近日,BAIR 开源强化学习研究代码库 rlpyt,首次包含三大类无模型强化学习算法,并提出一种新型数据结构。
2013 年有研究者提出使用深度强化学习玩游戏,之后不久深度强化学习又被应用于模拟机器人控制,自此以后大量新算法层出不穷。其中大部分属于无模型算法,共分为三类:深度 Q 学习(DQN)、策略梯度和 Q 值策略梯度(QPG)。由于它们依赖不同的学习机制、解决不同(但有重合)的控制问题、处理不同属性的动作集(离散或连续),因此这三类算法沿着不同的研究路线发展。目前,很少有代码库同时包含这三类算法,很多原始实现仍未公开。因此,从业者通常需要从不同的起点开始开发,潜在地为每一个感兴趣的算法或基线学习新的代码库。强化学习研究者必须花时间重新实现算法,这是一项珍贵的个人实践,但它也导致社区中的大量重复劳动,甚至成为了入门障碍。
这些算法具备很多共同的强化学习特点。近日,BAIR 发布了 rlpyt 代码库,利用三类算法之间的共性,在共享的优化基础架构上构建了这三类算法的实现。
GitHub 地址:https://github.com/astooke/rlpyt
rlpyt 库包含很多常见深度强化学习算法的模块化实现,这些实现是在深度学习库 Pytorch 中使用 Python 语言写成的。在大量已有实现中,rlpyt 对于研究者而言是更加全面的开源资源。
rlpyt 的设计初衷是为深度强化学习领域中的中小规模研究提供高吞吐量代码库。本文将简要介绍 rlpyt 的特征,及其与之前工作的关联。值得注意的是,rlpyt 基于论文《Recurrent Experience Replay in Distributed Reinforcement Learning》(R2D2)复现了 Atari 游戏领域中的近期最佳结果,不过它没有使用分布式计算基础架构来收集训练所需的数十亿游戏视频帧。本文还将介绍一个新的数据结构——namedarraytuple,它在 rlpyt 中广泛用于处理 numpy 数组集合。更多技术讨论、实现详情和使用说明,参见论文《rlpyt: A Research Code Base for Deep Reinforcement Learning in PyTorch》。
论文地址:https://arxiv.org/abs/1909.01500
rlpyt 库的重要特征和能力包括:
- 以串行模式运行实验(对 debug 有帮助);
- 以并行模式运行实验,具备并行采样和/或多 GPU 优化的选项;
- 同步或异步采样-优化(异步模式通过 replay buffer 实现);
- 在环境采样中,使用 CPU 或 GPU 进行训练和/或分批动作选择;
- 全面支持循环智能体;
- 在训练过程中,执行在线或离线评估,以及智能体诊断日志记录;
- 在本地计算机上,启动对实验进行栈/队列(stacking / queueing)设置的程序;
- 模块化:易于修改和对已有组件的重用;
- 兼容 OpenAI Gym 环境接口。
rlpyt 库中的已实现算法包括:
- 策略梯度:A2C、PPO
