的 leader。

咱们前面总在说的「大多数节点投票」(a majority of votes)。这个能保证能在一个投票周期内,只会产生一个 leader。
假设两个节点同时从 Follower 状态变成了 Candidate,这个时候两者都会升级 Term,并请求其他节点不给自己投票。


这个时候两者的 Term 其实是相同的,在同一个 Term 内 其他节点只会投出一票,所以每个 Candidate 都只会收到一个节点的投票。


因为没有超过「大多数」,所以都会不能成为 leader。这些节点就会等待新一轮的选举,此时节点D先开始发起投票,并收到了大多数的投票,所以在Term 5 最终成为 leader。

四、 Log Replication
在选举出一个leader之后,就需要复制所有的变更信息到系统里的所有节点。这些是通过和心跳检测相同的的Append Entries message 来完成的。

我们来看下这个过程。一开始, client会向leader发送一个变更。

这个变更会加到 leader的log中,并会在下一次心跳检测的时候发给 follower。

follower在收到消息之会,都会给 leader 发送响应的 ack消息。

收到大多数的 follower 响应之后, leader 会提交这个entry,并且发送响应给 client。


并在下次心跳的时候,通知 follower 们执行提交操作。

follower 在写入完成后再给 leader 发送响应。
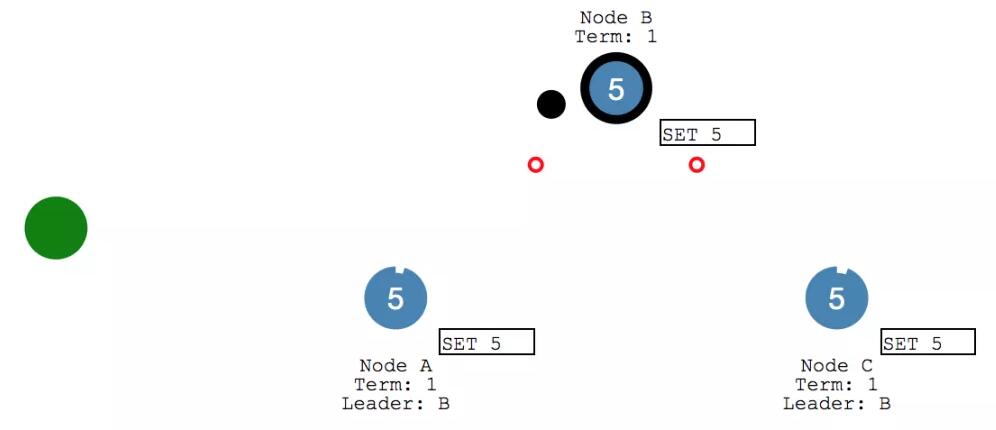
此时 Client 又给给 leader 发送消息,要给X 来执行个 加2 的操作。leader 将消息添加到 log 之后,给各个follower 发送心跳。
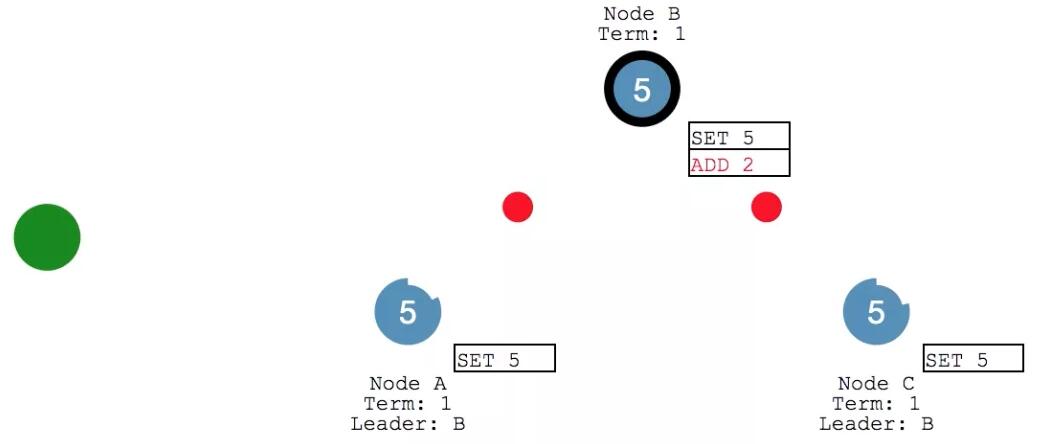
follower 们收到之后继续返回响应。
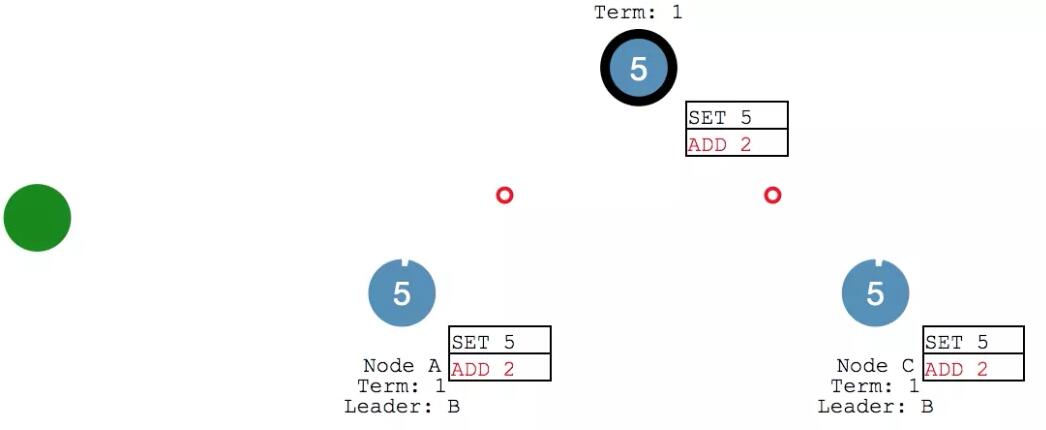
