












首先让我们来聊聊什么是大数据。大数据这个概念已经出来很多年了(超过 10 年),但一直没有一个准确的定义(也许也并不需要)。数据工程师(DataEngineer)对大数据的理解会更多从技术和系统的角度去理解,而数据分析人员(Data Analyst)对大数据理解会从产品的角度去理解,所以数据工程师(Data Engineer) 和数据分析人员(Data Analyst)所理解的大数据肯定是有差异的。我所理解的大数据是这样的,大数据不是单一的一种技术或者产品,它是所有与数据相关的综合学科。看大数据我会从 2 个维度来看,一个是数据流的维度(下图的水平轴),另外一个是技术栈的维度(下图的纵轴)。
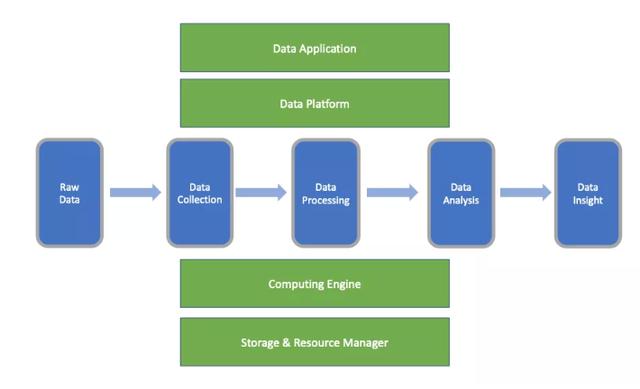
其实我一直不太喜欢张口闭口讲“大数据”,我更喜欢说“数据”。因为大数据的本质在于“数据”,而不是“大”。由于媒体一直重点宣扬大数据的“大”,所以有时候我们往往会忽然大数据的本质在“数据”,而不是“大”,“大”只是你看到的表相,本质还是数据自身。
在我们讲清楚大数据的含义之后,我们来聊聊大数据目前到底处在一个什么样的位置。从历史发展的角度来看,每一项新技术都会经历下面这样一个技术成熟度曲线。
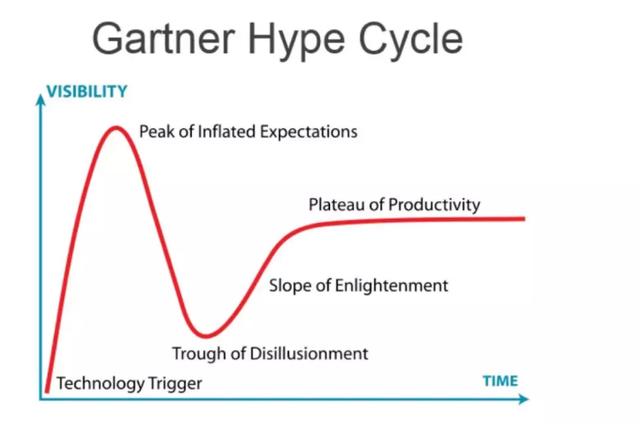
当一项新技术刚出来的时候人们会非常乐观,常常以为这项技术会给人类带来巨大的变革,对此持有过高的期望,所以这项技术一开始会以非常快的速度受到大家追捧,然后到达一个顶峰,之后人们开始认识到这项新技术并没有当初预想的那么具有革命性,然后会过于悲观,之后就会经历泡沫阶段。等沉寂一定阶段之后,人们开始回归理性,正视这项技术的价值,然后开始正确的应用这项技术,从此这项技术开始走向稳步向前发展的道路。(题外话,笔者在看这幅图的时候也联想到了一个男人对婚姻看法的曲线图,大家自己脑补)。
从大数据的历史来看,大数据已经经历了 2 个重要阶段
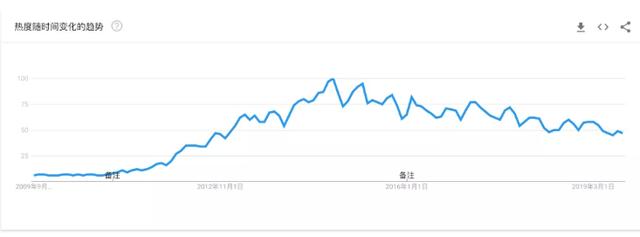
两个重要阶段是指过高期望的峰值和泡沫化的底谷期 。现在正处于稳步向前发展的阶段。我们可以从 googletrend 上 big data 的曲线就能印证。大数据大约从 2009 年开始走向人们的视野,在 2015 年左右走向了顶峰,然后慢慢走向下降通道(当然这张曲线并不会和上面这张技术成熟度曲线完全拟合,比如技术曲线处在下降通道有可能会使讨论这项技术的搜索量增加)。
数据规模会继续扩大,大数据将继续发扬光大
前面已经提到过,大数据已经度过了过高期望的峰值和泡沫化的底谷期,现在正在稳步向前发展。做这样判断主要有以下 2 个原因:
上游数据规模会继续增长,特别是由于 IOT 技术的发展和成熟,以及未来 5G 技术的铺开。在可预测的未来,数据规模仍将继续快速增长,这是能够带动大数据持续稳定向前发展的基本动力。
下游数据产业还有很多发展的空间,还有很多数据的价值我们没有挖掘出来。
虽然现在人工智能,区块链抢去了大数据的风口位置,也许大数据成不了未来的主角,但大数据也绝对不是跑龙套的,大数据仍将扮演一个重要而基础的角色。可以这么说,只要有数据在,大数据就永远不会过时。我想在大部分人的有生之年,我们都会见证大数据的持续向上发展。
数据的实时性需求将更加突出