- DQN 及其变体:Double、Dueling、Categorical、Rainbow minus Noisy Nets、Recurrent (R2D2-style)
- QPG:DDPG、TD3、SAC
replay buffer(支持 DQN 和 QPG)包含以下可选特征:n-step returns、prioritized replay、sequence replay (for recurrence)、frame-based buffers(从多帧观测结果中仅存储独特的 Atari 游戏帧)。
加速实验的并行计算架构
采样
无模型强化学习的两个阶段——采样环境交互和训练智能体,可按照不同方式并行执行。例如,rlpyt 包括三种基本选项:串行、并行-CPU、并行 GPU。
串行采样最简单,因为整个程序在一个 Python 进程中运行,且有利于 debug。但环境通常基于 CPU 执行,且是单线程,因此并行采样器使用 worker 进程来运行环境实例,以加速整体收集率(collection rate)。CPU 采样还在 worker 进程中运行智能体的神经网络,以选择动作。GPU 采样则将所有环境观测结果分批,然后在 master 进程中选择动作,这样能够更充分地利用 GPU。这些配置详见下图。
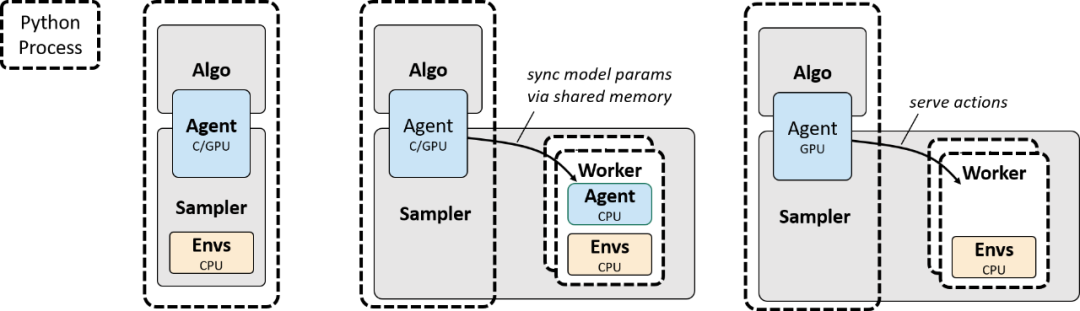
环境交互采样图示。(左)串行:智能体和环境在一个 Python 进程中执行。(中)并行-CPU:智能体和环境在 CPU 上运行(并行 worker 进程)。(右)并行-GPU:环境在 CPU 上运行(并行 worker 进程),智能体在核心进程上运行,以保证分批动作选择。
此外,还有一个选项是 alternating-GPU 采样,即使用两组 worker:一组执行环境模拟,另一组等待新动作。当动作选择时间比批环境模拟时间稍短时,则可能带来加速。
优化
同步多 GPU 优化通过 PyTorch 的 DistributedDataParallel 模块实现。整个采样器-优化器栈在每个 GPU 的不同进程中被复制,模型在反向传播过程中对梯度执行规约(all-reduce),从而实现隐式地同步。在反向传播的同时,DistributedDataParallel 工具自动降低梯度,以便在大型网络上实现更好的扩展,详情见下图。(采样器可以是上文介绍的任意串行或并行配置。)
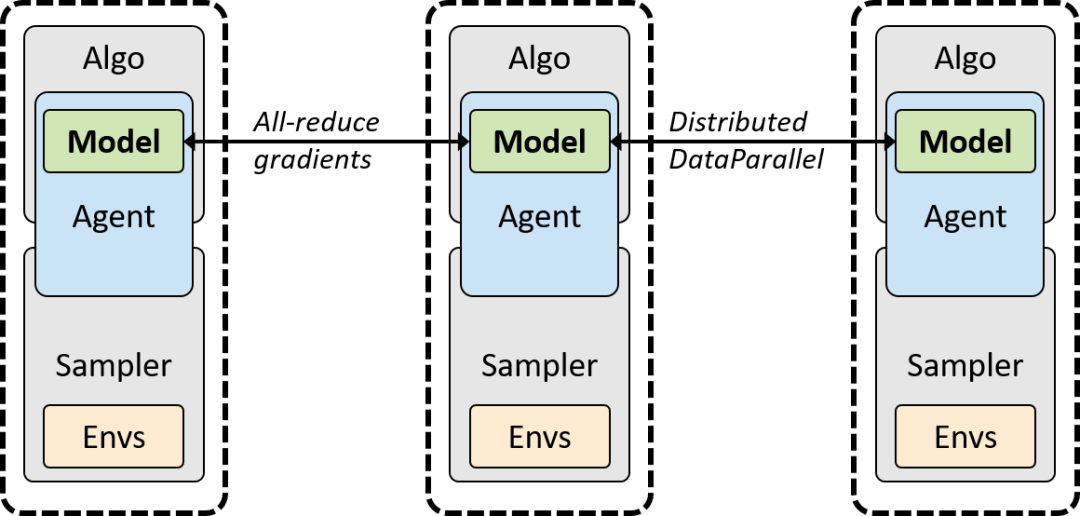
同步多进程强化学习。每个 Python 进程运行一个完整 sample-algorithm 栈副本,「同步」则通过 PyTorch 中的 DistribuedDataParallel 在反向传播过程中隐式地实现。支持 GPU(NCCL 后端)和 CPU(gloo 后端)模式。
异步采样优化
在目前已经介绍的配置中,采样器和优化器都是在同一个 Python 进程中顺序运行的。而在某些案例中,异步运行优化和采样可以实现更好的硬件利用率,因为这使得优化和采样连续运行。BAIR 在复现 R2D2 时就是这样,基于真实机器人学习也是这样的模式。
