












这么多的CASE,花了大量时间和资源去运行,真能发现BUG吗?CI做到90%的行覆盖率,能发现问题吗?测试用例越来越多,删一些,会不会就发现不了问题了?今天,我们谈谈如何评估测试用例的有效性?

我们的测试用例有两个比较关键的部分:
1)调用被测代码:例如下面的RuleService.getLastRuleByClientId(ClientId)。2)进行结果Check:例如下面的AssertEqual(OrderId,"ABCD1234")。
- TestCaseA
- ...
- RuleService.createRuleByClientId(ClientId,RuleDO);
- StringOrderId=RuleService.getLastRuleByClientId(ClientId);
- ...
- TestCaseB
- ...
- RuleService.createRuleByClientId(ClientId,RuleDO);
- StringOrderId=OrderService.getLastOrderByClientId(ClientId);
- AssertEqual(OrderId,"ABCD1234");
- ...
我们希望一组测试用例不仅能够“触发被测代码的各种分支”,还能够做好结果校验。
- 当业务代码出现问题的时候,测试用例可以发现这个问题,我们就认为这一组测试用例是有效的。
- 当业务代码出现问题的时候,测试用例没能发现这个问题,我们就认为这一组测试用例是无效的。
我们对测试用例有效性的理论建模是:
>> 测试有效性 = 被发现的问题数 / 出现问题的总数
为什么要评估测试用例的有效性?

