1.相关和因果是一回事吗
相关性不等于因果。用x1和x2作为两个变量进行解释,相关意味着x1和x2是逻辑上的并列相关关系,而因果联系可以解释为因为x1所以x2(或因为x2所以x1)的逻辑关系,二者是完全不同的。
用一个运营示例来说明二者的关系:做商品促销活动时,通常都会以较低的价格进行销售,以此来实现较高的商品销量;随着商品销售的提升,也给线下物流配送体系带来了更大的压力,在该过程中通常会导致商品破损量的增加。
本案例中,商品低价与破损量增加并不是因果关系,即不能说因为商品价格低所以商品破损量增加;二者的真实关系是都是基于促销这个大背景下,低价和破损量都是基于促销产生的。
相关性的真实价值不是用来分析“为什么”的,而是通过相关性来描述无法解释的问题背后真正成因的方法。相关性的真正的价值是能知道“是什么”,即无论通过何种因素对结果产生影响,最终出现的规律就是二者会一起增加或降低等。
仍然是上面的案例,通过相关性分析我们可以知道,商品价格低和破损量增加是相伴发生的,这意味着当价格低的时候(通常是做销售活动,也有可能产品质量问题、物流配送问题、包装问题等),我们就想到破损量可能也会增加。但是到底由什么导致的破损量增加,是无法通过相关性来得到的。
2.相关系数低就是不相关吗
R(相关系数)低就是不相关吗?其实不是。
R的取值可以为负,R=-0.8代表的相关性要高于R=0.5。负相关只是意味着两个变量的增长趋势相反,因此需要看R的绝对值来判断相关性的强弱。
即使R的绝对值低,也不一定说明变量间的相关性低,原因是相关性衡量的仅仅是变量间的线性相关关系,变量间除了线性关系外,还包括指数关系、多项式关系、幂关系等,这些“非线性相关”的相关性不在R(相关性分析)的衡量范围之内。
3.代码实操:Python相关性分析
本示例中,将使用Numpy进行相关性分析。源文件data5.txt位于“附件-chapter3”中。附件下载地址:
http://www.dataivy.cn/book/python_book_v2.zip
- import numpy as np # 导入库
- data = np.loadtxt('data5.txt', delimiter='\t') # 读取数据文件
- x = data[:, :-1] # 切分自变量
- correlation_matrix = np.corrcoef(x, rowvar=0) # 相关性分析
- print(correlation_matrix.round(2)) # 打印输出相关性结果
示例中实现过程如下:
- 先导入Numpy库;
- 使用Numpy的loadtxt方法读取数据文件,数据文件以tab分隔;
- 矩阵切片,切分出自变量用来做相关性分析;
- 使用Numpy的corrcoef方法做相关性分析,通过参数rowvar = 0控制对列做分析;
- 打印输出相关性矩阵,使用round方法保留2位小数。结果如下:
- [[ 1. -0.04 0.27 -0.05 0.21 -0.05 0.19 -0.03 -0.02]
- [-0.04 1. -0.01 0.73 -0.01 0.62 0. 0.48 0.51]
- [ 0.27 -0.01 1. -0.01 0.72 0. 0.65 0.01 0.02]
- [-0.05 0.73 -0.01 1. 0.01 0.88 0.01 0.7 0.72]
- [ 0.21 -0.01 0.72 0.01 1. 0.02 0.91 0.03 0.03]
- [-0.05 0.62 0. 0.88 0.02 1. 0.03 0.83 0.82]
- [ 0.19 0. 0.65 0.01 0.91 0.03 1. 0.03 0.03]
- [-0.03 0.48 0.01 0.7 0.03 0.83 0.03 1. 0.71]
- [-0.02 0.51 0.02 0.72 0.03 0.82 0.03 0.71 1. ]]
相关性矩阵的左侧和顶部都是相对的变量,从左到右、从上到下依次是列1到列9。从结果看出:
- 第5列和第7列相关性较高,系数达到0.91。
- 第4列和第6列相关性较高,系数达到0.88。
- 第8列和第6列相关性较高,系数达到0.83。
为了更好地展示相关性结果,我们可以配合Matplotlib展示图像。代码如下:
- fig = plt.figure() # 调用figure创建一个绘图对象
- ax = fig.add_subplot(111) # 设置1个子网格并添加子网格对象
- hot_img = ax.matshow(np.abs(correlation_matrix), vmin=0, vmax=1)
- # 绘制热力图,值域从0到1
- fig.colorbar(hot_img) # 为热力图生成颜色渐变条
- ticks = np.arange(0, 9, 1) # 生成0~9,步长为1
- ax.set_xticks(ticks) # 生成x轴刻度
- ax.set_yticks(ticks) # 设置y轴刻度
- names = ['x' + str(i) for i in range(x.shape[1])] # 生成坐标轴标签文字
- ax.set_xticklabels(names) # 生成x轴标签
- ax.set_yticklabels(names) # 生成y轴标签
上述代码的功能都已经在注释中注明。有以下几点需要注意:
- 由于相关性结果中看的是绝对值的大小,因此需要对correlation_matrix做取绝对值操作,其对应的值域会变为[0, 1]。
- 原始数据中由于没有列标题,因此这里使用列表推导式生成从x0到x8代表原始的9个特征。
展示结果如图所示。
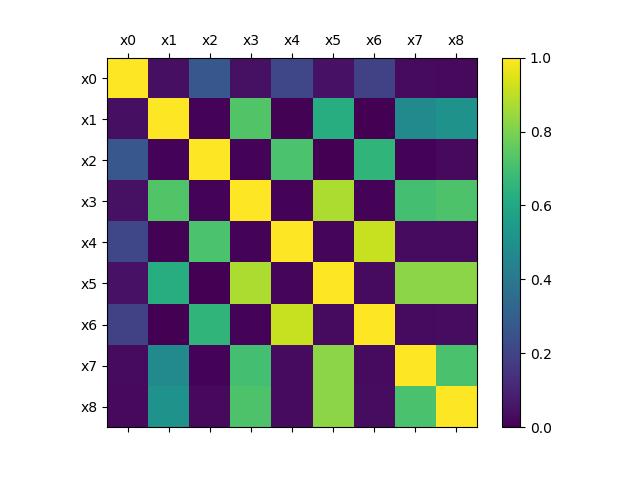
从图像中配合颜色可以看出:颜色越亮(彩色颜色为越黄),则相关性结果越高,因此从左上角到右下角呈现一条黄色斜线;而颜色较亮的第5列和第7列、第4列和第6列及第8列和第6列分别对应x4和x6、x3和x5、x7和x5。
上述过程中,主要需要考虑的关键点是:如何理解相关性和因果关系的差异,以及如何应用相关性。相关性分析除了可以用来分析不同变量间的相关伴生关系以外,也可以用来做多重共线性检验。
代码实操小结:本节示例中,主要用了如下几个知识点。
- 通过Numpy的loadtxt方法读取文本数据文件,并指定分隔符;
- 对Numpy矩阵做切块处理;
- 使用Numpy中的corrcoef做相关性分析;
- 使用round方法保留2位小数;
- 使用np.abs取绝对值;
- 使用列表推导式生成新列表;
- 使用Matplotlib的热力图配合相关性结果做图像展示。