用于「欺骗」神经网络的对抗样本(adversarial example)是近期计算机视觉,以及机器学习领域的热门研究方向。只有了解对抗样本,我们才能找到构建稳固机器学习算法的思路。本文中,UC Berkeley 的研究者们展示了两种对抗样本的制作方法,并对其背后的原理进行了解读。
通过神经网络进行暗杀——听起来很疯狂吧?也许有一天,这真的可能上演,不过方式可能与你想象中不同。显然,加以训练的神经网络能够驾驶无人机或操作其他大规模杀伤性武器。但是,即便是无害的(现在可用的)网络——例如,用于驾驶汽车的网络——也可能变成车主的敌人。这是因为,神经网络非常容易被「对抗样本(adversarial example)」攻击。
在神经网络中,导致网络输出不正确的输入被称为对抗样本。我们最好通过一个例子来说明。让我们从左边这张图开始。在某些神经网络中,这张图像被认为是熊猫的置信度是 57.7%,且其被分类为熊猫类别的置信度是所有类别中最高的,因此网络得出一个结论:图像中有一只熊猫。但是,通过添加非常少量的精心构造的噪声,可以得到一个这样的图像(右图):对于人类而言,它和左图几乎一模一样,但是网络却认为,其被分类为「长臂猿」的置信度高达 99.3%。这实在太疯狂了!
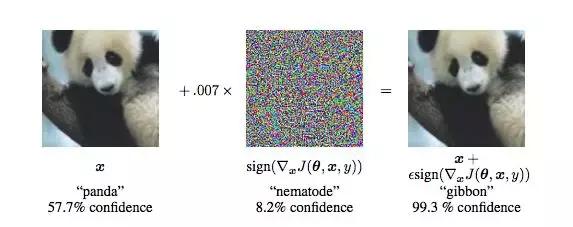
上图源自: Explaining and Harnessing Adversarial Examples,Goodfellow et al
那么,对抗样本如何进行暗杀呢?想象一下,如果用一个对抗样本替换一个停车标志——也就是说,人类可以立即识别这是停车标志,但神经网络不能。现在,如果把这个标志放在一个繁忙的交叉路口。当自动驾驶汽车接近交叉路口时,车载神经网络将无法识别停车标志,直接继续行驶,从而可能导致乘客死亡(理论上)。
以上只是那些复杂、稍显耸人听闻的例子之一,其实还会有更多利用对抗样本造成伤害的例子。例如,iPhone X 的「Face ID」解锁功能依赖神经网络识别人脸,因此容易受到对抗性攻击。人们可以通过构建对抗图像,避开 Face ID 安全功能。其他生物识别安全系统也将面临风险:通过使用对抗样本,非法或不合宜的内容可能会绕开基于神经网络的内容过滤器。这些对抗样本的存在意味着,含有深度学习模型的系统实际上有极高的安全风险。

为了理解对抗样本,你可以把它们想象成神经网络的「幻觉」。既然幻觉可以骗过人的大脑,同样地,对抗样本也能骗过神经网络。
上面这个熊猫对抗样本是一个有针对性的 (targeted) 例子。少量精心构造的噪声被添加图像中,从而导致神经网络对图像进行了错误的分类。然而,这个图像在人类看来和之前一样。还有一些无针对性 (non-targeted) 的例子,它们只是简单尝试找到某个能蒙骗神经网络的输入。对于人类来说,这种输入看起来可能像是白噪声。但是,因为我们没有被限制为寻找对人而言类似某物的输入,所以这个问题要容易得多。
我们可以找到将近所有神经网络的对抗样本。即使是那些最先进的模型,有所谓「超人类」的能力,也轻微地受此问题困扰。事实上,创建对抗样本非常简单。在本文中,我们将告诉你如何做到。用于开始生成你自己的对抗样本的所有所需代码等资料都可以在这个 github 中找到:https://github.com/dangeng/Simple_Adversarial_Examples

上图展示了对抗样本的效果
MNIST 中的对抗样本
这一部分的代码可以在下面的链接中找到(不过阅读本文并不需要下载代码):https://github.com/dangeng/Simple_Adversarial_Examples
我们将试着欺骗一个普通的前馈神经网络,它已经在 MNIST 数据集上经过训练。MNIST 是 28×28 像素手写数字图像的数据集,就像下面这样:
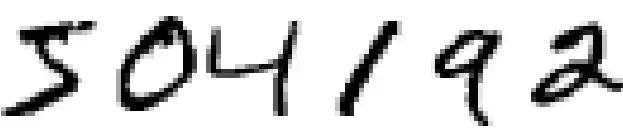
6 张 MNIST 图像并排摆放