近期秋招进入高峰期,28号学校有一个秋招大型招聘会,本来想在网上爬一下自己专业的招聘岗位,结果检索结果寥寥无几(摊手),于是我就无奈的爬取并分析了一波我准备转行的大数据行业的就业行情。
爬虫的基本思路
- 在前程无忧官网检索“大数据”的结果中,每条检索结果详情对应的URL存在a标签的href属性中,通过组合选择器可以找到每条检索结果详情的URL。
- 前程无忧的招聘岗位信息数据固定的放在HTML的各个标签内,通过id选择器、标签选择器和组合选择器可以诸如公司名、岗位名称和薪资等11个字段的数据。
- 基于上述1和2,可以通过解析检索“大数据”得到的URL得到其HTML,再从此HTML中的具体位置的a标签得到每个岗位的详情对应的URL;然后解析每个岗位的详情对应的URL得到其HTML,再从结果HTML的具体位置找到每个岗位的详情。具体位置怎么确定呢?通过组合选择器!
前程无忧爬虫具体代码
直接贴代码容易破坏我的排版,具体代码见:https://github.com/cugwhzenith/SpiderOf51job.git,其中SpiderOf51job.py就是爬虫代码,关键点的操作见注释。其他的代码是对爬虫代码的处理。
爬虫结果
爬虫结果我是以csv的格式存储的,看起来不太直观,所以我打算用wordcloud和直方图来可视化爬虫的结果。

爬虫结果处理
一般来说,应聘者对一个工作的地点、工作名称、薪资和需要的技术最为关心,刚好上述爬虫的结果包含了这四个字段。
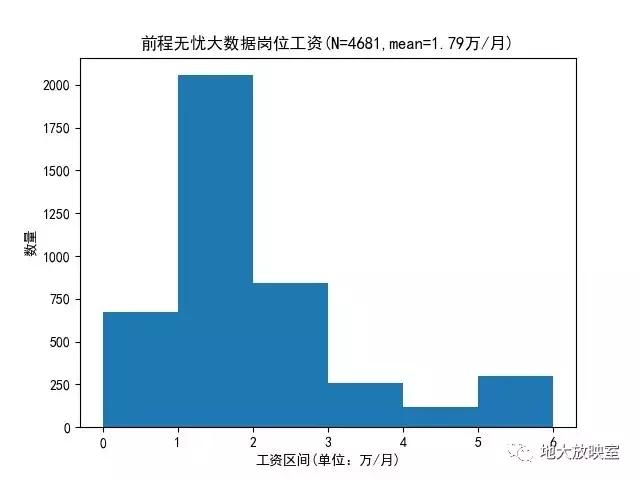
1、薪资结果的处理。在爬虫结果中,薪资在第二列,一般是诸如“1-2万/月”、“20万/年”和“500/天”的结果,先判断每个结果的最后一个字符是“年”、“月”和“天”的哪一个,确定处理的逻辑之后,再用re.sub函数将除了数字之外的字符替换为空格,最后对结果求均值就到了了每个结果的均值。具体处理见wordcloudPlotSalary.py 。
2、需要的技术的处理。考虑到大数据要使用的技术绝大多数由外国人开发,如实我把大数据要使用的技术这一字段的中文全部替换为空格,然后用jieba剔除掉一些无意义的助词,就得到了大数据要使用的技术的词云图。具体代码见wordcloudPlotJobinfo.py 。

3、工作地点和职位名称的处理和上述2类似参见wordcloudPlotPlace.py和wordcloudPlotName.py,此处不再赘余,直接放结果。
工作地点词云:

职位名称词云:

总结
- 前程无忧上大数据相关岗位出现频率最高的是:大数据开发工程师
- 开出的平均工资:18K/月
- 大数据就业岗位最多的城市是:上海、广州和深圳、
- 大数据工作最吃香的技能是:Hadoop、SQL和Python