想提升代码搜索效果?首先你得知道怎么才算提升。GitHub 团队创建 CodeSearchNet 语料库,旨在为代码搜索领域提供基准数据集,提升代码搜索结果的质量。
搜索代码进行重用、调用,或者借此查看别人处理问题的方式,是软件开发者日常工作中最常见的任务之一。然而,代码搜索引擎的效果通常不太好,和常规的 web 搜索引擎不同,它无法充分理解你的需求。GitHub 团队尝试使用现代机器学习技术改善代码搜索结果,但很快意识到一个问题:他们无法衡量改善效果。自然语言处理领域有 GLUE 基准,而代码搜索评估领域并没有适合的标准数据集。
因此 GitHub 与 Weights & Biases 公司展开合作,并于昨日推出 CodeSearchNet Challenge 评估环境和排行榜。与此同时,GitHub 还发布了一个大型数据集,以帮助数据科学家构建适合该任务的模型,并提供了多个代表当前最优水平的基线模型。该排行榜使用一个 query 标注数据集来评估代码搜索工具的质量。
- 论文地址:https://arxiv.org/abs/1909.09436
- 语料库及基线模型地址:https://github.com/github/CodeSearchNet
- 挑战赛地址:https://app.wandb.ai/github/codesearchnet/benchmark
CodeSearchNet 语料库
使用专家标注创建足以训练高容量模型的大型数据集成本高昂,不切实际,因此 GitHub 创建了一个质量较低的代理数据集。GitHub 遵循文献 [5, 6, 9, 11] 中的做法,将开源软件中的函数与其对应文档中的自然语言进行匹配。但是,这样做需要执行大量预处理步骤和启发式方法。
通过对常见错误案例进行深入分析,GitHub 团队总结出一些通用法则和决策。
CodeSearchNet 语料库收集过程
GitHub 团队从开源 non-fork GitHub repo 中收集语料,使用 libraries.io 确认所有项目均被至少一个其他项目使用,并按照「流行度」(popularity)对其进行排序(流行度根据 star 和 fork 数而定)。然后,删除没有 license 或者 license 未明确允许重新分发的项目。之后,GitHub 团队使用其通用解析器 TreeSitter 对所有 Go、Java、JavaScript、Python、PHP 和 Ruby 函数(或方法)执行分词操作,并使用启发式正则表达式对函数对应的文档文本进行分词处理。
筛选
