












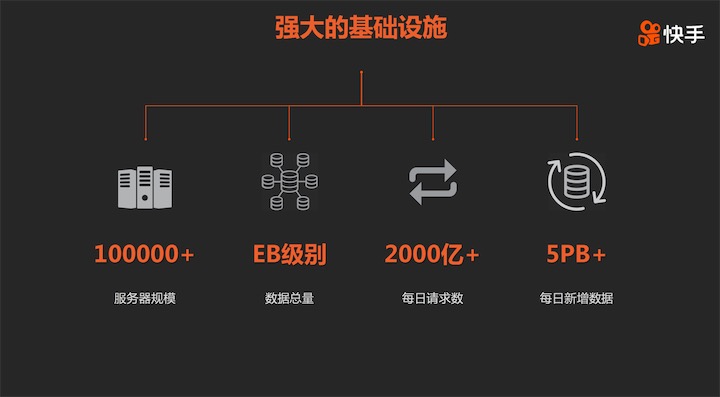
日活超过2亿的快手,库存短视频超过130亿条,仍以每日超过1500万条短视频上传的速度新增,拥有海量超大数据应用场景。快手基础设施的规模已经处于国内互联网公司头部行列。目前快手服务器规模已经超过十万台,数据总量达到EB级别,每天新增数据超过5PB。
为保障千亿级别数据量的处理和基础设施稳定、高效运行,快手服务器选型和业务优化团队(以下简称“快手SAT团队”)选用合作伙伴英伟达新一代图灵架构的TESLA T4/V100,在业内率先完成计算架构的全新升级。
据了解,快手SAT团队的成员经验丰富,人均工作经验在10年左右,专注于硬件方面的成员大多来自于海内外大型服务器或者硬件厂商,专注于软件方面的成员大多数来自国内头部互联网企业。正是这样的一个软硬结合的团队,给快手超过2亿 的日活量级提供了坚实的保障。
据快手SAT团队研发人员介绍,快手大数据应用场景如视频推荐平台、音视频理解、风控、商业化广告、强化学习等都是公司的核心业务,多个业务场景数据处理需求量大,英伟达推出新的特斯拉架构产品之后,SAT团队将TESLA T4/V100 GPU的引入列为首要任务,使用新一代的GPU,搭配现有的计算平台(CPU、FPGA等),将TESLA T4引入到新的套餐上,同时以最快速度适配给公司内的核心业务,保障硬件基础架构走在业界前列。
GPU架构优化性能提升2倍成本节省30%
针对快手快速增长的业务需求,既需要尽可能的满足业务灵活多变的需求,又不能使得套餐数量过于发散,同时要兼顾成本优化目标,所面临的问题十分复杂。为平衡需求和复杂性,快手SAT团队最终决定引入了2个GPU套餐,搭配虚拟化容器,满足不同业务场景下的不同需求。
GPU服务器特别是多卡GPU服务器在实际计算中,普遍会面临CPU性能成为瓶颈的问题。为了解决CPU性能瓶颈、GPU利用率不高的问题,快手SAT团队联合算法团队,通过在Resnet50/SSD上将Resize、Augment等从CPU端迁移至GPU端的方法,将CPU的loading逐步迁移到GPU上,进一步利用了GPU强大的计算能力,解放了CPU,达到了CPU和GPU之间的均衡计算效果。
GPU之间的性能均衡是另一个问题。部分业务场景的模型体积非常巨大,单GPU显存往往没有办法存下整个模型,这时候通常会将模型存在内存中,由CPU来进行相对应的运算操作,快手SAT团队通过优化CPU亲和性,避免了负载不均和查找路径较远的问题。