之前大数据遇到的最大挑战在于数据规模大(所以大家会称之为“大数据”),经过工业界多年的努力和实践,规模大这个问题基本已经解决了。接下来几年,更大的挑战在于速度,也就是实时性。而大数据的实时性并不是指简单的传输数据或者处理数据的实时性,而是从端到端的实时,任何一个步骤速度慢了,就影响整个大数据系统的实时性。所以大数据的实时性,包括以下几个方面:
- 快速获取和传输数据
- 快速计算处理数据
- 实时可视化数据
- 在线机器学习,实时更新机器学习模型
目前以 Kafka,Flink 为代表的流处理计算引擎已经为实时计算提供了坚实的底层技术支持,相信未来在实时可视化数据以及在线机器学习方面会有更多优秀的产品涌现出来。当大数据的实时性增强之后,在数据消费端会产生更多有价值的数据,从而形成一个更高效的数据闭环,促进整个数据流的良性发展。
大数据基础设施往云上迁移势不可挡
目前 IT 基础设施往云上迁移不再是一个大家还需要争论的问题,这是大势所趋。当然我这边说的云并不单单指公有云,也包括私有云,混合云。因为由于每个企业的业务属性不同,对数据安全性的要求不同,不可能把所有的大数据设施都部署在公有云上,但向云上迁移这是一个未来注定的选择。目前各大云厂商都提供了各种各样的大数据产品以满足各种用户需求,包括平台型(PAAS) 的 EMR ,服务型 (SAAS) 的数据可视化产品等等。
大数据基础设施的云化对大数据技术和产品产生也有相应的影响。大数据领域的框架和产品将更加 Cloud Native 。
- 计算和存储的分离。我们知道每个公有云都有自己对应的分布式存储,比如 AWS 的 S3 。 S3 在一些场合可以替换我们所熟知的 HDFS ,而且成本更低。而 S3 的物理存储并不是在 EC2 上面,对 EC2 来说, S3 是 remote storage 。所以如果你要是 AWS 上面做大数据开发和应用,而且你的数据是在 S3 上,那么你就自然而然用到了计算和存储的分离。
- 拥抱容器,与 Kubernate 的整合大势所趋,我们知道在云环境中 Kuberneate 基本上已经是容器资源调度的标准。
- 更具有弹性(Elastic)。
- 与云上其他产品和服务整合更加紧密。
大数据产品全链路化
全链路化是指提供端到端的全链路解决方案,而不是简单的堆积一些大数据产品组件。以 Hadoop 为代表的大数据产品一直被人诟病的主要问题就是用户使用门槛过高,二次开发成本太高。全链路化就是为了解决这一问题,用户需要的并不是 Hadoop,Spark,Flink 等这些技术,而是要以这些技术为基础的能解决业务问题的产品。 Cloudera 的从 Edge 到 AI 是我比较认同的方案。大数据的价值并不是数据本身,而是数据背后所隐藏的对业务有影响的信息和知识。下面是一张摘自 wikipedia 的经典数据金字塔的图。
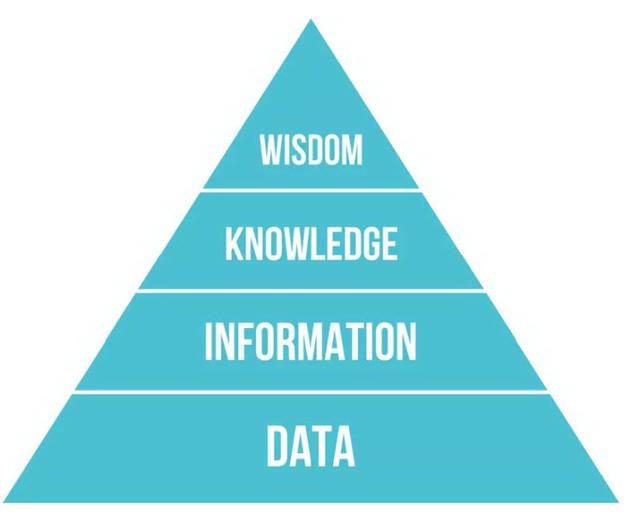
大数据技术就是对最原始的数据进行不断处理加工提炼,金字塔每上去一层,对应的数据量会越小,同时对业务的影响价值会更大更快。而要从数据(Data) 最终提炼出智慧(Wisdom),数据要经过一条很长的数据流链路,没有一套完整的系统保证整条链路的高效运转是很难保证最终从数据中提炼出来有价值的东西的,所以大数据未来产品全链路化是另外一个大的趋势。
大数据技术往下游数据消费和应用端转移
上面讲到了大数据的全链路发展趋势,那么这条长长的数据链路目前的状况是如何,未来又会有什么样的趋势呢?
