












[ 导读 ]大多数情况下,数据分析的过程必须包括数据探索的过程。数据探索可以有两个层面的理解:
- 一是仅利用一些工具,对数据的特征进行查看;
- 二是根据数据特征,感知数据价值,以决定是否需要对别的字段进行探索,或者决定如何加工这些字段以发挥数据分析的价值。字段的选取既需要技术手段的支撑,也需要数据分析者的经验和对解决问题的深入理解。
01 数值类型
在进行数据分析时,往往需要明确每个字段的数据类型。数据类型代表了数据的业务含义,分为3个类型:
1. 区间型数据(Interval)
数值型数据的取值都是数值类型,其大小代表了对象的状态。比如,年收入的取值,其大小代表了其收入状态。
2. 分类型数据(Categorical)
分类型数据的每一个取值都代表了一个类别,如性别,两个取值代表了两个群体。
3. 序数型数据(Ordinal)
和分类型数据非常相似,每个取值代表了不同的类别。但是,序数型的数据还有另外一层含义就是每个取值是有大小之分的。比如,如果将年收入划分为3个档次:高、中、低,则不同的取值既有类别之分,也有大小之分。
如果不了解字段的实际业务含义,数据分析人员可能会出现数据类型判断失误。比如字段的取值为“1”“2”“3”等,并不意味着是一个数值类型,它的业务含义还可以是一个分类型的字段,“1”“2”“3”分别代表了一个类别,其大小没有任何含义。所以,充分了解字段的含义是很重要的。
很多的数据分析工具会根据数据中的字段的实际取值,做出类型的自动判断:如字符型的数据,一般都认定为分类型数据;如某个字段的所有取值只有“1”“2”“3”,则判断其为分类型变量,然后经过用户的再次判断,其很可能是序数型变量。
不同的数据类型,在算法进行模型训练时,处理和对待的方式是不同的。区间型数据是直接进行计算的;分类型数据是先将其转换为稀疏矩阵:每一个类别是一个新的字段,然后根据其取值“1”“0”进行计算。
在很多场景下,人们习惯将分类型数据和序数型数据统称为分类型数据,即数据类型可以是两个:数值型数据(区间型数据)和分类型数据(分类型数据和序数型数据)。
02 连续型数据的探索
连续型数据的探索,其关注点主要是通过统计指标来反映其分布和特点。典型的统计指标有以下几个:
4. 缺失值
取值为空的值即为缺失值。缺失值比例是确定该字段是否可用的重要指标。一般情况下,如果缺失率超过50%,则该字段就完全不可用。
在很多情况下,我们需要区别对待null和0的关系。Null为缺失值,0是有效值。这个区别很重要,要小心区别对待。例如,某客户在银行内的某账户余额为null,意味着该客户可能没有该账户。但是如果将null改为0,则是说用户有该账户,且账户余额为零。
5. 均值(Mean)
顾名思义,均值即平均值。其大小反映了整体的水平。一个数学平均成绩是95分的班级,肯定比平均成绩是80分的班级的数学能力要好。
6. 最大值和最小值
最大值和最小值即每个数据集中的最大数和最小数。
7. 方差
方差反映各个取值距平均值的离散程度。虽然有时两组数据的平均值大小可能是相同的,但是各个观察量的离散程度却很少能相同。方差取值越大,说明离散程度越大。比如,平均成绩是80分的班级,其方差很小,说明这个班级的数学能力比较平均:没有多少过高的成绩,也没有多少过低的成绩。
8. 标准差
标准差是方差的开方,其含义与方差类似。