为了给 CodeSearchNet Challenge 生成训练数据,GitHub 团队首先考虑了语料库中具备相关文档的函数。这就得到了一组 (c_i , d_i) 对,其中 c_i 是函数,d_i 是对应的文档。为了使数据更加适合代码搜索任务,GitHub 团队执行了一系列预处理步骤:
文档 d_i 被截断,仅保留第一个完整段落,以使文档长度匹配搜索 query,并删除对函数参数和返回值的深入讨论。
删除 d_i 短于三个 token 的对,因为此类注释无法提供有效信息。
删除 c_i 实现少于三行的对,因为它们通常包含未实现的方法、getters、setters 等。
删除名称中包含子字符串「test」的函数。类似地,删除构造函数和标准扩展方法,如 Python 中的 __str__、Java 中的 toString。
识别数据集中的(近似)重复函数,仅保留其中一个副本,从而删除数据集中的重复项。这就消除了出现多个版本自生成代码和复制粘贴的情况。
筛选后的语料库和数据抽取代码详见:https://github.com/github/CodeSearchNet
数据集详情
该数据集包含 200 万函数-文档对、约 400 万不具备对应文档的函数(见下表 1)。GitHub 团队将该数据集按照 80-10-10 的比例划分为训练集/验证集/测试集,建议用户按照该比例使用此数据集。
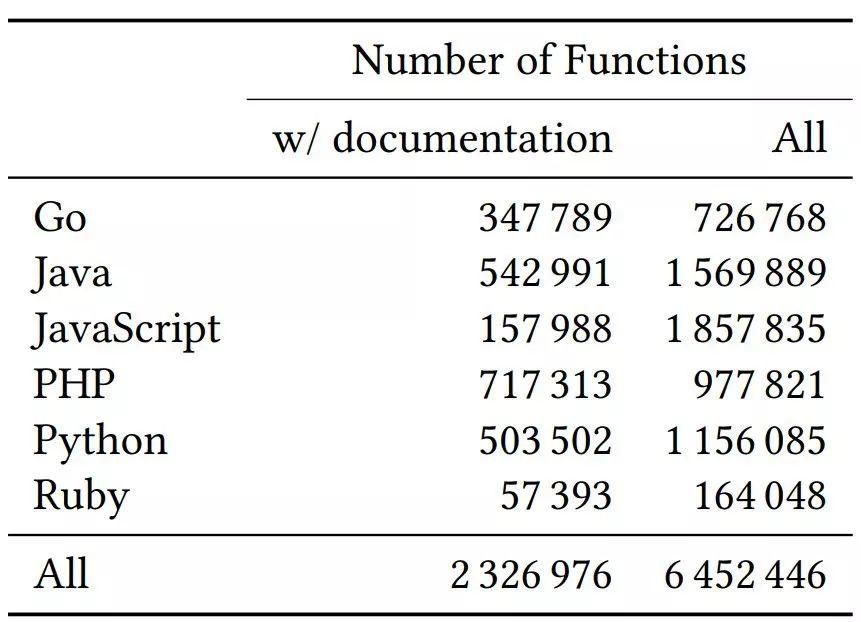
表 1:数据集详情
局限性
该数据集噪声很大。首先,文档与 query 存在本质区别,它们使用的是不同的语言形式。文档通常是代码作者在写代码的同时写成的,更倾向于使用同样的词汇,这与搜索 query 存在差异。其次,尽管 GitHub 团队在创建数据集的过程中执行了数据清洗,但他们无法得知每个文档 d_i 描述对应代码段 c_i 的精确程度。最后,一些文档是用非英语文本写成的,而 CodeSearchNet Challenge 评估数据集主要关注的是英文 query。
CodeSearchNet 基线模型
基于 GitHub 之前在语义代码搜索领域的努力,该团队发布了一组基线模型,这些模型利用现代技术学习序列(包括 BERT 类的自注意力模型),帮助数据科学家开启代码搜索。
和之前的工作一样,GitHub 团队使用代码和 query 的联合嵌入来实现神经搜索系统。该架构对每个输入(自然或编程)语言使用一个编码器,并训练它们使得输入映射至一个联合向量空间。其训练目标是将代码及其对应语言映射至邻近的向量,这样我们就可以嵌入 query 实现搜索,然后返回嵌入空间中「邻近」的代码段集合。