测试用例有效性评估的方法?
基于故障复盘的模式成本太高,我们希望能够主动创造问题来评估测试用例的有效性。
我们找到了一种衡量“测试有效性”的方法,变异测试(mutation testing):
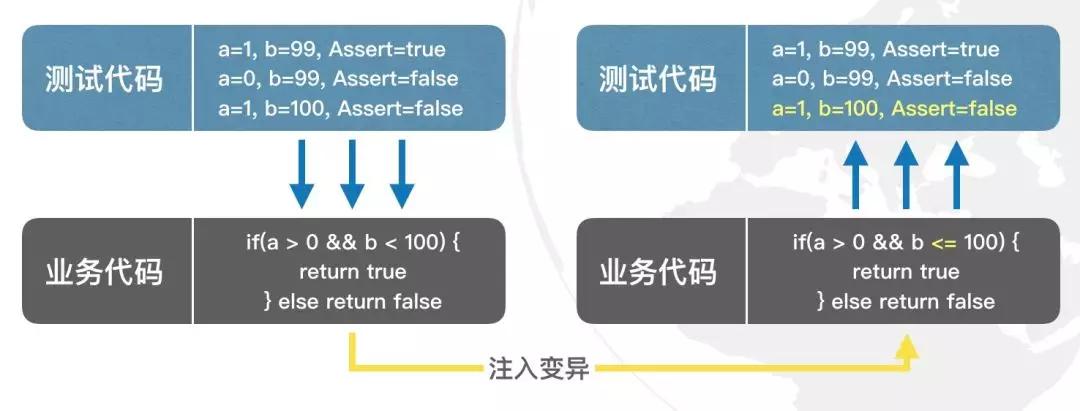
变异测试的例子
我们用了一组测试用例(3个),去测试一个判断分支。而为了证明这一组测试用例的有效性,我们向业务代码中注入变异。我们把b<100的条件改成了b<=100。 我们认为:
- 一组Success的测试用例,在其被测对象发生变化后(注入变异后),应该至少有一个失败。
- 如果这组测试用例仍然全部Success,则这组测试用例的有效性不足。
通过变异测试的方式:让注入变异后的业务代码作为“测试用例”,来测试“测试代码”。
我们实现了多种规则,可以主动的注入下面这些变异:
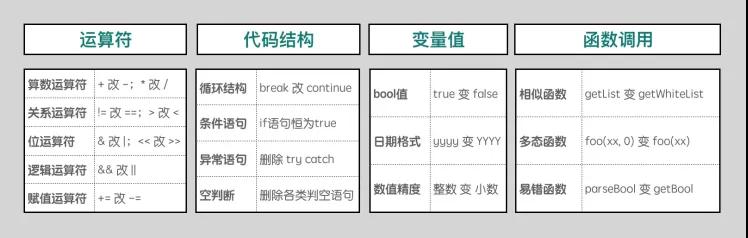
如何优雅的评估测试有效性?
为了全自动的进行测试有效性评估,我们做了一个变异机器人,其主要运作是:
- 往被测代码中写入一个BUG(即:变异);
- 执行测试;
- 把测试结果和无变异时的测试结果做比对,判断是否有新的用例失败;
- 重复1-3若干次,每次注入一个不同的Bug;
- 统计该系统的“测试有效性” 。
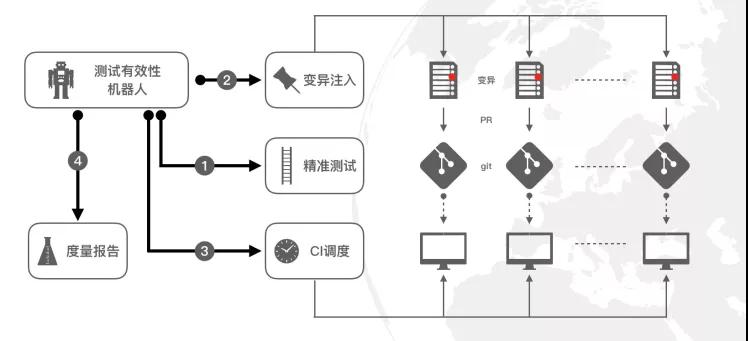
变异机器人的优点:
- 防错上线:变异是单独拉代码分支,且该代码分支永远不会上线,不影响生产。
- 全自动:只需要给出系统代码的git地址,即可进行评估,得到改进报告。
- 高效:数小时即可完成一个系统的测试有效性评估。
- 扩展性:该模式可以支持JAVA以及JAVA以外的多种语系。
- 适用性:该方法不仅适用于单元测试,还适用于其他自动化测试,例如接口测试、功能测试、集成测试。
变异机器人的使用门槛:
- 测试成功率:只会选择通过率100%的测试用例,所对应的业务代码做变异注入。
- 测试覆盖率:只会注入被测试代码覆盖的业务代码,测试覆盖率越高,评估越准确。
高配版变异机器人
我们正在打造的高配版变异机器人拥有三大核心竞争力:
分钟级的系统评估效率
为了保证评估的准确性,100个变异将会执行全量用例100遍,每次执行时间长是一大痛点。
高配版变异机器人给出的解法:
- 并行注入:基于代码覆盖率,识别UT之间的代码覆盖依赖关系,将独立的变异合并到一次自动化测试中。
- 热部署:基于字节码做更新,减少变异和部署的过程。
- 精准测试:基于UT代码覆盖信息,只运行和本次变异相关的UT(该方法不仅适用于UT,还适用于其他自动化测试,例如接口测试、功能测试、集成测试)。
学习型注入经验库
为了避免“杀虫剂”效应,注入规则需要不断的完善。
高配版变异机器人给出的解法:故障学习,基于故障学习算法,不断学习历史的代码BUG,并转化为注入经验。可学习型经验库目前覆盖蚂蚁金服的代码库,明年会覆盖开源社区。
兼容不稳定环境
集成测试环境会存在一定的不稳定,难以判断用例失败是因为“发现了变异”还是“环境出了问题”,导致测试有效性评估存在误差。
高配版变异机器人给出的解法:
- 高频跑:同样的变异跑10次,对多次结果进行统计分析,减少环境问题引起的偶发性问题。
- 环境问题自动定位:接入附属的日志服务,它会基于用例日志/系统错误日志构建的异常场景,自动学习“因环境问题导致的用例失败”,准确区分出用例是否发现变异。
落地效果如何?
我们在蚂蚁金服的一个部门进行了实验,得出了这样的数据:
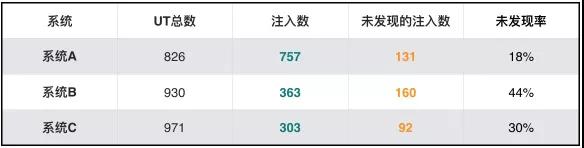
换言之,几个系统的测试有效性为:系统A 72%,系统B 56%,系统C 70%。
测试有效性(%) = 1 - 未发现注入数 / 注入数
更多的测试有效性度量手段
基于代码注入的测试有效性度量,只是其中的一种方法,我们日常会用到的方法有这么几种:
- 代码注入:向代码注入变异,看测试用例是否能发现该问题
- 内存注入:修改API接口的返回内容,看测试用例是否能发现该问题
- 静态扫描:扫描测试代码里是否做了Assert等判断,看Assert场景与被测代码分支的关系
- ... 还有更多其他的度量手段
Meet the testcase again
测试有效性可以作为基石,驱动很多事情向好发展:
- 让测试用例变得更能发现问题。
- 让无效用例可被识别、清理。
- 创造一个让技术人员真正思考如何写好TestCase的质量文化。
- 测试左移与敏捷的前置条件。
- ......
写到最后,想起了同事给我讲的一个有趣的人生经历:
“大二期间在一家出版社编辑部实习,工作内容就是校对文稿中的各种类型的错误。编辑部考核校对质量的办法是,人为的事先在文稿中加入各种类型的错误,然后根据你的错误发现率来衡量,并计算实习工资。”
“你干得咋样?”
“我学习了他们的规则,写了个程序来查错,拿到了第一个满分”
“厉害了...”
“第二个月就不行了,他们不搞错别字了,搞了一堆语法、语义、中心思想的错误... 我就专心干活儿了”
“...”
殊途同归,其致一也。





















