对许多人来说,依赖关系是一场噩梦。一些人甚至认为它们是技术债务。管理你的软件的库列表是一种可怕的体验。自动更新依赖项?-这听起来像是在说胡话。
请继续关注我,因为我将帮助你更好地掌握一些你在实践中无法摆脱的东西——除非你非常富有和有才华,能够在没有他人代码的情况下生活。
首先,我们需要清楚地了解一些有关依赖关系的知识: 依赖关系有两种类型。Donald Stuff几年前写的关于这个主题的文章比我要写的都好。简单一点来说,它们是依赖于外部代码的两种类型的代码包:应用程序和库。
库依赖
Python库应该以一种通用的方式来指定它们的依赖关系。一个库不应该要求requests 2.1.5:这没有意义。如果每个库都需要不同版本的requests,我们就不能同时使用它们。
库需要根据版本号的范围来声明依赖关系。要求请求requests>=2是正确的。如果你知道requests2.x不适用于该库,那么要求 requests>=1,<2 也是正确的。你的版本范围定义正在解决的问题是你的代码和依赖项之间的API兼容性问题———没有其他问题。这是库尽可能使用语义版本控制的一个很好的理由。
因此,依赖关系应该写在setup.py中,类似于:

这样,任何应用程序都可以轻松地使用库并与其他应用程序共存。
应用程序依赖关系
应用程序只是库的一种特殊情况。它们不打算被其他应用程序库重用(导入)——尽管在实践中没有什么可以阻止它。
最后,这意味着你应该像为一个库指定依赖关系一样来在应用程序的setup.py中指定依赖关系。
其主要区别在于,一个应用程序通常部署在生产环境中以提供其服务。部署需要是可复用的。为此,你不能仅仅依赖于setup.py:因为请求的依赖关系范围太宽。在重新部署应用程序时,你希望随时都可以随意更改版本。
因此,你需要一个不同的版本管理机制来处理部署,而不仅仅是setup.py。
pipenv在其文档中有一节很好地总结了这一点。它将依赖关系类型划分为抽象依赖项和具体依赖项: 抽象依赖项基于范围(例如 库),而具体依赖项是用精确的版本(例如应用程序部署)指定的——正如我们在这里看到的。
处理部署
requirements.txt文件长期以来一直被用来解决应用程序部署的可复用性问题。它的格式通常是这样的:

每个库都将自己指定为微版本。这确保你的每个部署都将安装相同版本的依赖项。使用requirements.txt是一个简单的解决方案,也是实现可复用部署的第一步。然而,这还不够。
实际上,虽然你可以指定你想要的requests的版本,但是如果requests依赖于urllib3,那么这将会使pip安装urllib 2.1或urllib 2.2。你无法知道哪一个会被安装,这并不能使你的部署100%可重用。
当然,你可以在你的requirements.txt中复制所有的requests依赖项,但那将是疯狂的做法!
一个应用程序依赖关系树有时可能非常深入和复杂。
有各种各样的技巧可以用来修复这个限制,但是真正的救星是pipenv和poetry。它们解决这个问题的方法类似于其他编程语言中的许多包管理器。它们生成一个锁文件,其中包含所有已安装的依赖项(以及它们自己的依赖项等)的列表和版本号。这可以确保部署是100%可复用的。
请查看它们的文档,了解如何设置和使用它们!
处理依赖项更新
现在,你已经有了锁文件,它可以确保你的部署在短时间内是可复用的,那么你就有了另一个问题。你如何确保你的依赖项是最新的?这是一个真正的安全问题,而且保持版本落后的话,你可能也会错过bug修复和进行优化的机会。
如果你的项目托管在GitHub上,Dependabot是解决这个问题的一个很好的解决方案。当你的锁文件中列出的库的一个新版本可用时,在存储库上启用此应用程序将会自动创合并请求。例如,如果你已经使用redis 3.3.6部署了你的应用程序,当新版本redis 3.3.7发布时,Dependabot将会创建一个更新到redis 3.3.7的合并请求。此外,Dependabot还支持requirements.txt、 pipenv和poetry!
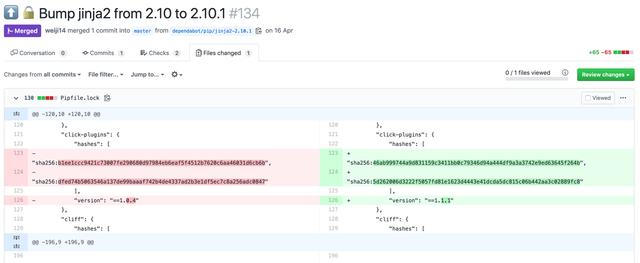
Dependabot正在为你更新jinja2
自动部署更新
快要成功了。你有一个机器人,它让你知道你的项目需要的一个库的新版本是可用的。
一旦创建了合并请求,你的持续集成系统就会启动、部署你的项目并运行测试。如果一切正常,你的合并请求就可以被合并了。但是在这个过程中真的需要你参与吗?
除非你个人特别反感某个特定的版本号——“天哪,我讨厌以3结尾的版本。遇见它总是运气不好。——或者除非你没有自动化测试,否则你,人类,是无用的。这个合并完全可以是自动化的。
这就是Mergify发挥作用的地方。Mergify是一个GitHub应用程序,它允许你定义关于如何合并合并请求的精确规则。下面是我在每个项目中都使用的一个规则:
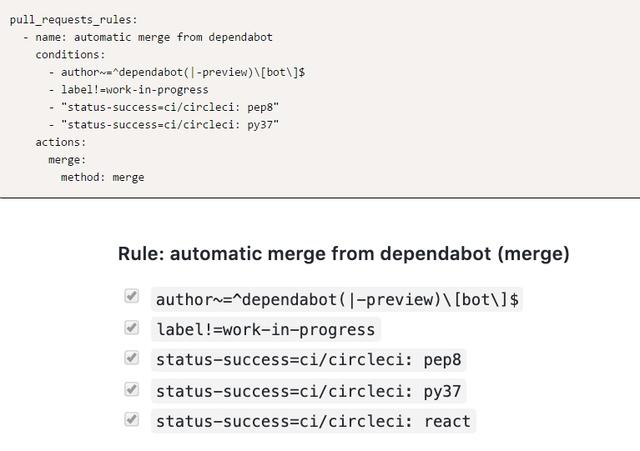
当规则完全匹配时,Mergify会进行报告。
一旦你的持续集成系统通过,Mergify就会为你合并该合并请求。
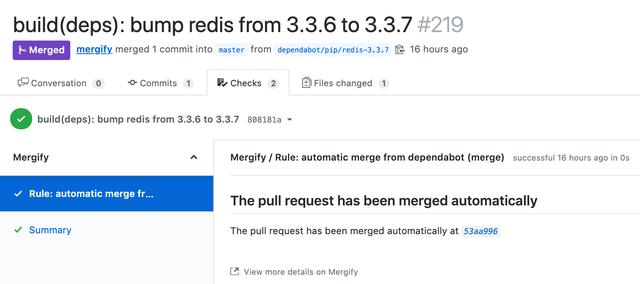
然后,你就可以自动触发你的部署钩子来更新你的生产部署,并立即安装新的库版本。这将使得你的应用程序总是使用较新的库进行更新,并且不会落后于几年的发行版。
如果出现任何错误,你仍然能够从Dependabot中恢复提交——如果你希望使用一个Mergify规则,你也可以自动化恢复提交。
题外话
对我来说,这就是依赖关系管理生命周期目前的状态。虽然这对Python非常适用,但它也可以应用于使用了类似模式的许多其他语言,比如Node和npm。