作为法医,不怕高度腐烂的尸体,也不怕错综复杂的案情。最怕的,是没留下任何东西。空无一物,任何高超的技术,丰富的经验,都无从下手。
生产环境错综复杂,几分钟前活蹦乱跳的进程,此刻就奄奄一息的躺在那里,苟延残喘。作为第一时间发现的目击者,一定要注意保存好现场。有时,最坏的情况就是引火上身,纠缠不清,这都是我们不愿看到的。
在进程的生命烟消云散之前,我们还有很多事要做。本篇文章,将介绍常用的保留线索方法。最后,将这个过程,使用Shell脚本自动化。
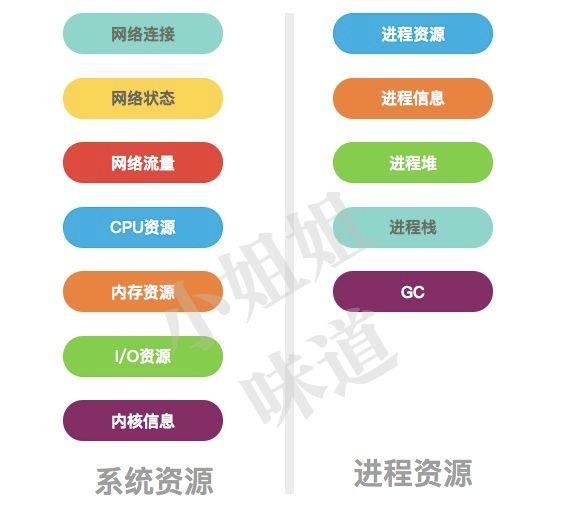
系统环境,不说谎的案发现场
1、系统当前网络连接
ss -antp > $DUMP_DIR/ss.dump 2>&1
- 1.
本命令将系统的所有网络连接输出到ss.dump文件中。使用ss命令而不是netstat的原因,是因为netstat在网络连接非常多的情况下,执行非常缓慢。
后续的处理,通过查看各种网络连接状态的梳理,来排查TIME_WAIT或者CLOSE_WAIT,或者其他连接过高的问题,非常有用。
2、网络状态统计
netstat -s > $DUMP_DIR/netstat-s.dump 2>&1
- 1.
将网络统计状态,输出到netstat-s.dump文件中。它能够按照各个协议进行统计输出,对把握当时整个网络状态,有非常大的作用。
sar -n DEV 1 2 > $DUMP_DIR/sar-traffic.dump 2>&1
- 1.
上面这个命令,会使用sar输出当前的网络流量。在一些速度非常高的模块上,比如redis、kafka,就经常发生跑满网卡的情况。
3、进程资源
lsof -p $PID > $DUMP_DIR/lsof-$PID.dump
- 1.
这是个非常强大的命令。可以查看进程打开了哪些文件,这是一个神器,可以以进程的维度查看整个资源的使用情况。这个命令在资源非常多的情况下,输出稍慢,耐心等待。
4、CPU资源
mpstat > $DUMP_DIR/mpstat.dump 2>&1
vmstat 1 3 > $DUMP_DIR/vmstat.dump 2>&1
sar -p ALL > $DUMP_DIR/sar-cpu.dump 2>&1
uptime > $DUMP_DIR/uptime.dump 2>&1
- 1.
- 2.
- 3.
- 4.
这几个命令,我们在
《Linux之《荒岛余生》(二)CPU篇》
这篇文章,已经有了比较详细的介绍。主要输出当前系统的CPU和负载,便于事后排查。
这几个命令的功能,有不少重合,使用者要注意甄别。
5、I/O资源
iostat -x > $DUMP_DIR/iostat.dump 2>&1
- 1.
一般,以计算为主的服务节点,I/O资源会比较正常。但有时候也是会发生问题的,比如日志输出过多,或者磁盘问题等。此命令可以输出每块磁盘的基本性能信息,用来排查I/O问题。
6、内存问题
free -h > $DUMP_DIR/free.dump 2>&1
- 1.