我的判断是未来大数据技术的创新和发力会更多的转移到下游数据消费和应用端。之前十多年大数据的发展主要集中在底层的框架,比如最开始引领大数据风潮的 Hadoop ,后来的计算引擎佼佼者 Spark,Flink 以及消息中间件 Kafka ,资源调度器 Kubernetes 等等,每个细分领域都涌现出了一系列优秀的产品。总的来说,在底层技术框架这块,大数据领域已经基本打好了基础,接下来要做的是如何利用这些技术为企业提供最佳用户体验的产品,以解决用户的实际业务问题,或者说未来大数据的侧重点将从底层走向上层。之前的大数据创新更偏向于 IAAS 和 PAAS ,未来你将看到更多 SAAS 类型的大数据产品和创新。
从近期一些国外厂商的收购案例,我们可以略微看出一些端倪。
- 2019 年 6 月 7 日,谷歌宣布以 26 亿美元收购了数据分析公司 Looker,并将该公司并入 Google Cloud。
- 2019 年 6 月 10 日,Salesforce 宣布以 157 亿美元的全股票交易收购 Tableau ,旨在夯实在数据可视化以及帮助企业解读所使用和所积累的海量数据的其他工具方面的工作。
- 2019 年 9 月初,Cloudera 宣布收购 Arcadia Data 。 Arcadia Data 是一家云原生 AI 驱动的商业智能实时分析厂商。
面对最终用户的大数据产品将是未来大数据竞争的重点,我相信会未来大数据领域的创新也将来源于此,未来 5 年内大概率至少还会再出一个类似 Looker 这样的公司,但是很难再出一个类似 Spark 的计算引擎。
底层技术的集中化和上层应用的全面开花
学习过大数据的人都会感叹大数据领域的东西真是多,特别是底层技术,感觉学都学不来。经过多年的厮杀和竞争,很多优秀的产品已经脱颖而出,也有很多产品慢慢走向消亡。比如批处理领域的 Spark 引擎基本上已经成为批处理领域的佼佼者,传统的 MapReduce 除了一些旧有的系统,基本不太可能会开发新的 MapReduce 应用。 Flink 也基本上成为低延迟流处理领域的不二选择,原有的 Storm 系统也开始慢慢退出历史舞台。同样 Kafka 也在消息中间件领域基本上占据了垄断地位。未来的底层大数据生态圈中将不再有那么多的新的技术和框架,每个细分领域都将优胜劣汰,走向成熟,更加集中化。未来更大的创新将更多来来自上层应用或者全链路的整合方面。在大数据的上层应用方面未来将会迎来有更多的创新和发展,比如基于大数据上的 BI 产品, AI 产品等等,某个垂直领域的大数据应用等等,我相信未来我们会看到更多这方面的创新和发展。
开源闭源并驾齐驱
大数据领域并不是只有 Hadoop,Spark,Flink 等这类大家耳熟能详的开源产品,还有很多优秀的闭源产品,比如 AWS 上的 Redshift ,阿里的 MaxCompute 等等。这些产品虽然没有开源产品那么受开发者欢迎,但是他们对于很多非互联网企业来说是非常受欢迎的。因为对于一个企业来说,采用哪种大数据产品有很多因素需要考虑,否开源并不是唯一标准。产品是否稳定,是否有商业公司支持,是否足够安全,是否能和现有系统整合等等往往是某些企业更需要考虑的东西,而闭源产品往往在这类企业级产品特性上具有优势。
最近几年开源产品受公有云的影响非常大,公有云可以无偿享受开源的成果,抢走了开源产品背后的商业公司很多市场份额,所以最近很多开源产品背后的商业公司开始改变策略,有些甚至修改了 Licence 。不过我觉得公有云厂商不会杀死那些开源产品背后的商业公司,否则就是杀鸡取卵,杀死开源产品背后的商业公司,其实就是杀死开源产品的最大技术创新者,也就是杀死开源产品本身。我相信开源界和公有云厂商最终会取得一个平衡,开源仍然会是一个主流,仍然会是创新的主力,一些优秀的闭源产品同样也会占据一定的市场空间。
最后我想再次总结下本文的几个要点:
目前大数据已经度过了最火的峰值期和泡沫化的底谷期,现在正处于稳步向前发展的阶段。
- 数据规模会继续扩大,大数据将继续发扬光大
- 数据的实时性需求将更加突出
- 大数据基础设施往云上迁移势不可挡
- 大数据产品全链路化
- 大数据技术往下游数据消费和应用端转移
- 底层技术的集中化和上层应用的全面开花
- 开源闭源并驾齐驱