在异步模式下,运行训练和采样的是两个单独的 Python 进程,之后 replay buffer 基于共享内存将二者连接起来。采样的运行过程不受干扰,因为数据批次使用了双缓冲。而另一个 Python 进程在写锁模式下将分批数据复制到主缓冲区,详见下图。优化器和采样器可以独立并行,它们使用不同数量的 GPU,以实现最好的整体利用率和速度。
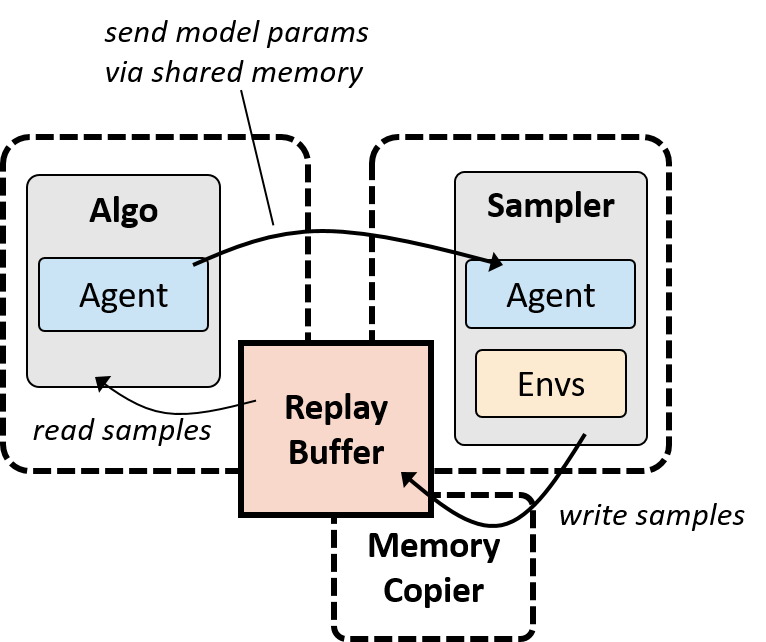
异步采样/优化模式。两个单独的 Python 进程通过共享内存的 replay buffer 来运行优化和采样(读写锁模式下)。内存复制器进程将分批数据写入 replay buffer,使得采样器可以即刻处理分批数据。
哪种配置最好?
对于创建或修改智能体、模型、算法和环境而言,串行模式最易于 debug。当串行程序流畅运行时,探索更复杂的基础架构就很轻松了,如并行采样、多 GPU 优化和异步采样,因为它们大致上是基于相同的接口构建的。最优配置取决于具体的学习问题、可用的计算机硬件和运行实验的数量。rlpyt 中包含的并行模式仅限于单节点,尽管其组件可作为分布式框架的构造块。
性能案例分析:R2D2
BAIR 展示了在 Atari 领域中复现 R2D2 结果的学习曲线,在以前只有使用分布式计算才会出现这样的学习曲线。该基准包括使用约 100 亿样本(400 亿帧)基于 replay buffer 训练得到的循环智能体。R2D1(非分布式 R2D2)使用 rlpyt 中多个更先进的基础架构组件来实现它,即使用 alternating-GPU 采样器的多 GPU 异步采样模式。下图展示了复现过程中的学习曲线,其中多个超过了之前的算法。我们需要注意,这些结果并未在所有游戏上完美复现,例如 Gravitar 游戏在比较低的得分处就已进入平台期。详情参见相关论文。
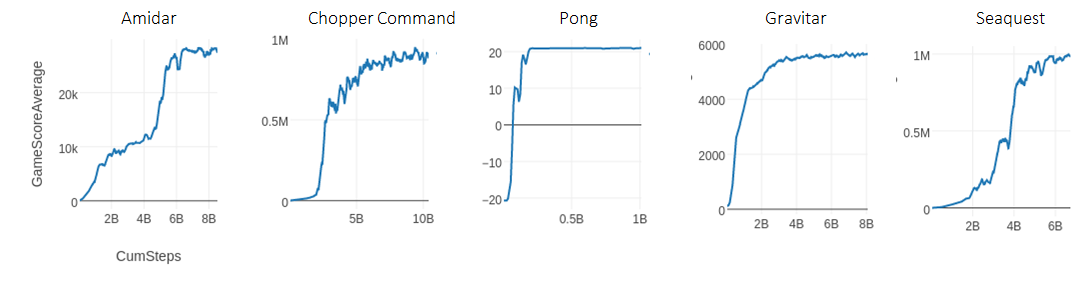
在 rlpyt 中使用一台计算机复现 R2D2 的学习曲线。
R2D2 的最初分布式实现使用了 256 块 CPU 进行采样,一块 GPU 执行训练,每秒运行 66,000 步。而 rlpyt 仅使用了一个包含 24 块 CPU(2x Intel Xeon Gold 6126)和 3 块 Titan-Xp GPU 的工作站,以每秒 16000 的步数完成实现。对于无法使用分布式基础架构的情况而言,这已经足够执行实验了。未来研究的一种可能是:利用多 GPU 优化增加 replay ratio,从而加快学习速度。下图展示了相同学习曲线在 3 种不同度量指标下的呈现,这 3 种度量指标分别是:环境步数(即 1 步=4 帧)、模型更新和时间。它在不到 138 个小时的时间内走完了 80 亿步,完成了 100 万次模型更新。
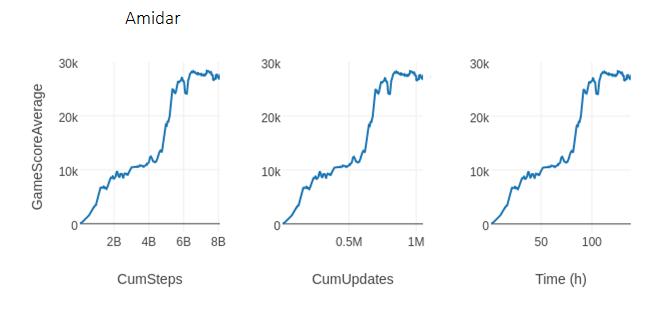
rlpyt 使用 24 块 CPU 和 3 块 Titan-Xp GPU 在异步采样模式下执行 R2D1 实现,其学习曲线在横坐标不同(环境步数、模型更新和时间)时的呈现如上图所示。