9. 中位数(Median)
中位数是将排序后的数据集分为两个数据集,这两个数据集分别是取值高的数据集和取值低的数据集。比如,数据集{3,4,5,7,8}的中位数是5,在5之下和5之上分别是取值低和取值高的数据集。数据集{2,4,5,7}的中位数应当是(4 + 5)/2=4.5。
10. 众数(Mode)
众数是数据集中出现频率最高的数据。众数最常用的场景是分类型数据的统计,但是其也反映了数值型数据的“明显集中趋势点的数值”。
均值、中位数、众数的计算方式各有不同,假设有一组数据:
1,2,2,3,4,7,9
- 均值:(1 + 2 + 2 + 3 + 4 + 7 + 9)/7=4
- 中位数:3
- 众数:2
11. 四分位数(Quartile)
四分位数,即用三个序号将已经排序过的数据等分为四份,如表2-2所示。

表2-2 四分位的例子
第二四分位数(Q2)的取值和中位数的取值是相同的。
12. 四分位距(Interquartile Range,IQR)
四分位距通过第三四分位数和第一四分位数的差值来计算,即IQR=Q3-Q1。针对上表,其IQR=61-34=27。
四分位距是进行离群值判别的一个重要统计指标。一般情况下,极端值都在Q1-1.5×IQR之下,或者Q3 + 1.5×IQR之上。著名的箱形图就是借助四分位数和四分位距的概念来画的,如图2-1所示。
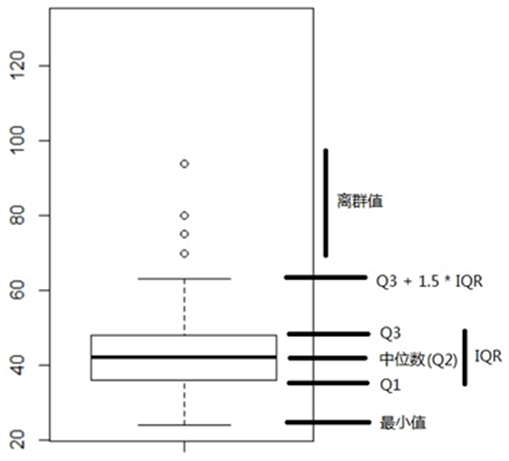
图2-1 箱形图及IQR
箱形图中的上下两条横线,有可能是离群值分界点(Q3 + 1.5×IQR或Q1-1.5×IQR),也有可能是最大值或最小值。这完全取决于最大值和最小值是否在分界点之内。
13. 偏斜度(Skewness)
偏斜度是关于表现数据分布的对称性的指标。如果其值是0,则代表一个对称性的分布;若其值是正值,代表分布的峰值偏左;若其值是负值,代表分布的峰值偏右。在图2-2中给出了偏斜度的示例。
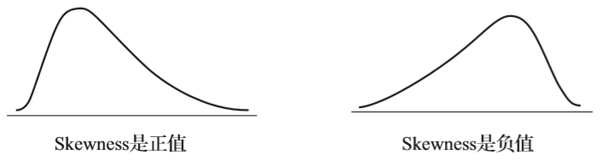
图2-2 Skewness的含义
Skewness的绝对值(不论是正值还是负值)如果大于1是个很明显的信号,你的数据分布有明显的不对称性。很多数据分析的算法都是基于数据的分布是类似于正态分布的钟型分布,并且数据都是在均值的周围分布。如果Skewness的绝对值过大,则是另一个信号:你要小心地使用那些算法!
不同的偏斜度下,均值、中位数、众数的取值是有很大不同的:
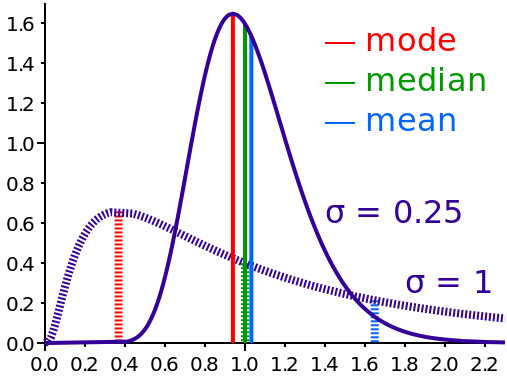
图2-3 众数、均值及中位数在不同分布下的比较
由图2-3可见,在数据取值范围相同的情况下,中位数是相同的。但是均值和众数却有很大的不同。所以,除了偏斜度指标可以直接反映分布特征外,还可以通过中位数和均值的差异来判断分布的偏斜情况。
- 中位数<均值:偏左分布
- 中位数、均值相差无几:对称分布
- 中位数>均值:偏右分布
14. 峰态(Kurtosis)
标准正态分布的峰态的值是3,但是在很多数据分析工具中对峰态值减去3,使得:0代表是正态分布;正值代表数据分布有个尖尖的峰值,高于正态分布的峰值;负值代表数据有个平缓的峰值,且低于正态分布的峰值。
峰态指标的主要作用是体现数值分布的尾巴厚度,尖峰对应着厚尾,即Kurtosis大于0时,意味着有一个厚尾巴。尖峰厚尾也就是说,在峰值附近取值较集中,但在非峰值附近取值较分散。图2-4所示为一个峰态的例子。
