













软件架构实际上包括了:代码架构,以及承载代码运行的硬件部署架构。实际上,硬件部署架构最终还是由代码的架构来决定。因为代码架构不合理,是无法把一个运行单元分拆出多个来的,那么硬件架构能分拆的就非常的有限,整个系统最终很难长的更大。
所以我们经常会听说,重写代码,推翻原有架构,重新设计等等说法,来说明架构的进化。这实际上就是当初为了完成任务,没有充分思考所带来的后果。这也并不是架构进化的事情,而是个人对问题领域的逐渐深入理解的过程。所以有必要再讨论一下,代码的架构应该是怎样的。
本文会在之前几篇文章的基础上,进一步探讨如何把架构的思考进行落地,细化到我们代码的实践当中,尽量不要让代码成为系统长大的瓶颈,降低架构分拆的成本。
在前面我们提到,软件实际上是对现实生活的模拟,虚拟化。这是一个非常重要的前提,直接决定了我们的代码应该分为几部分。结合每个部署单元所承担的责任,可以明确的拆分为两个不同的责任:
表达业务逻辑的代码。很多人把这部分叫做Domain Logic,或者叫Domain Model。这部分实际是来源于生活的,必须保持和现实生活中的切分一致,并非人为的抽象而成。
对用户提供访问并保存业务逻辑运行结果的代码。计算机的状态保存有一个缺陷,本机保留业务运行结果有很大的问题,一般都在外存储设备上保存,也便于扩展。
所以单个部署单元的代码可以分为两个部分,如下图所示:
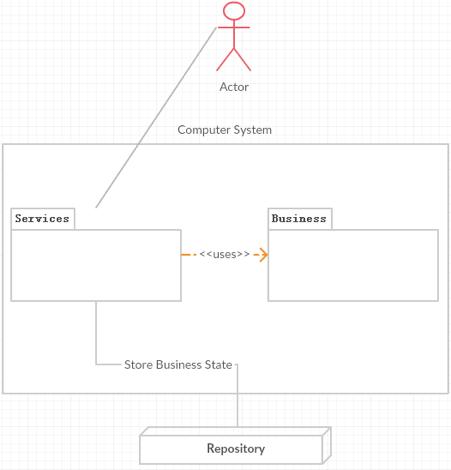
从这个图中可以看出,软件代码的相关利益人为运行时的访问人员和存储设备。而service的代码是最复杂的,需要服务于三方,代码人员的负担是最重的。为了把这三方的变化对service的影响降到最低,对于service还必须进一步的分拆为三个部分,让每一个部分都能够独立的变化,这样这三方的变化就不会产生连锁响应,降低成本。如下图所示:
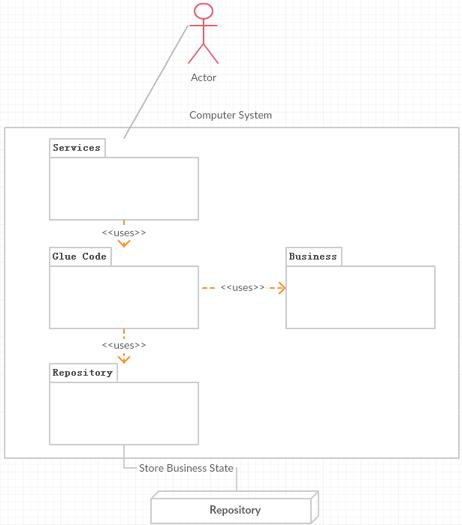
这样,就划分成了几个责任:
Service就专注于user的需求,并组合Glue Code提供的服务完成需求。
Glue Code专注于组合business的调用,管理Business里面对象的生命周期,并且通过Repository保存或加载Business的状态
Business专注于实现业务的核心模型。
Repository专注于数据的保存,并和存储设备一一对应。
大家注意看,还是树形架构。并且左侧的主要需要计算机的相关理论知识,并且要直接面对用户的需求。右侧的更多的需要面对业务的核心。只要这几块的开发人员互相商量好了接口定义,这几个部分的开发就可以并行的进行,极大的提升开发的效率,缩短开发的时间。要做好这几部分,还需要注意,逻辑只允许存在于Business中,Service、Glue Code、Repository都不允许存在业务逻辑。为什么呢?首先我们来看看什么叫业务逻辑。
什么叫业务逻辑?
