【51CTO.com原创稿件】1、背景
文本匹配是自然语言处理中的一个核心问题,它不同于MT、MRC、QA 等end-to-end型任务,一般是以文本相似度计算的形式在应用系统中起核心支撑作用。它可以应用于各种类型的自然语言处理任务中,例如信息检索、搜索引擎、问答系统、信息流推荐、复述问题、知识检索、机器翻译等。
之所以文本匹配的适用范围如此之广,是因为很多NLP任务本质上可以抽象为一个文本匹配问题,比如说复述问题可以归结为两个同义句的匹配,信息检索就是一个搜索词和文档资源的匹配过程,问答系统的核心问题是将用户输入的问题和最佳的候选答案匹配起来,对话系统可以归结为前一句对话和下一句回复的匹配。本文主要介绍DSSM文本匹配模型在苏宁商品语义召回上的应用。
使用文本匹配模型进行语义召回是在苏宁易购主搜系统对一些未知词或者语义不明甚至有错字少字的用户搜索词返回结果不好的情况下提出的。如下图所示,用户漏了挂烫机里的挂字,并且后面输入了有一定干扰作用的具体型号词,导致没有返回结果。scolib品牌的耳机没有在苏宁进行销售,因此scolib这个英文词属于未知词。
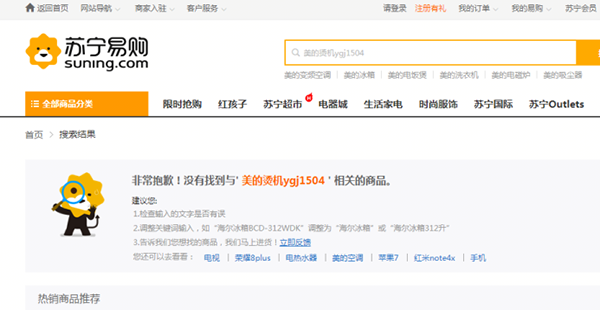
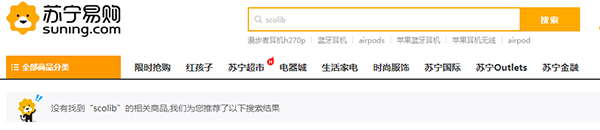
图一: 未知、错字少字等情况搜索效果展示
从以上两种召回效果较差的情况可以看出,以文本相似度为核心的召回策略虽然能在大部分情况下保证较高的精度,但是无法解决前文所提到的特殊情况。因此采用语义模型,获取与用户query的语义相近的商品是非常有必要的。
深度文本匹配可以总结为四种:1、单语义模型 2、多语义模型 3、匹配矩阵模型 4、深层次句子模型。其中单语义模型用全连接、CNN、 RNN或其他的特征提取器得到两个句子的深层语义向量,再计算两者的匹配度;多语义模型从多颗粒的角度解读句子,考虑到句子内部的局部结构;匹配矩阵模型直接捕捉匹配信号,将词间的匹配信号作为灰度图,再用深度网络提取特征,更精细的处理句子中的联系;深层次的句子间模型用更精细的结构去挖掘句子内和句子间不同单词之间的联系,得到更好的效果5。
近几年来文本匹配相关的论文层出不穷,对句子对结构的处理越来越精细,模型复杂度快速上升6。虽然论文里的实验SOTA效果不断刷新, 但是完整的训练步骤,甚至是单次预测所需时间也是非常长的。线上生产环境以保证用户体验为第一要务,需要快速可靠准确的文本匹配策略7。同时,苏宁有海量的每日更新的query-doc对文本语料,query是用户的搜索词,doc为系统返回的商品title。想要在有限的硬件资源下,能容忍的训练调试时间范围内实现对主站全商品类目亿级别语料进行训练,需要一个可调参数规模不大,待召回千万级商品集的语义向量可以离线提前算好,模型效果能随着语料规模增大而提高的模型。综上,我们选择LSTM-DSSM模型作为商品语义召回系统的核心。
2、LSTM-DSSM模型
2.1 模型输入
在商品语义召回业务里,待匹配的DOC是商品标题,而标题不可避免的会包含型号词如GTX2060这种。如果对输入按字处理,则会强制模型学习2、0、6、0四个数字是一种固定搭配,对于短文本还好,可一些电子产品的型号词数字加字母长达十几位,而真正的核心中文词也许只有短短几位,这就产生了非常严重的干扰效果。而且对于包含几十个字的长标题,就需要同等长度的LSTM进行特征提取,造成参数过多,增加了模型学习成本。综上,本模型放弃字token作为输入,而是使用词token。
我们参考了迁移学习的思想,不是简单的随机初始化词token的Embedding向量,而是以亿级别的苏宁商品Title为语料,先使用HanLP分词器进行分词处理。将分词所得的词token按顺序编码,生成后续模型需要的词典。并在spark平台上,用其提供的word2vec模型接口训练词token语料。这样就能得到每个词token的语义向量,并当作为模型的输入。