快手的训练模型要求精度较高,之前普遍使用FP32,模型较大,目前正在慢慢使用混合精度来替代原来方案,性能得到明显提升。 在实际使用中,快手SAT团队也发现AMP(自动混合精度)虽然使用起来简单,但并不能适配所有业务。所以需要快手SAT团队和业务团队一起尝试不同方法,结合FP32、AMP以及手动混合精度等手段为业务方的训练提供计算性能。
推理模型相对于训练模型,普遍存在batchsize较小的问题,需要对内存进行频繁的读写访问,同时推理相较于训练,要求的精度没有那么高。为解决这些问题,同时为更好的利用新架构中的Tensor Core的性能,快手SAT团队引入了TensorRT,帮助业务快速使用在GPU上,使得运行速度大大提升,编译后的代码所占内存的大小大大缩减。
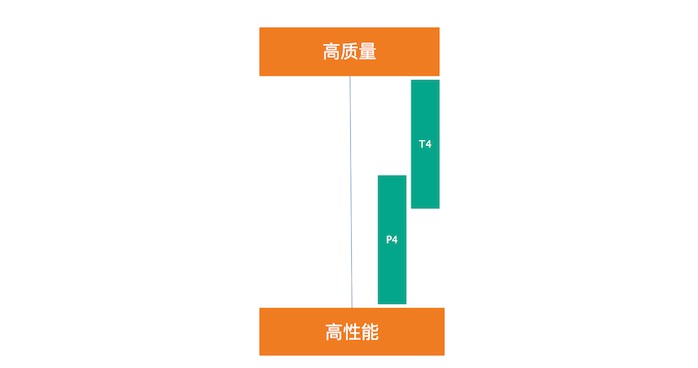
解码H264:T4 / P4 = 2.6 倍左右; 解码Hevc:T4/P4 = 4倍左右。在Hevc下的高性能,得益于T4的2个nvdec引擎,解码Hevc时比H264投入的计算单元更多
T4的Fast Preset 与 P4的Slow preset在质量和并发数量上大致相当
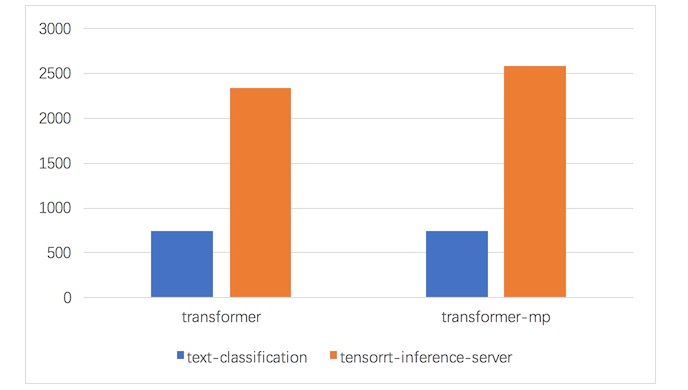
使用TensorRT-Inference-Server,对比text-classification,性能提升2倍左右
从以上对比图中可以看出,通过现阶段GPU计算架构的优化,业务的性能平均增长了2倍,成本较之前节省了30%以上。
软硬结合,优化落地
为了让新产品的特性更好的助力快手的业务,快手SAT团队提供了一整套的流程方案。了解业务使用需求后,通过分析目前的瓶颈点和高频使用资源,合理选择硬件产品,将这些产品快速集成在套餐之中。新硬件往往伴随着一些新的框架和指令集的支持,例如TESLA T4对于FP16的支持,使得T4的性能大幅提升。参考这些新特性,业务部门将代码优化后部署上线。通过Vtune/Nsight等工具对代码进行分析,优化低效的部分,最终呈现效果后上线灰度,追求高效迅捷,使得快手一直走在技术的前沿。
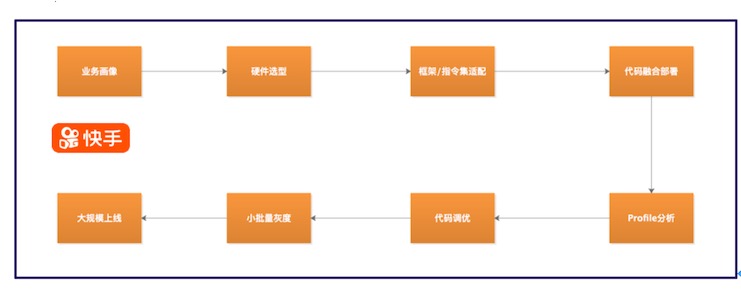
(图示:快手选型上线流程)
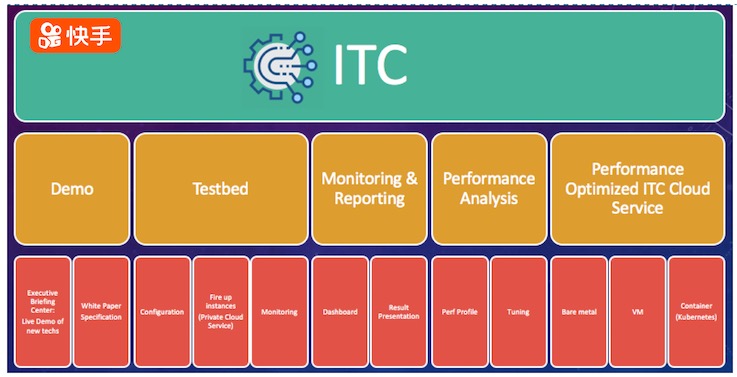
(图示:快手新硬件/新技术引入平台模块)
自定义监控,防范故障于未然
如果说使用是第一步的话,那么运维就是第二步。快手SAT团队针对GPU的监控,一共做了三件事,一是自主开发的GPU使用率监控,二是自定义的GPU故障监控,三是GPU的故障预判。