首先这个定义的前提是指软件代码中的逻辑,不是现实生活中的逻辑。在软件代码中,不需缩进和计算的顺序调用,包括缩进的代码目的是catch exception的,都不算逻辑,除此以外都是逻辑。以下用严格的顺序调用来指代这种代码。因为顺序调用是计算机的特性,由编译器来决定的,当然最本质的是因为我们计算的基础都是图灵机。在现实生活中,顺序调用也是逻辑,大家不要和我们这里说的业务逻辑相混淆。
为什么说除了Business代码中有逻辑以外,其他地方不能有逻辑呢? 我们每个部分分别分析:
如果service里面不是严格的顺序调用,有很多分支,那么说明这个service做了两件或者两件以上的事情。必须把这个service分拆,确保每个service只做一件事情。因为如果不这么分拆的话,一旦这个service中的某各部分发生变动,其他的部分的执行必定会受影响。而确定到底有哪些影响的沟通成本非常高,其他相关利益方没有动力去配合,我们往往不会投入精力仔细评估。最后上线会出很多不可预料的问题,最终会导致损失用户的利益,并且肯定会导致返工,损坏自己的利益。如果是有计算的逻辑的话,比如受益计算,订单金额计算等,那么这部分应该是Business代码需要完成的,不能交给service代码来实现。
Glue Code里面如果不是严格的顺序调用,同理会和service一样遇到同样的问题。
Repository里面如果不是严格的顺序调用,包括存储访问的代码里面(比如SQL),会导致逻辑进入到存储设备中。存储设备的主要目的是拿来存储的,一旦变成了逻辑计算的主体,就会导致存储设备无法通过增加机器的方式横向扩展长大。这个时候就没有架构了,只能换性能更好的机器,这个叫scale up。只有scale out才能算架构。
以上都会导致架构无法快速的横向扩展和分拆,并且增加了修改的成本,这些是不符合开发人员以及业务的利益的。
这么做的好处有哪些呢?
Service、Glue Code、Repository里面的代码是严格的顺序调用,那么这些代码只要做连通性测试即可,不需要单元测试。因为这些代码都需要和很多上下文打交道,很难做单元测试。这样才算是真正的组合。
Business不访问任何上下文,不访问任何具体的设备,所以这部分代码是非常容易写单元测试的,并且单元测试必须100%覆盖。因为其他地方没有业务逻辑,所以一旦有问题,就可以断定是Model的问题,单元测试肯定可以发现。如果单元测试没有发现问题,那么单元测试一定有问题。线上问题的模拟也就变得非常的简单,单元测试也能够得到进一步的补充。
Repository很容易按照存储设备本身的最小访问粒度来完成工作,比如DB,完全可以做到单表访问。因为这个时候存储设备只关心存取数据,完全和业务没有关系。做表的分拆也是非常容易的事情,存储设备通过增加机器就可以横向扩展长大。很多人会担心说,没有了join,访问DB的次数是不是更多了,会导致性能下降? 按照现在网络的条件,网络访问和Disk IO访问的差距已经不大了,合理的设计下,多访问几次DB并不会导致这个问题。另外如果多台DB的话,还能通过并行加速访问。
由于Service、Glue Code、Repository代码简单了,才可以让我们的开发人员投入更多的时间研究业务,毕竟这部分才是软件所真正服务的对象。
我们再来看一个实际的例子,如下图所示:
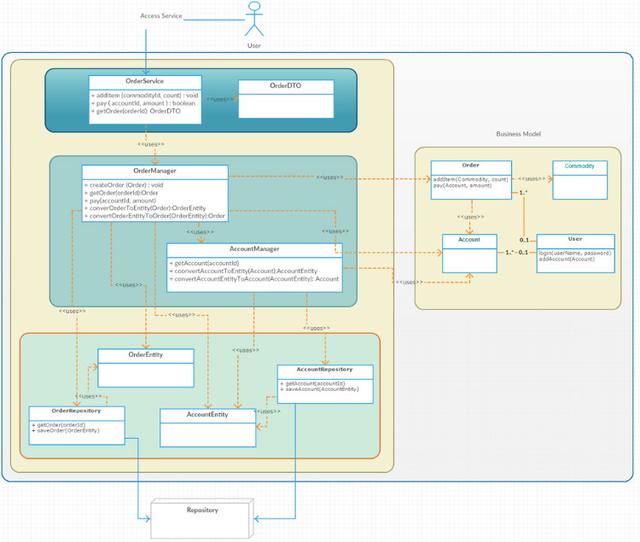
Manager类实际就是Glue Code。有几个注意点需要说明一下:
