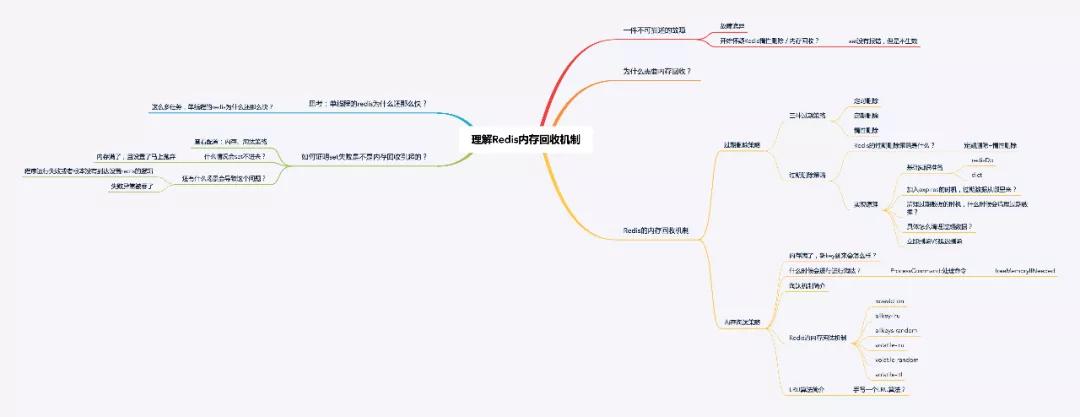
之前看到过一道面试题:Redis 的过期策略都有哪些?内存淘汰机制都有哪些?手写一下 LRU 代码实现?
图片来自 Pexels
笔者结合在工作上遇到的问题学习分析,希望看完这篇文章能对大家有所帮助。
从一次不可描述的故障说起
问题描述:一个依赖于定时器任务的生成的接口列表数据,时而有,时而没有。
怀疑是 Redis 过期删除策略
排查过程长,因为手动执行定时器,Set 数据没有报错,但是 Set 数据之后不生效。
Set 没报错,但是 Set 完再查的情况下没数据,开始怀疑 Redis 的过期删除策略(准确来说应该是 Redis 的内存回收机制中的数据淘汰策略触发内存上限淘汰数据),导致新加入 Redis 的数据都被丢弃了。
最终发现故障的原因是因为配置错了,导致数据写错地方,并不是 Redis 的内存回收机制引起。
通过这次故障后思考总结,如果下一次遇到类似的问题,在怀疑 Redis 的内存回收之后,如何有效地证明它的正确性?如何快速证明猜测的正确与否?以及什么情况下怀疑内存回收才是合理的呢?
下一次如果再次遇到类似问题,就能够更快更准地定位问题的原因。另外,Redis 的内存回收机制原理也需要掌握,明白是什么,为什么。
花了点时间查阅资料研究 Redis 的内存回收机制,并阅读了内存回收的实现代码,通过代码结合理论,给大家分享一下 Redis 的内存回收机制。
为什么需要内存回收?
原因有如下两点:
- 在 Redis 中,Set 指令可以指定 Key 的过期时间,当过期时间到达以后,Key 就失效了。
- Redis 是基于内存操作的,所有的数据都是保存在内存中,一台机器的内存是有限且很宝贵的。
基于以上两点,为了保证 Redis 能继续提供可靠的服务,Redis 需要一种机制清理掉不常用的、无效的、多余的数据,失效后的数据需要及时清理,这就需要内存回收了。
Redis 的内存回收机制
Redis 的内存回收主要分为过期删除策略和内存淘汰策略两部分。
过期删除策略
删除达到过期时间的 Key。
①定时删除
对于每一个设置了过期时间的 Key 都会创建一个定时器,一旦到达过期时间就立即删除。
该策略可以立即清除过期的数据,对内存较友好,但是缺点是占用了大量的 CPU 资源去处理过期的数据,会影响 Redis 的吞吐量和响应时间。
②惰性删除
当访问一个 Key 时,才判断该 Key 是否过期,过期则删除。该策略能最大限度地节省 CPU 资源,但是对内存却十分不友好。
有一种极端的情况是可能出现大量的过期 Key 没有被再次访问,因此不会被清除,导致占用了大量的内存。
在计算机科学中,懒惰删除(英文:lazy deletion)指的是从一个散列表(也称哈希表)中删除元素的一种方法。
在这个方法中,删除仅仅是指标记一个元素被删除,而不是整个清除它。被删除的位点在插入时被当作空元素,在搜索之时被当作已占据。
③定期删除
每隔一段时间,扫描 Redis 中过期 Key 字典,并清除部分过期的 Key。该策略是前两者的一个折中方案,还可以通过调整定时扫描的时间间隔和每次扫描的限定耗时,在不同情况下使得 CPU 和内存资源达到最优的平衡效果。
在 Redis 中,同时使用了定期删除和惰性删除。
过期删除策略原理
为了大家听起来不会觉得疑惑,在正式介绍过期删除策略原理之前,先给大家介绍一点可能会用到的相关 Redis 基础知识。
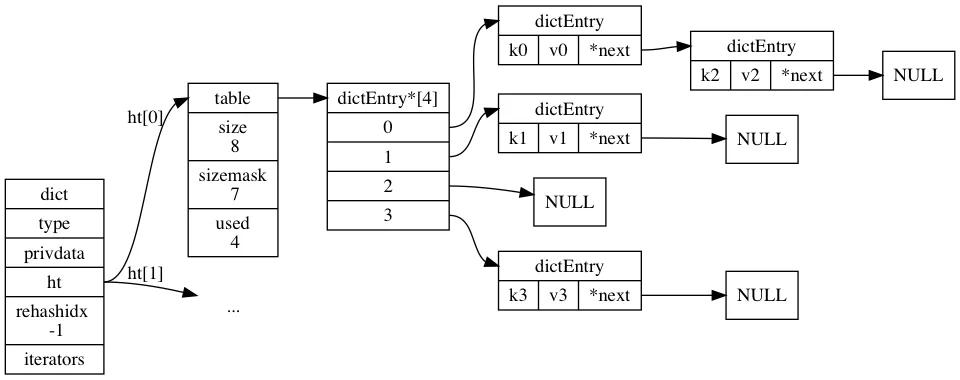
①RedisDB 结构体定义
我们知道,Redis 是一个键值对数据库,对于每一个 Redis 数据库,Redis 使用一个 RedisDB 的结构体来保存,它的结构如下:
typedef struct redisDb {
dict *dict; /* 数据库的键空间,保存数据库中的所有键值对 */