新型数据结构:namedarraytuple
rlpyt 提出了新的目标类别 namedarraytuples,可使 numpy 数组或 torch 张量的组织更加容易。namedarraytuple 本质上是一个 namedtuple,将索引或切片(sliced)数组读/写呈现在结构中。
试着写入一个(可能嵌套的)数组字典,这些数组具备一些共同的维度:
- for k, v in src.items():if isinstance(dest[k], dict):..recurse..dest[k][slice_or_indexes] = v
将上述代码替换成下列代码:
- dest[slice_or_indexes] = src
重要的是,不管 dest 和 src 是不同的 numpy 数组还是随机结构的数组集合,语法都是相同的(dest 和 src 的结构必须匹配,或者 src 是可应用于所有字段的单个值)。rlpyt 广泛使用该数据结构:使用相同的矩阵主维组织训练数据的不同元素,使其易于与期望时间维度或批量维度交互。此外,namedarraytuples 天然支持具备多模态动作或观测结果的环境。当神经网络的不同层使用不同模式时,这非常有用,因为它允许中间基础架构代码保持不变。
相关研究
深度强化学习新手可以先阅读其他资源,了解强化学习算法,如 OpenAI Spinning Up。
OpenAI Spinning Up 代码地址:https://github.com/openai/spinningup
文档地址:https://spinningup.openai.com/en/latest/
rlpyt 是 accel_rl 的修订版本,accel_rl 使用 Theano 尝试在 Atari 领域中扩展强化学习,详见论文《Accelerated Methods for Deep Reinforcement Learning》。对于深度学习和强化学习中的批大小扩展的进一步研究,参见 OpenAI 的报告(https://arxiv.org/abs/1812.06162)。rlpyt 和 accel_rl 最初都受 rllab 的启发。
其他已发布的研究代码库包括 OpenAI 基线和 Dopamine,二者都使用的是 Tensorflow 框架,都没有优化到 rlpyt 的程度,也不包含三类算法。基于 Ray 构建的 Rllib 采取不同的方法执行分布式计算,但可能把小实验复杂化。Facebook Horizon 提供了一组算法,主要关注大规模生产级应用。总之,rlpyt 提供更多算法的模块化实现以及并行化的模块化基础架构,是支持广泛研究应用的工具箱。
结论
BAIR 在相关博客中表示,rlpyt 可以促进对现有深度强化学习技术的便捷使用,并作为开启新研究的起点。例如,rlpyt 没有明确解决一些更先进的话题,如元学习、基于模型的强化学习和多智能体强化学习,但是 rlpyt 提供的可用代码可能对于加速这些领域的发展有所帮助。