不能把Business Model当做数据对象来处理,Model关心的实际上是业务行为,数据只是是这些行为的结果。所以Glue Code需要把Model转换为Entity,Entity和存储设备里面的存储粒度一一对应。比如在DB中,每个Entity对应一张表,并且跟着表的变化而变化,这样就保证存储的变更不会影响Model。同样Service和用户之间的数据交互,也是不会和Model之间相关的,确保用户的需求变化,不会影响到Model。因为用户的需求变化是最频繁的,没有逻辑,可以让我快速的满足业务的需求。
在Service这里,最好不要考虑代码重用。因为当多个不同的角色访问同一个接口,一旦某个角色的需求发生了变化,就会要求开发人员去修改。而这个修改往往会影响到其他的角色,需要这些角色一起配合来确定是否受影响,但是这些角色因为没有需求,往往不会配合。这样就给开发人员造成了很多不必要的沟通,成本是非常高的。最终都会导致线上Bug,影响最终的用户。所以尽量给不同的角色不同的Service,避免重用,降低沟通成本。很多人会说这样Service不就太多了吗? 这样Service注册,查找等管理需求就出现了,Service治理中心就是来解决这个问题的。因为Service里面没有逻辑,所以开发和管理非常的简单,可以快速应对业务的变化。我们只有更快地变,更容易的变,才能更好地应对变。
Business Model是必须要重用的,一旦发现重用出现问题,那么说明Business Model的识别出现了问题,这是一个我们要重新思考Model的信号。Business Model必须是一个完美的树状,如果不是,也说明Model的识别出了问题。
在实际操作中,Service、Glue Code、Repository不能有逻辑,实际上和很多人的观念是冲突的,认为这个根本做不到。做到这一点需要很多的学习成本,但是一定可以做得到。当发现做不到的时候,可以断定是业务的分析出了问题。比如不该合并的合并了,不该计算的计算了。这个问题一定有办法解决的,做不到都是理由,无非是想早点把自己的工作结束罢了。虽然刚开始会比较困难,一旦把这个观念变成自觉,开发的质量和效率马上就能高好几个级别。
我的游泳教练曾和我说过这些话,我至今记忆犹新:“业余选手,越想从水里浮起来,就越想把头抬起来,身体反而沉下去。只有克服恐惧,把头往水里压下去,身体才能够从水里浮起来。真正专业的习惯往往是和我们日常的行为相反的”。
我们真正想快速的完成代码工作,就要克服自己对时间的恐惧,真正的去研究业务的问题,相关stakeholder的利益,把这个变成我们的习惯。写代码的时候让该出现逻辑的地方出现逻辑,让不该出现的地方不能出现。一旦不该出现的地方出现了逻辑,那么要马上意识到,这个地方是一个坑,这个问题一定和业务的分析不透彻有关系。
很多人可能会把这个做法和Martin Fowler曾经提出过充血模型和贫血模型来比较,和Domain Driven Design来比较,其实没有必要。这个分拆完全是从软件所解决的问题,根据软件架构推导出来的,很多地方和两位前辈的观点是一致的,但是并不完全等同。
以上只是针对单一的Service部署单元的分析,扩展开去,对于其他的部署单元也是类似的。每个单元的下一级都可以认为是Repository,每个单元的上一级都可以认为是User。这些实践在我自己的项目中都有用到,非常的有效,迭代的速度非常的快。很多人担心Business Model建不好,其实没关系,刚开始可以粗糙一点,后续可以慢慢的完善。这个架构已经隔离好了每个部分的变化对其他部分的影响,变化成本都在可控的范围之内。


















