电池寿命的确定,是移动硬件发展的重要一环,但是由于电池电化学反应的不确定性以及不同的使用环境和习惯,电池寿命变成了一门玄学。
不过柏林的三位小伙伴,利用Tensorflow,在原有的预测体系基础上。更近一步,完成了电池的全寿命预测。
捋清数据
研究者在原始模型中,统计了124块锂电池的充放电循环次数中的数据作为寿命指标。
简单来说,从完全充满电到完全放光电是一个循环,当循环的次数多到锂电池只能容纳以前电量的80%时,电池寿终正寝。
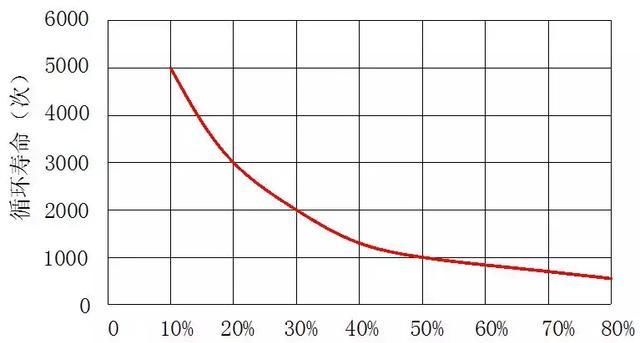
研究中统计的电池循环次数从150到2300,差异巨大。
但是这个过程中的数据不仅只是记数,过程中输入的连贯充电循环可以作为窗口,每个窗口有一个“当前循环数”和“剩余循环次数”。除此之外,每个窗口有一个目标值,这个目标值以最后循环的特征值为准。
在每个电池循环周期中,电池的电压,电流,温度,电荷的动态变化也需要统计。并且还会出现像内阻,电荷量,通电时间等定量数据。
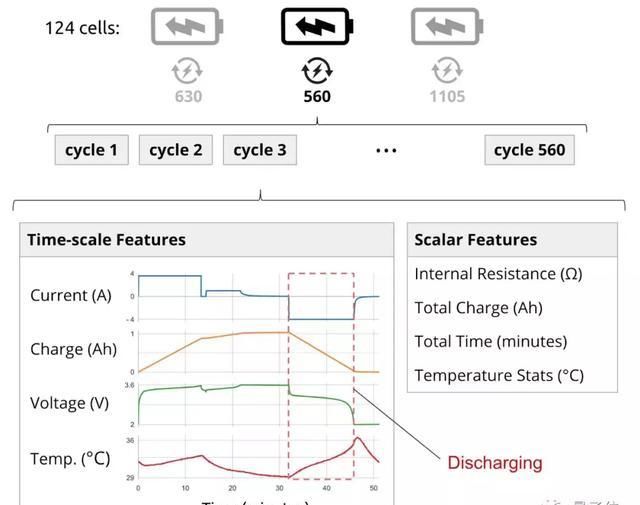
之前说过,入选研究的电池,通电循环的次数各不相同。
有的循环多,有的循环少,那跟时间变化相关的数据就不好统一。毕竟循环了几千次电池的电流,不能跟刚用两三次就超龄报废的电池电流做对比。
针对这个问题,研究者首先以放电时电池的电压变化范围代替时间作为变化量的参考基准。
因为电池的电压范围都是一样的,这就有了同步的参考范围。之后插补随电压变化的电荷量和温度值,最后给以电压为基准,划分量程,就能进行完整的数据参照了。
构建模型
虽然数据详细清晰,但是数组和标量数据显然不能简单塞进一个模型里。
研究者利用Keras functional API作为构建模型的工具,对数组数据和标量数据分开导入。
对于数组数据,他们将其与窗口的特征数据,例如窗口大小,长度,特征值数量相结合,形成三维矩阵。
之后在保证窗口的连续性基础上,利用Maxpooling处理,将矩阵分为三个Conv2D函数图层。
通过这个方式便可以提取出有相关性的信息,之后再把上述数据降维成一维数组。在数据都享有同一个变化范围,并且高度相关的前提下。
Conv2D扮演的角色,就像图片中代表颜色通道的数字一样,代表着数据的特征。
标量数据的导入流程也与之类似,不过只需要从二维降到一维就可以了。
经过处理后的两个具有特征映射的平面数组,就像处理好的食材一样,可以放心的做出模型需要的密集网络这盘大菜了。
训练优化
万事俱备,就差练手。
研究者撰写了一个指令集操作界面,从而方便进行训练的相关操作。
- ./train.sh