考虑到词典和各个词的语义向量的生成,是一劳永逸的工作,通常不需要再变动,所以使用了非常大规模的语料,spark环境设置300台机器,训练时间接近8个小时,最后的效果还是满意的。
2.2 模型架构
商品语义召回系统所用DSSM在如下图所示的基本模型基础上,增加了两处针对业务效果的改进。
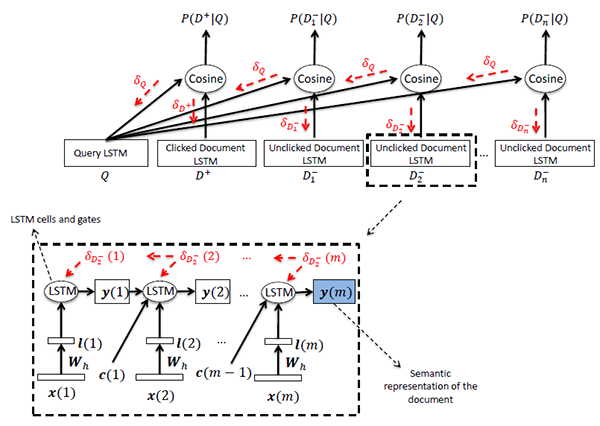
图二: DSSM基础模型示意图
首先对于匹配商品召回这种具体的业务场景,商品的品牌和品类是非常重要的特征。如果能匹配到正确的品类、品牌,那最终效果肯定不会差。因此为了能直接利用这类特征,采取了非常直接的方法,如下图所示:
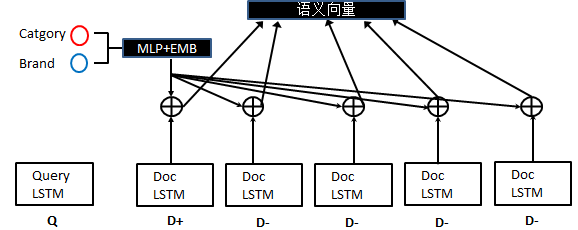
图三: 频偏、品类特征使用示意图
由上图可见,品牌、品类通过Embedding表示学习层、两层MLP直接映射成和LSTM提取的语义向量同一维度的向量,再将两者相加得到最终的语义向量表示。
第二,引入了注意力机制,目的是解决诸如洗衣机返回较多洗衣机配件的情况,提升核心词洗衣机的权重,这样能极大的改善召回效果,具体使用方式如下图所示8:

图四: 注意力机制使用示意图
由以上两图可以看出,有两种参考了经典乘性注意力机制的方法,第一种是用query的最后一个LSTM单元输出的隐层向量作为context,分别与doc每个时间步骤的隐层向量作点积计算,计算结果作为权重。每个时间步骤的向量乘以权重再求和就可以作为最终的语义向量。第二种则是求得query每个时间步骤的权重,然后得到query最终语义向量,将其与doc最后单元输出并联或者相加,作为最终商品语义向量。
2.3 模型输出
模型的输出作为语义召回系统的输入,主要由两个方面组成。第一,是实时生成搜索词query语义向量的模块。具体做法要考虑到实际业务场景一次只输入一条query的情况,改造模型输入接口和具体处理方式,读取已经训练好的模型参数,重新保存为tf-serving服务框架所需要的pb格式模型。第二,离线生成待召回商品的语义向量集,由于使用了注意力机制,还需要query参与商品语义向量的生成。召回集是接近百万级的规模,因此可以方便的复用训练模型,一次生成batch_size个语义向量,并且全部Norm化成平方和为1的向量,保存在内存里,当下一个batch_size生成完毕,直接拼接在一起。在内存里存储完毕所有商品的语义向量,形式为numpy向量,最终存储到硬盘里的是npy文件,大小为500M左右,空间费用可以接受。
3、语义召回系统介绍
3.1 数据准备
利用苏宁完善的数据仓库环境,在每日的固定时间执行HIVE脚本,获取用户搜索词、对应的商品Title、编码、品牌品类,质量分等字段的信息。语料按搜索词搜索次数,商品质量排序,选取质量高的作为语料,并且从友商平台上抓取商品信息作为补充。同时,在spark平台上进行初始语料的处理,包括分词、去除无意义词、中英文分开处理等预处理步骤,最后要将处理完毕的语料转化成一个正DOC,四个负DOC, 即可以直接应用于模型训练的形式。另外还需要针对召回,对语料进行去重处理,避免召回同一件商品的情况出现。最后,给召回系统提供待召回的商品title集以及准确对应的商品ID和商品质量分集。
3.2 在线匹配
从上文可以看出,模型将准备好的待召回商品title集处理为npy文件,存在磁盘之中。另外输出了tf-serving服务框架所需要的pb格式模型,可以将用户搜索词实时转化为语义向量。接下来要做的事情就是计算query向量与所有商品语义向量之间的两两余弦距离,返回TopN, 找到对应的商品ID,提供给前台展示。
需要注意的是,这里找TopN的过程需要‘快准狠’,我们使用的Facebook开源的Faiss框架,为了保证准确度,没有使用任何自带的高级索引功能,只使用最简单的暴力计算两两之间的距离,这样肯定能找到正确结果。通过测试,在百万级数据的规模,维度为256,使用暴力检索,耗时也不到1ms,完全可以接受。另外出于业务目标考虑,提高高质量分物品的权重,这简单通过余弦距离乘以质量分来实现,人为提高高质量分物品与搜索词的余弦距离。
