一、背景介绍
引言:其实这段背景,我们之前介绍RabbitMQ的时候,已经说过了,我们这里讲kakfa的时候,再把这一段给拿出来,再说明下。在讲实战前,我们还是有必要讲解下理论的,理论为辅,实战为主,在实战的基础上,再深入理解理论,底层原理,底层源码。下篇文章或者视频,我们将带你看官网学习kafka环境搭建、kafka基本用法、kafka的容错性测试,在掌握知识的同时,还能顺便学习下英文。
1)问题引入:
假设我们现在需要设计这样一个用户注册系统:用户注册完成后,需要给用户发送激活邮件,开通用户账号,记录用户IP、用户设备、时间等信息。
起初的设计:

2)但存在的问题是:
由于多个系统强耦合在一起,用户注册响应会非常慢,严重影响了用户的体验,当流量大的时候,性能会更差。
3)引入消息中间件:
为了解决上述问题,我们引入消息中间件,来实现系统的解耦,多个系统间通过消息中间件进行异步通信,最终的设计图如下:
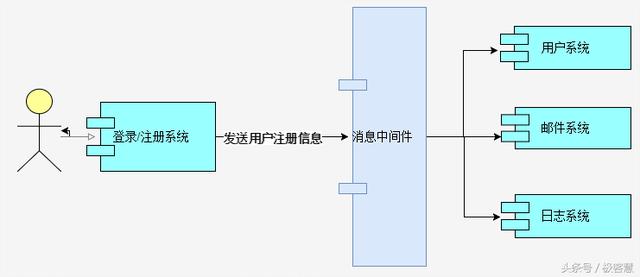
即实现了系统解耦,又提升了系统响应的速度
4)消息中间件介绍:
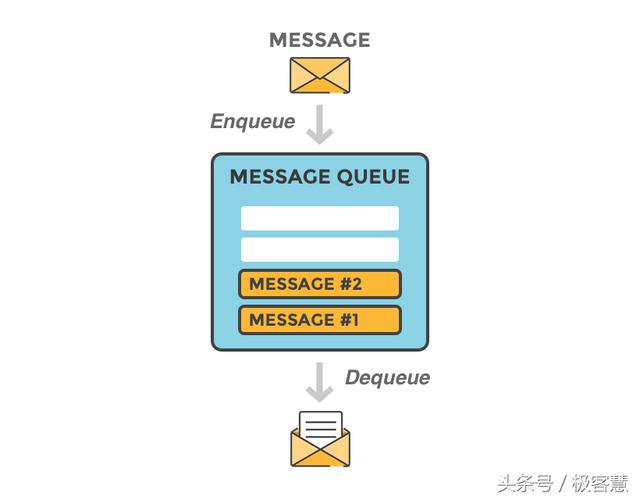
消息中间件(Message Queue Middleware,简称MQ)又称为消息队列,是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的构建。
2、应用场景分析
1)异步通信
在很多时候,为了加快应用系统整体运转速度,并不需要立即响应某些请求,消息中间件提供了异步处理机制,允许将一些请求信息放入消息中间件中,但并不立即处理它,而是慢慢处理。在有限资源下,使用消息中间件能够使系统性能从容倍增!
