不同的损失函数可用于不同的目标。在这篇文章中,我将带你通过一些示例介绍一些非常常用的损失函数。这篇文章提到的一些参数细节都属于tensorflow或者keras的实现细节。
损失函数的简要介绍
损失函数有助于优化神经网络的参数。我们的目标是通过优化神经网络的参数(权重)来很大程度地减少神经网络的损失。通过神经网络将目标(实际)值与预测值进行匹配,再经过损失函数就可以计算出损失。然后,我们使用梯度下降法来优化网络权重,以使损失最小化。这就是我们训练神经网络的方式。
均方误差
当你执行回归任务时,可以选择该损失函数。顾名思义,这种损失是通过计算实际(目标)值和预测值之间的平方差的平均值来计算的。
例如,你有一个神经网络,通过该网络可以获取一些与房屋有关的数据并预测其价格。在这种情况下,你可以使用MSE(均方误差)损失。基本上,在输出为实数的情况下,应使用此损失函数。
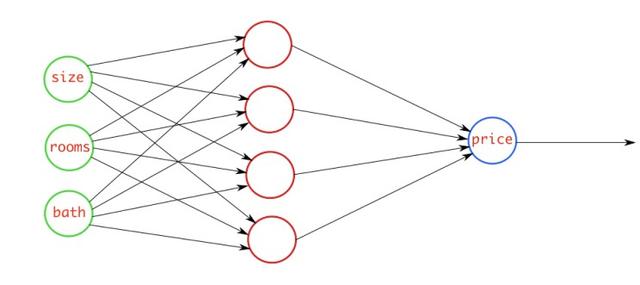
二元交叉熵
当你执行二元分类任务时,可以选择该损失函数。如果你使用BCE(二元交叉熵)损失函数,则只需一个输出节点即可将数据分为两类。输出值应通过sigmoid激活函数,以便输出在(0-1)范围内。
例如,你有一个神经网络,该网络获取与大气有关的数据并预测是否会下雨。如果输出大于0.5,则网络将其分类为会下雨;如果输出小于0.5,则网络将其分类为不会下雨。即概率得分值越大,下雨的机会越大。
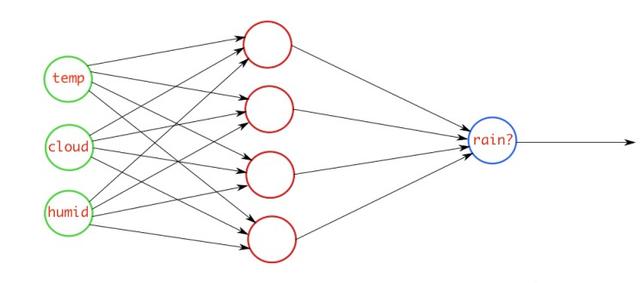
训练网络时,如果标签是下雨,则输入网络的目标值应为1,否则为0。
重要的一点是,如果你使用BCE损失函数,则节点的输出应介于(0-1)之间。这意味着你必须在最终输出中使用sigmoid激活函数。因为sigmoid函数可以把任何实数值转换(0–1)的范围。(也就是输出概率值)
如果你不想在最后一层上显示使用sigmoid激活函数,你可以在损失函数的参数上设置from logits为true,它会在内部调用Sigmoid函数应用到输出值。
多分类交叉熵
当你执行多类分类任务时,可以选择该损失函数。如果使用CCE(多分类交叉熵)损失函数,则输出节点的数量必须与这些类相同。最后一层的输出应该通过softmax激活函数,以便每个节点输出介于(0-1)之间的概率值。
例如,你有一个神经网络,它读取图像并将其分类为猫或狗。如果猫节点具有高概率得分,则将图像分类为猫,否则分类为狗。基本上,如果某个类别节点具有很高的概率得分,图像都将被分类为该类别。
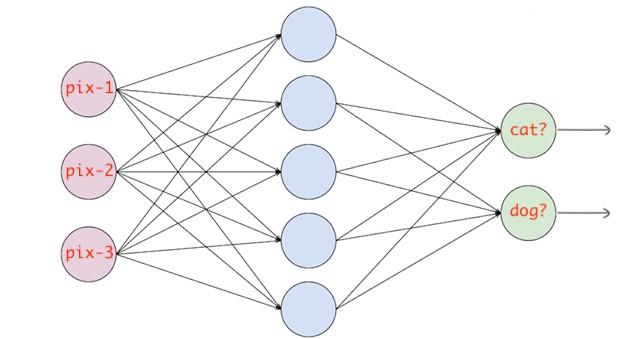
为了在训练时提供目标值,你必须对它们进行一次one-hot编码。如果图像是猫,则目标向量将为(1,0),如果图像是狗,则目标向量将为(0,1)。基本上,目标向量的大小将与类的数目相同,并且对应于实际类的索引位置将为1,所有其他的位置都为零。
如果你不想在最后一层上显示使用softmax激活函数,你可以在损失函数的参数上设置from logits为true,它会在内部调用softmax函数应用到输出值。与上述情况相同。
稀疏多分类交叉熵
该损失函数几乎与多分类交叉熵相同,只是有一点小更改。
使用SCCE(稀疏多分类交叉熵)损失函数时,不需要one-hot形式的目标向量。例如如果目标图像是猫,则只需传递0,否则传递1。基本上,无论哪个类,你都只需传递该类的索引。
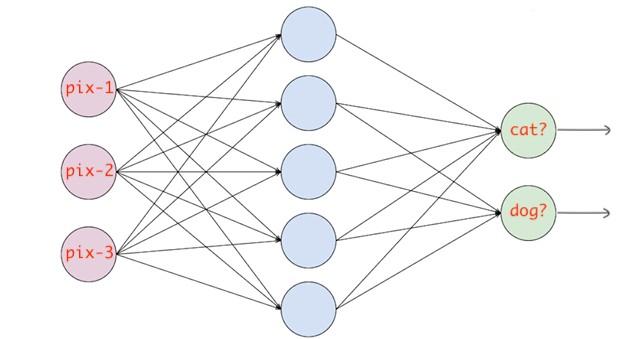
这些是最重要的损失函数。训练神经网络时,可能会使用这些损失函数之一。
下面的链接是Keras中所有可用损失函数的源代码。
(https://github.com/keras-team/keras/blob/c658993cf596fbd39cf800873bc457e69cfb0cdb/keras/backend/numpy_backend.py)