dict *expires; /* 保存所有过期的键 */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* 数据库ID字段,代表不同的数据库 */
long long avg_ttl; /* Average TTL, just for stats */
} redisDb;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
从结构定义中我们可以发现,对于每一个 Redis 数据库,都会使用一个字典的数据结构来保存每一个键值对,dict 的结构图如下:
以上就是过期策略实现时用到比较核心的数据结构。程序=数据结构+算法,介绍完数据结构以后,接下来继续看看处理的算法是怎样的。
②expires 属性
RedisDB 定义的第二个属性是 expires,它的类型也是字典,Redis 会把所有过期的键值对加入到 expires,之后再通过定期删除来清理 expires 里面的值。
加入 expires 的场景有:
- Set 指定过期时间 expire,如果设置 Key 的时候指定了过期时间,Redis 会将这个 Key 直接加入到 expires 字典中,并将超时时间设置到该字典元素。
- 调用 expire 命令,显式指定某个 Key 的过期时间。
- 恢复或修改数据,从 Redis 持久化文件中恢复文件或者修改 Key,如果数据中的 Key 已经设置了过期时间,就将这个 Key 加入到 expires 字典中。
以上这些操作都会将过期的 Key 保存到 expires。Redis 会定期从 expires 字典中清理过期的 Key。
③Redis 清理过期 Key 的时机
Redis 在启动的时候,会注册两种事件,一种是时间事件,另一种是文件事件。时间事件主要是 Redis 处理后台操作的一类事件,比如客户端超时、删除过期 Key;文件事件是处理请求。
在时间事件中,Redis 注册的回调函数是 serverCron,在定时任务回调函数中,通过调用 databasesCron 清理部分过期 Key。(这是定期删除的实现。)
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData)
{
…
/* Handle background operations on Redis databases. */
databasesCron();
...
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
每次访问 Key 的时候,都会调用 expireIfNeeded 函数判断 Key 是否过期,如果是,清理 Key。(这是惰性删除的实现)
robj *lookupKeyRead(redisDb *db, robj *key) {
robj *val;
expireIfNeeded(db,key);
val = lookupKey(db,key);
...
return val;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
每次事件循环执行时,主动清理部分过期 Key。(这也是惰性删除的实现)
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}
}
void beforeSleep(struct aeEventLoop *eventLoop) {
...
/* Run a fast expire cycle (the called function will return
- ASAP if a fast cycle is not needed). */
if (server.active_expire_enabled && server.masterhost == NULL)
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST);
...