考虑 query 和代码之间更多交互的较复杂模型当然性能更好,但是为每个 query 或代码段生成单个向量可以实现更高效的索引和搜索。
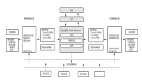
为了学习这些嵌入函数,GitHub 团队在架构中加入了标准序列编码器模型,如图 3 所示。首先,根据输入序列的语义对其执行预处理:将代码 token 中的标识符分割为子 token(如变量 camelCase 变成了两个子 token:camel 和 case),使用字节对编码(byte-pair encoding,BPE)分割自然语言 token。
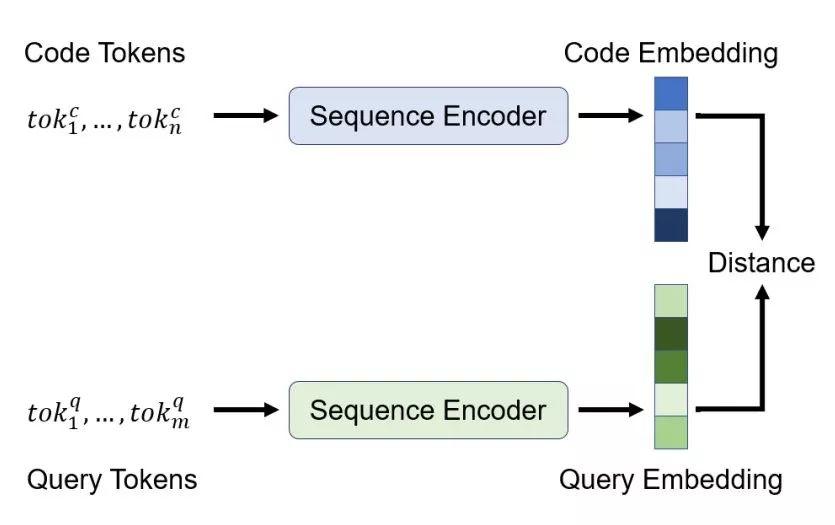
图 3:模型架构概览
然后使用以下架构之一处理 token 序列,以获得(语境化的)token 嵌入。
- 神经词袋模型:每个(子)token 都被转换为可学习嵌入(向量表示)。
- 双向 RNN 模型:利用 GRU 单元总结输入序列。
- 一维卷积神经网络:用于处理输入 token 序列。
- 自注意力模型:其多头注意力用于计算序列中每个 token 的表示。
之后,使用池化函数将这些 token 嵌入组合为一个序列嵌入,GitHub 团队已经实现了 mean/max-pooling 和类注意力的加权和机制。
下图展示了基线模型的通用架构:
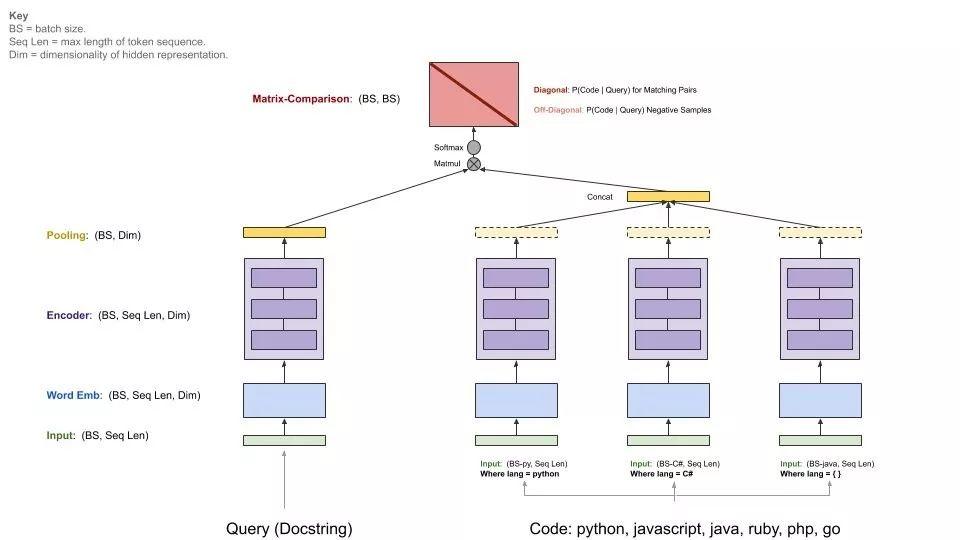
CodeSearchNet 挑战赛
为了评估代码搜索模型,GitHub 团队收集了一组代码搜索 query,并让程序员标注 query 与可能结果的关联程度。他们首先从必应中收集了一些常见搜索 query,结合 StaQC 中的 query 一共获得 99 个与代码概念相关的 query(GitHub 团队删除了 API 文档查询方面的问题)。
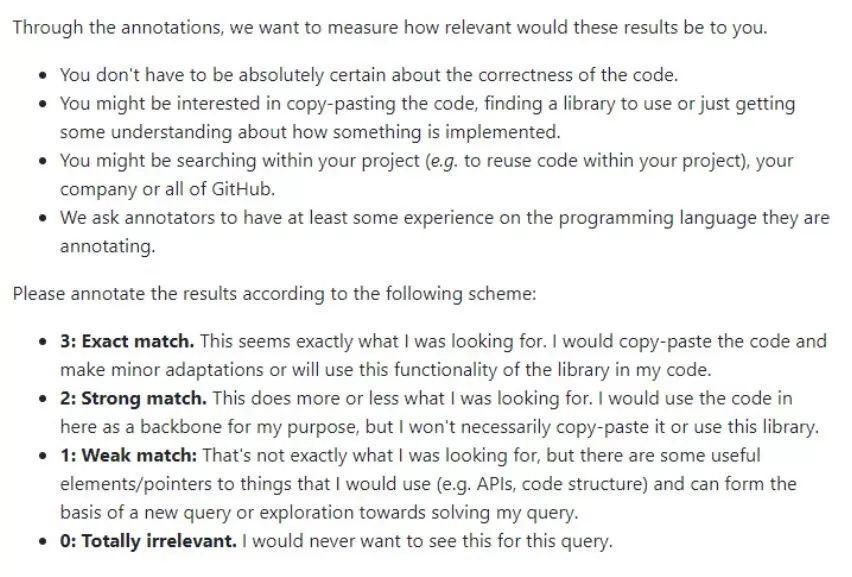
图 1:标注者指导说明
之后,GitHub 团队使用标准 Elasticsearch 和基线模型,从 CodeSearchNet 语料库中为每个 query 获得 10 个可能的结果。最后,GitHub 团队请程序员、数据科学家和机器学习研究者按照 [0, 3] 的标准标注每个结果与 query 的关联程度(0 表示「完全不相关」,3 表示「完全匹配」)。
未来,GitHub 团队想在该评估数据集中纳入更多语言、query 和标注。接下来几个月,他们将持续添加新的数据,为下一个版本的 CodeSearchNet Challenge 制作扩展版数据集。