3.3 系统环境
整个语义召回系统的系统环境组成较为清晰,包括在Spark平台上的大规模数据处理,jupyter深度学习平台上的模型训练和语义向量生成,Linux主机上的Faiss匹配找出TopN的过程,tf-serving线上服务器的布置,以及方便结果调试的前端匹配结果展示,如下图所示:
图五: 召回系统前端展示
可以方便的传入各类参数,比如返回商品的个数,使用模型的版本,使用索引的种类等等,调试起来非常方便。
4、总结
本文介绍了DSSM文本匹配模型在苏宁商品语义召回上的应用,主要包含算法原理和工程实践两个方面。苏宁搜索团队在搜索匹配、个性化推荐、知识图谱、智能对话等自然语言处理领域有很多的尝试实践,限于篇幅本文不做介绍,欢迎读者关注后续的最新文章分享。
参考文献
- Huang P S, He X, Gao J, et al. Learning deep structured semantic models for web search using clickthrough data[C]// ACM International Conference on Conference on Information & Knowledge Management. ACM, 2013:2333-2338.
- Shen, Yelong, et al. “A latent semantic model with convolutional-pooling structure for information retrieval.” Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management. ACM, 2014.
- Palangi, Hamid, et al. “Semantic modelling with long-short-term memory for information retrieval.” arXiv preprint arXiv:1412.6629 (2014).
- http://ju.outofmemory.cn/entry/316660
- http://blog.csdn.net/u013074302/article/details/76422551
- 博客园 DSSM算法-计算文本相似度
- Gers, Felix A., Schmidhuber, Jrgen, and Cummins, Fred. Learning to forget: Continual prediction with lstm. Neural Computation, 12:2451–2471, 1999.
- Gers, Felix A., Schraudolph, Nicol N., and Schmidhuber, J¨urgen. Learning precise timing with lstm recurrent networks. J. Mach. Learn. Res., 3:115–143, March 2003.
作者简介
周杰,苏宁科技集团消费者平台研发中心算法专家,主要从事自然语言处理、个性化推荐、搜索匹配等领域的研发工作,在传统机器学习、深度学习方面有丰富实战经验。
李春生,苏宁科技集团消费者平台研发中心技术总监,负责商品、情报与搜索技术线架构设计与核心技术规划等方面的工作,在搜索领域有多年的实战经验,从0到1构建苏宁易购搜索平台,在搜索领域上耕耘7年有余,精通搜索架构设计与性能优化,同时在机器学习、大数据等领域对搜索的场景化应用有丰富的经验。
孙鹏飞,苏宁科技集团消费者平台研发中心搜索算法团队负责人,专注于nlp,搜索排序,智能问答方向的研究。带领团队从无到有搭建了搜索排序系统、个性化系统、智能搜索系统、反作弊系统等。对算法在产品中的调优及工程应用实践上有着丰富的经验。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】