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
④过期策略的实现
我们知道,Redis 是以单线程运行的,在清理 Key 时不能占用过多的时间和 CPU,需要在尽量不影响正常的服务情况下,进行过期 Key 的清理。
过期清理的算法如下:
- server.hz 配置了 serverCron 任务的执行周期,默认是 10,即 CPU 空闲时每秒执行十次。
- 每次清理过期 Key 的时间不能超过 CPU 时间的 25%:timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100。
- 比如,如果 hz=1,一次清理的最大时间为 250ms,hz=10,一次清理的最大时间为 25ms。
- 如果是快速清理模式(在 beforeSleep 函数调用),则一次清理的最大时间是 1ms。
- 依次遍历所有的 DB。
- 从 DB 的过期列表中随机取 20 个 Key,判断是否过期,如果过期,则清理。
- 如果有 5 个以上的 Key 过期,则重复步骤 5,否则继续处理下一个 DB。
- 在清理过程中,如果达到 CPU 的 25% 时间,退出清理过程。
从实现的算法中可以看出,这只是基于概率的简单算法,且是随机的抽取,因此是无法删除所有的过期 Key,通过调高 hz 参数可以提升清理的频率,过期 Key 可以更及时的被删除,但 hz 太高会增加 CPU 时间的消耗。
⑤删除 Key
Redis 4.0 以前,删除指令是 del,del 会直接释放对象的内存,大部分情况下,这个指令非常快,没有任何延迟的感觉。
但是,如果删除的 Key 是一个非常大的对象,比如一个包含了千万元素的 Hash,那么删除操作就会导致单线程卡顿,Redis 的响应就慢了。
为了解决这个问题,在 Redis 4.0 版本引入了 unlink 指令,能对删除操作进行“懒”处理,将删除操作丢给后台线程,由后台线程来异步回收内存。
实际上,在判断 Key 需要过期之后,真正删除 Key 的过程是先广播 expire 事件到从库和 AOF 文件中,然后在根据 Redis 的配置决定立即删除还是异步删除。
如果是立即删除,Redis 会立即释放 Key 和 Value 占用的内存空间,否则,Redis 会在另一个 BIO 线程中释放需要延迟删除的空间。
小结:总的来说,Redis 的过期删除策略是在启动时注册了 serverCron 函数,每一个时间时钟周期,都会抽取 expires 字典中的部分 Key 进行清理,从而实现定期删除。
另外,Redis 会在访问 Key 时判断 Key 是否过期,如果过期了,就删除,以及每一次 Redis 访问事件到来时,beforeSleep 都会调用 activeExpireCycle 函数,在 1ms 时间内主动清理部分 Key,这是惰性删除的实现。
Redis 结合了定期删除和惰性删除,基本上能很好的处理过期数据的清理,但是实际上还是有点问题的。
如果过期 Key 较多,定期删除漏掉了一部分,而且也没有及时去查,即没有走惰性删除,那么就会有大量的过期 Key 堆积在内存中,导致 Redis 内存耗尽。
当内存耗尽之后,有新的 Key 到来会发生什么事呢?是直接抛弃还是其他措施呢?有什么办法可以接受更多的 Key?
内存淘汰策略
Redis 的内存淘汰策略,是指内存达到 maxmemory 极限时,使用某种算法来决定清理掉哪些数据,以保证新数据的存入。
Redis 的内存淘汰机制如下:
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间(server.db[i].dict)中,移除最近最少使用的 Key(这个是最常用的)。
- allkeys-random:当内存不足以容纳新写入数据时,在键空间(server.db[i].dict)中,随机移除某个 Key。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间(server.db[i].expires)中,移除最近最少使用的 Key。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间(server.db[i].expires)中,随机移除某个 Key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间(server.db[i].expires)中,有更早过期时间的 Key 优先移除。
在配置文件中,通过 maxmemory-policy 可以配置要使用哪一个淘汰机制。
①什么时候会进行淘汰?
Redis 会在每一次处理命令的时候(processCommand 函数调用 freeMemoryIfNeeded)判断当前 Redis 是否达到了内存的最大限制,如果达到限制,则使用对应的算法去处理需要删除的 Key。
伪代码如下:
int processCommand(client *c)
{
...
if (server.maxmemory) {
int retval = freeMemoryIfNeeded();
}
...