如:用户注册成功的邮件通知;用户购物下单的信息通知;大数据日志收集处理
2)削峰
以防突发剧增流量瞬间冲垮系统,使用消息中间件可以支撑突发访问压力
3)业务系统解耦
系统间的耦合关系太强,会对系统的设计产生束缚,也会增加系统的复杂性,通过消息中间件可以更好的设计系统,是一个系统完成指定的功能,而不是将所有的功能融合在同一个系统中。
二、kafka简介
Kafka作为一种消息中间件,是一种分布式的,基于发布/订阅的消息系统。主要设计目标如下:
以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能
高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输
支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输
同时支持离线数据处理和实时数据处理
1、kafka架构
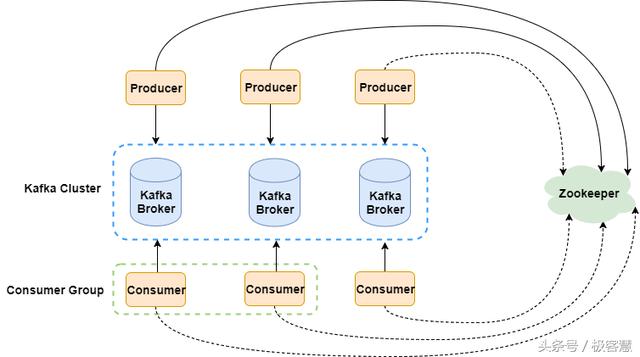
名词解释:
Broker
一个Kafka集群由一个或多个broker组成。搭建了kafka环境的服务器就可以称为broker。
Topic
Kafka集群上存储的消息都有一个类别,这个类别被称为topic。(使用者只需指定消息的topic,即可生产或消费数据而不必关心数据存于何处)Topic在逻辑上可以被认为是一个queue。每条消费都必须指定它的topic,可以简单理解为必须指明把这条消息放进哪个queue里,这与RabbitMQ就有点类似了。
Partition
为了使得Kafka的吞吐率可以水平扩展,物理上又把topic分成一个或多个partition,每个partition在物理上对应一个文件夹,该文件夹下存储这个partition的所有消息和索引文件。创建topic时可指定parition数量。我们实战演示的时候,会再次说明。
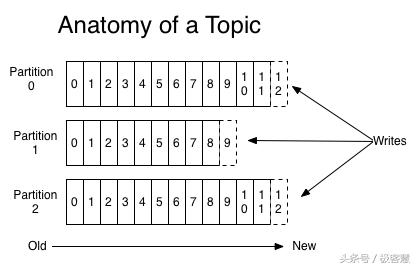
因为每条消息都被append到该partition中,是顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
Producer
负责发布消息到Kafka broker
Consumer
消费消息。每个consumer属于一个特定的consumer group(可为每个consumer指定group name,若不指定group name则属于默认的group)。同一topic的一条消息只能被同一个consumer group内的一个consumer消费,但多个consumer group可同时消费这一消息。
三、kafka其它核心概念
1、消息存储
很多传统的message queue都会在消息被消费完后将消息删除,一方面避免重复消费,另一方面可以保证queue的长度比较少,提高效率。而Kafka集群会保留所有的消息,无论其被消费与否。当然,因为磁盘限制,不可能永久保留所有数据(实际上也没必要),因此Kafka提供两种策略去删除旧数据。一是基于时间,二是基于partition文件大小。例如可以通过配置$KAFKA_HOME/config/server.properties,让Kafka删除一周前的数据,也可通过配置让Kafka在partition文件超过1GB时删除旧数据。
2、Consumer Group
每一个consumer实例都属于一个consumer group,每一条消息只会被同一个consumer group里的一个consumer实例消费。(不同consumer group可以同时消费同一条消息)
Kafka保证的是稳定状态下每一个consumer实例只会消费某一个或多个特定partition的数据,而某个partition的数据只会被某一个特定的consumer实例所消费。这样设计的劣势是无法让同一个consumer group里的consumer均匀消费数据,优势是每个consumer不用都跟大量的broker通信,减少通信开销,同时也降低了分配难度,实现也更简单。另外,因为同一个partition里的数据是有序的,这种设计可以保证每个partition里的数据也是有序被消费。
3、Consumer Rebalance
Kafka通过Zookeeper管理集群配置,在consumer group发生变化时(如:某个consumer因故障下线时)进行rebalance。具体含义为:
如果某consumer group中consumer数量少于partition数量,则至少有一个consumer会消费多个partition的数据,
如果consumer的数量与partition数量相同,则正好一个consumer消费一个partition的数据,
而如果consumer的数量多于partition的数量时,会有部分consumer无法消费该topic下任何一条消息。