内存问题较为复杂,有兴趣可以看下xjjdog堆外内存排查小结这篇文章。一般发生的问题是JVM内存溢出,我们在进程小节说明。
free命令能够大体展现操作系统的内存概况,是故障排查中一个非常重要的点。
7、其他全局
ps -ef > $DUMP_DIR/ps.dump 2>&1
dmesg > $DUMP_DIR/dmesg.dump 2>&1
sysctl -a > $DUMP_DIR/sysctl.dump 2>&1
- 1.
- 2.
- 3.
在xjjdog的其他文章,我们不止一次说到dmesg。dmesg是许多静悄悄死掉的服务留下的最后一点线索。
当然,ps作为执行频率最高的一个命令,它当时的输出信息,也必然有一些可以参考的价值。
由于内核的配置参数,会对系统产生非常大的影响。所以我们也输出了一份。
进程快照,最后的遗言
1、jinfo
${JDK_BIN}jinfo $PID > $DUMP_DIR/jinfo.dump 2>&1
- 1.
此命令将输出java的基本进程信息。包括环境变量和参数配置。
2、gc信息
${JDK_BIN}jstat -gcutil $PID > $DUMP_DIR/jstat-gcutil.dump 2>&1
${JDK_BIN}jstat -gccapacity $PID > $DUMP_DIR/jstat-gccapacity.dump 2>&1
- 1.
- 2.
jstat将输出当前的gc信息。一般,能大体看出一个端倪,如果不能,将借助jmap进行分析。
3、堆信息
${JDK_BIN}jmap $PID > $DUMP_DIR/jmap.dump 2>&1
${JDK_BIN}jmap -heap $PID > $DUMP_DIR/jmap-heap.dump 2>&1
${JDK_BIN}jmap -histo $PID > $DUMP_DIR/jmap-histo.dump 2>&1
${JDK_BIN}jmap -dump:format=b,file=$DUMP_DIR/heap.bin $PID > /dev/null 2>&1
- 1.
- 2.
- 3.
- 4.
jmap将会得到当前java进程的dump信息。如上所示,其实最有用的就是第4个命令,但是前面三个能够让你初步对系统概况进行大体判断。
因为,第4个命令产生的文件,一般都非常的大。而且,需要下载下来,导入MAT这样的工具进行深入分析,才能获取结果。
4、执行栈
${JDK_BIN}jstack $PID > $DUMP_DIR/jstack.dump 2>&1
- 1.
jstack将会获取当时的执行栈。一般都会多次取值,我们这里取一次即可。这些信息非常有用,能够还原你的java进程中线程情况。
top -Hp $PID -b -n 1 -c > $DUMP_DIR/top-$PID.dump 2>&1
- 1.
为了能够得到更加精细的信息,我们使用top命令,来获取进程中所有线程的cpu信息。这样,就可以看到资源到底是耗费在什么地方。
5、高级替补
kill -3 $PID
- 1.
有时候,jstack并不能够运行。有很多原因,比如java进程几乎不响应了。我们会尝试向进程发送kill -3信号。这个信号是java进程享有的,将会打印jstack的trace信息到日志文件中。是jstack的一个替补方案。
gcore -o $DUMP_DIR/core $PID
- 1.
对于jmap无法执行的问题,也有替补,那就是GDB组件中的gcore。将会生成一个core文件。我们可以使用如下的命令去生成dump
${JDK_BIN}jhsdb jmap --exe ${JDK}java --core $DUMP_DIR/core --binaryheap
- 1.
瞬时态和历史态
xjjdog这里创建两个名词。瞬时态是指当时发生的,快照类型的元素;历史态是指按照频率抓取的,有固定监控项的资源变动图。
上面有很多信息,比如CPU,比如系统内存等,瞬时态的价值就不如历史态来的直观一些,因为它还存在一个基线问题。所以如果有监控系统一类的工具,将美好的多。
但对于lsof,heap等,这种没有时间序列概念的混杂信息,无法进入监控系统,产生有用价值,就只能够通过瞬时态进行分析。这种情况下,瞬时态的价值反而更大一些。
我已经把上面的过程,写成了一个shell脚本。你可以在github上找到它。点击左下角的查看原文,也能和它见面。
https://github.com/sayhiai/shell
但值得注意的是,分布式环境的故障原因,往往会出乎意料,你的这份单机证据,可能就只是一个表象。它没有说谎,但它背后的意义,往往对问题本质进行了错误的引导。