如果需要调整训练的epoch和窗口中样本的数量,只需要输入这个指令:
- ./train.sh -e 70 -w 10
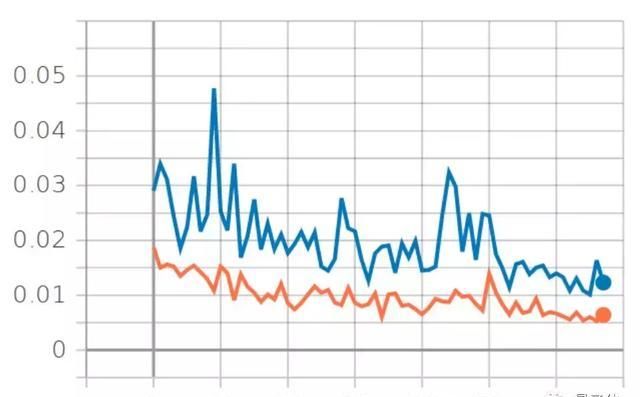
将训练值和验证值的数据趋势对比可以看出,在平均绝对偏差方面,二者的差距在逐步缩小,曲线走势也在逐步接近。
为了缩小模型与验证值的差距,研究者选择加入Dropout工具进行进一步的拟合。
除此之外,研究者还需要对模型进行超参数调优,因此研究者对不同设置采用了网格搜索。
那么如何跟踪这些设置呢?这时候Tenserflow2.0的hparams module派上了用场。
经过这一系列操作之后,研究者就可以比较出拟合过程中最关键的参数了。
由于准确预测结果要求“当前循环”和“剩余循环数”都要大于零。研究者使用了ReLU作为输出层的启动机制,这可以降低训练过程中模型的搜索范围,节约时间。
由于研究者的模型依赖CNN,所以他们尝试了不同的核心大小,最后在两种不同的学习速率前提下比较了不同设置下当前循环和剩余循环的MAE值。
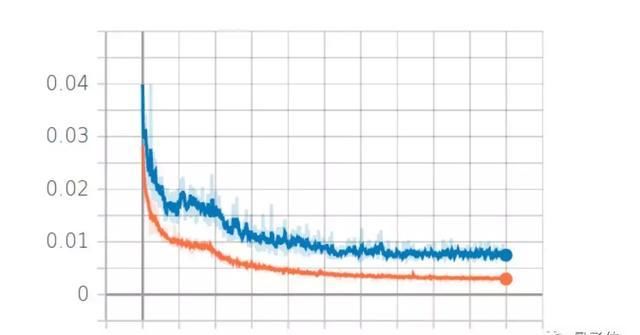
△误差值对比
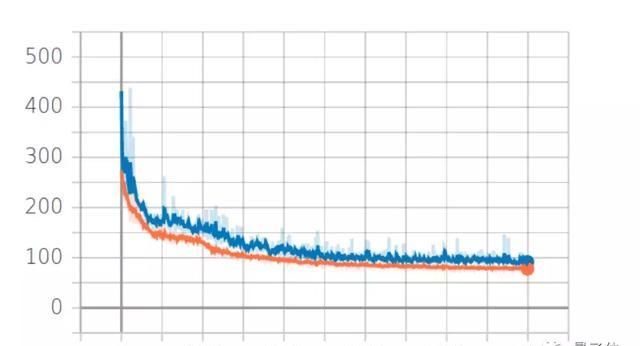
△当前循环的MAE值对比
△剩余循环的MAE值对比
经过超参数调优后的最佳配置模型,在训练epoch上千的基础上,当前循环MAE为90.剩余循环MAE为115。虽说不算完美,不过对于研究者的应用方面预期来说,这个结果很不错。
预测上线
实际上曲线上可以看出。模型预测差距最小的位置,并不是训练终点,而是训练大概四分之三的时候。所以在研究者在这个分界点加入了检查点,从而重置模型来避免多次训练带来的偏差。
模型已经大功告成了,现在就可以尝试把结果转换成曲线,之后就可以上线应用了。
目前包括当前循环和剩余循环的输出曲线大概是这样的。
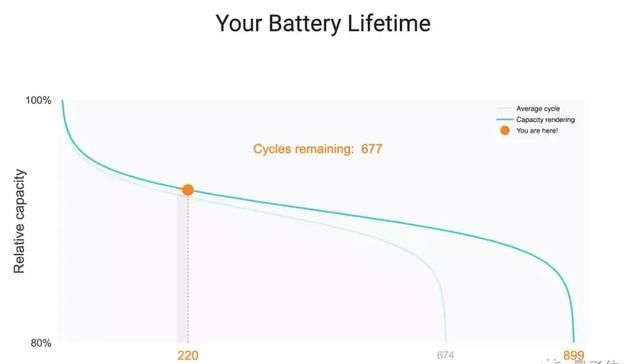
虽说对电池来说这有点“大限将至”的味道,但是对于用户而言,这确实是一个不错的进步。
现实的电池寿命预测,只是在原有电池容量的基础上对电池容量的变化进行大致参考。这样的评估模式,并没有考虑到不同的使用环境以及用户的使用习惯。
因为从低温到高温使用环境,从24小时插充电线到三天不开屏幕锁,电池的循环次数必然会产生差异,这还没有考虑不同批次电池的制造差异。因此这种模糊的估测并不能准确的表达电池的真正寿命。
而这个电池寿命预测模型,随着不同环境下电池寿命相关数据的丰富,可以为用户提供一个更为精准的使用参考。
至少它能提醒你,啥时候该换手机了。