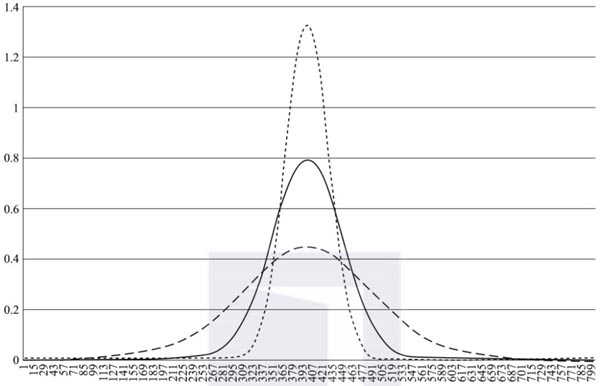
图2-4 峰态的例子
在连续型数据的探索中,需要重点关注的指标首先是缺失率,然后是均值、中位数等指标,这些指标能帮助数据分析者对数据的特征有很好的了解。偏斜度是另外一个非常重要的指标,但其绝对值接近1或大于1时,必须对其进行log转换才能使用,否则该指标的价值将大打折扣。
Python Pandas中DataFrame的describe方法默认只统计连续性字段的最大值、最小值、均值、标准差、四分位数,如果想获取其他的特征值,需要调用相应的函数来获得。下面是一段示例代码,其运行结果通过表2-4来展示。
- List_of_series = [bank.var().rename('方差'),
- bank.median().rename('中位数'),
- bank.skew().rename('偏斜度'),
- bank.kurt().rename('峰态')]
- df = pd.DataFrame(list_of_series)
- mode = bank.mode(numeric_only=True).rename({0: '众数'})
- pd.concat([df, mode])
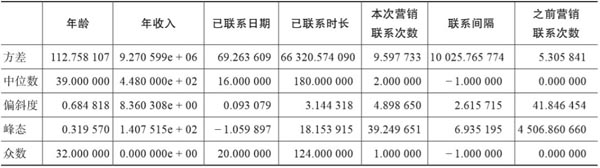
▲表2-4 连续型变量数据探索示例代码的运行结果
03 分类型数据的探索
分类型数据的探索主要是从分类的分布等方面进行考察。常见的统计指标有以下几个:
15. 缺失值
缺失值永远是需要关心的指标,不论是连续型数据,还是分类型数据。过多的缺失值,会使得指标失去意义。
16. 类别个数
依据分类型数据中类别的个数,可以对指标是否可用有一个大致的判断。例如,从业务角度来看,某指标应当有6个类别,但实际样本中只出现了5个类别,则需要重新考虑样本的质量。再如,某个分类型变量只有一个类别时,对数据分析是完全不可用的。
17. 类别中个体数量
在大多数情况下,如果某些类别中个体数量太少,如只有1%的比例,可以认为该类别是个离群值。关于分类型变量离群值的研究比较多,但是如果脱离业务来谈分类型变量的离群值,是不妥当的。
不平衡数据就是一个典型的与业务有关的例子。比如,从业务角度来看,购买黄金的客户只占银行全量客户的很小的一个部分,如果采取简单随机抽样的方式,“是否购买”列的值将只有极少的“是”的取值。
但是,不能将“是”直接判断为离群值,反而“是”有极其重要的业务含义。所以,数据分析者需要灵活地认识和对待类别中个体数量的问题。
18. 众数
和连续型数据的含义一样,众数是数据集中出现频率最高的数据。比如,针对某个分类型取值A、B、C、D中C的出现次数最多,则C就是众数。
以下是一段分类型变量数据探索示例代码,其运行结果通过表2-5来展示。
- bank.describe(include=[np.object])
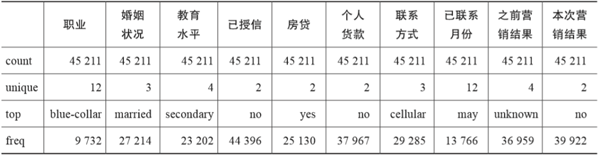
表2-5 分类型变量数据探索示例代码的运行结果
应用Python Pandas的相关函数能够非常容易得到分类型变量的探索结果,表2-5所示就是数据探索示例代码的运行结果。




