leader 收到 ack 之后,确认本次执行进行 commit ,然后给 client 发回响应。并在下次心跳的时候,把写入发给各个 follower。
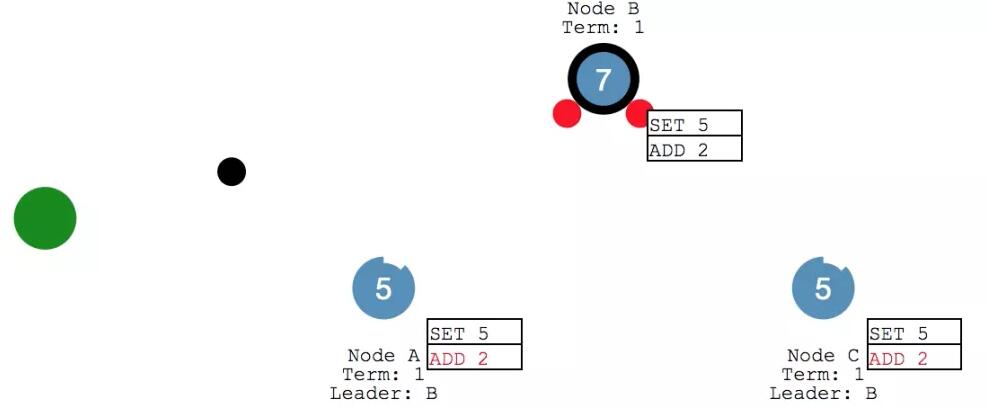
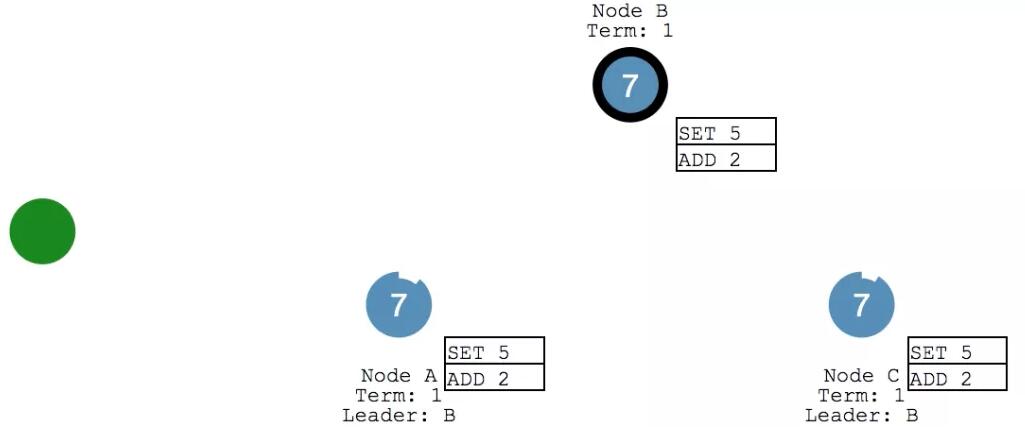
此时,咱们的系统里 X变成了7,各个节点的数据保持一致。
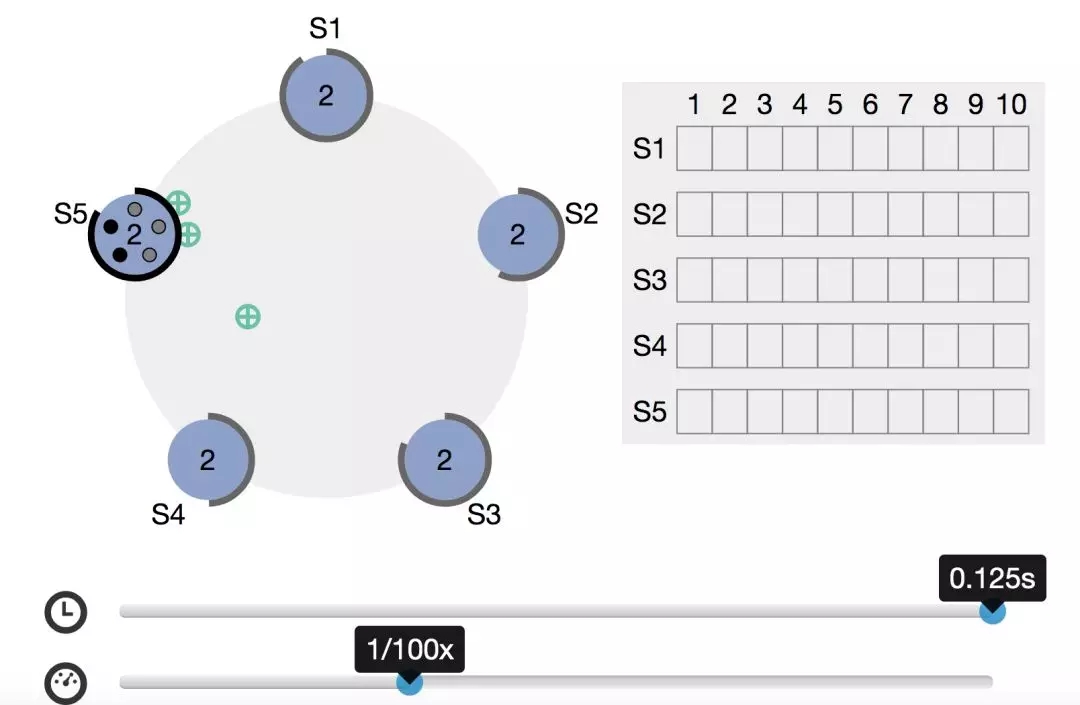
五、「大多数」是多少?
前面许多场景咱们都提到「大多数」。那大多数到底是多少呢?
比如我们在选举的时候,在日志复制的时候,都需要大多数 follower 发送回响应消息。
这里的大多数和咱们日常生活里的基本一致,即超过半数。比如一共有5个节点,此时有一个 candidate 起成为 leader,在投票过程中,至少要收到3个投票才行。
官网有个可以自定义时间进行交互的动图,感兴趣的朋友可以自行查看。
【本文为51CTO专栏作者“侯树成”的原创稿件,转载请通过作者微信公众号『Tomcat那些事儿』获取授权】