监控GPU的使用率,可以使得业务更加了解自己的负载情况,也可以验证前面选型配置的合理性。通常来说业内大多使用smi中的GPU-Util参数来判断GPU的使用情况,但快手在实际使用中发现,判断GPU的使用率是一个较为复杂的问题,GPU-Util反应的只是单位时间内GPU的整体使用情况,并不能清晰地反应GPU的负载情况。针对这种情况,快手SAT团队手动开发了一套使用率监控脚本,从SM单元、编解码单元采样值、带宽负载、读写时间比等多个维度进行分析,最终得出GPU的综合使用率。
故障的监控,是一个比较老生常谈的问题,在任何硬件产品上都会遇到,GPU因为其较高的功耗和温度,以及业务对其的强依赖性,最初快手SAT团队设置了非常多的监控指标,这些监控指标都是通过GPU设备的API提炼抽取出来的,但是随着监控实例的增加,告警的数量也随之大幅提高。这些告警里包括持续告警、波动告警、关联告警,当然这些告警的出现,使得快手发现了问题,但是也给快手的运维人员造成了极大的困扰。为了解决告警泛滥的问题,快手SAT团队对监控参数进行分析整合,针对不同业务使用GPU时的不同需求,制定业务生死标准:影响业务生存的标准优先报,在单位时间内发生的告警只报一个。
故障的预判,是为了避免有可能发生的故障对业务带来损失,这个预判的准确性是关键。故障的预判在很多情况下都是一个导火索,是一个随着时间的推移慢慢变成现象级的过程。快手SAT团队在故障的预判方面针对GPU设定了十余个监控参数,通过对这些积累下来的数据进行训练,得到一个阈值,再使用这个阈值进行故障预判。通过这个训练预测不断循环的过程,使得故障的预判越来越精准。
后续规划
随着快手日活量不断增加,用户数据不断丰富,模型的数量越来越多,越来越复杂,在空间的占用上呈几何级数增长。目前快手SAT团队正在做几件事:引入大容量低成本NVM与GPU组成异构计算+异构存储服务器;搭配100G/200G/400G RDMA,做CPU offload的架构,提高分布式计算的效率;将存储资源和计算资源解耦分离。
快手选型上线流程和英伟达企业级技术支持团队已经有了一年多的合作经验,以TESLA GPU引入为契机,快手SAT团队整理规范了GPU服务器引入和应用优化一整套的科学体系,并在实践中获得了较好的业务收益,为公司节省了大量的时间成本,同时计算力更加出色的GPU计算架构也为未来快手关键业务线上线更加复杂的模型打下了坚实的基础。快手系统运营部硬件研发团队诚聘新技术硬件研发工程师,欢迎每一个对技术有追求的技术人。