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
②LRU 实现原理
在淘汰 Key 时,Redis 默认最常用的是 LRU 算法(Latest Recently Used)。
Redis 通过在每一个 redisObject 保存 lRU 属性来保存 Key 最近的访问时间,在实现 LRU 算法时直接读取 Key 的 lRU 属性。
具体实现时,Redis 遍历每一个 DB,从每一个 DB 中随机抽取一批样本 Key,默认是 3 个 Key,再从这 3 个 Key 中,删除最近最少使用的 Key。
实现伪代码如下:
keys = getSomeKeys(dict, sample)
key = findSmallestIdle(keys)
remove(key)
- 1.
- 2.
- 3.
3 这个数字是配置文件中的 maxmeory-samples 字段,也是可以设置采样的大小,如果设置为 10,那么效果会更好,不过也会耗费更多的 CPU 资源。
以上就是 Redis 内存回收机制的原理介绍,了解了上面的原理介绍后,回到一开始的问题,在怀疑 Redis 内存回收机制的时候能不能及时判断故障是不是因为 Redis 的内存回收机制导致的呢?
回到问题原点
如何证明故障是不是由内存回收机制引起的?根据前面分析的内容,如果 Set 没有报错,但是不生效,只有两种情况:
- 设置的过期时间过短,比如,1s。
- 内存超过了最大限制,且设置的是 noeviction 或者 allkeys-random。
因此,在遇到这种情况,首先看 Set 的时候是否加了过期时间,且过期时间是否合理,如果过期时间较短,那么应该检查一下设计是否合理。
如果过期时间没问题,那就需要查看 Redis 的内存使用率,查看 Redis 的配置文件或者在 Redis 中使用 Info 命令查看 Redis 的状态,maxmemory 属性查看最大内存值。
如果是 0,则没有限制,此时是通过 total_system_memory 限制,对比 used_memory 与 Redis 最大内存,查看内存使用率。
如果当前的内存使用率较大,那么就需要查看是否有配置最大内存,如果有且内存超了,那么就可以初步判定是内存回收机制导致 Key 设置不成功。
还需要查看内存淘汰算法是否 noeviction 或者 allkeys-random,如果是,则可以确认是 Redis 的内存回收机制导致。
如果内存没有超,或者内存淘汰算法不是上面的两者,则还需要看看 Key 是否已经过期,通过 TTL 查看 Key 的存活时间。
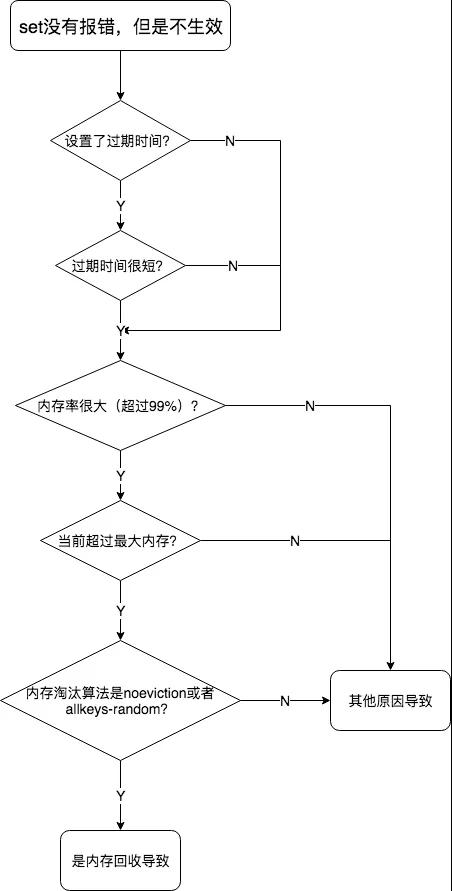
如果运行了程序,Set 没有报错,则 TTL 应该马上更新,否则说明 Set 失败,如果 Set 失败了那么就应该查看操作的程序代码是否正确了。
总结
Redis 对于内存的回收有两种方式,一种是过期 Key 的回收,另一种是超过 Redis 的最大内存后的内存释放。
对于第一种情况,Redis 会在:
- 每一次访问的时候判断 Key 的过期时间是否到达,如果到达,就删除 Key。
- Redis 启动时会创建一个定时事件,会定期清理部分过期的 Key,默认是每秒执行十次检查,每次过期 Key 清理的时间不超过 CPU 时间的 25%。
即若 hz=1,则一次清理时间最大为 250ms,若 hz=10,则一次清理时间最大为 25ms。
对于第二种情况,Redis 会在每次处理 Redis 命令的时候判断当前 Redis 是否达到了内存的最大限制,如果达到限制,则使用对应的算法去处理需要删除的 Key。
看完这篇文章后,你能回答文章开头的面试题了吗?