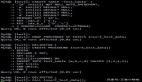
EXPLAIN:查看SQL语句的执行计划
EXPLAIN命令可以帮助我们深入了解MySQL基于开销的优化器,还可以获得很多可能被优化器考虑到的访问策略的细节,以及当运行SQL语句时哪种策略预计会被优化器采用,在优化慢查询时非常有用。
执行explain之后结果集包含如下信息
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------+
- 1.
- 2.
- 3.
下面将对每一个值进行解释
1、id
id用来标识整个查询中SELELCT语句的顺序,在嵌套查询中id越大的语句越先执行,该值可能为NULL
id如果相同,从上往下依次执行。id不同,id值越大,执行优先级越高,如果行引用其他行的并集结果,则该值可以为NULL
2、select_type
select_type表示查询使用的类型,有下面几种:
simple: 简单的select查询,没有union或者子查询
mysql> explain select * from test where id = 1000;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | test | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
primary: 最外层的select查询
mysql> explain select * from (select * from test where id = 1000) a;
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | NULL |
| 2 | DERIVED | test | const | PRIMARY | PRIMARY | 8 | const | 1 | NULL |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
union: union中的第二个或随后的select查询,不依赖于外部查询的结果集
mysql> explain select * from test where id = 1000 union all select * from test2 ;
+----+--------------+------------+-------+---------------+---------+---------+-------+-------+-----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------+------------+-------+---------------+---------+---------+-------+-------+-----------------+
| 1 | PRIMARY | test | const | PRIMARY | PRIMARY | 8 | const | 1 | NULL |
| 2 | UNION | test2 | ALL | NULL | NULL | NULL | NULL | 67993 | NULL |
| NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------+------------+-------+---------------+---------+---------+-------+-------+-----------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
dependent union: union中的第二个或随后的select查询,依赖于外部查询的结果集
mysql> explain select * from test where id in (select id from test where id = 1000 union all select id from test2) ;
+----+--------------------+------------+--------+---------------+---------+---------+-------+-------+-----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------------+------------+--------+---------------+---------+---------+-------+-------+-----------------+
| 1 | PRIMARY | test | ALL | NULL | NULL | NULL | NULL | 68505 | Using where |
| 2 | DEPENDENT SUBQUERY | test | const | PRIMARY | PRIMARY | 8 | const | 1 | Using index |
| 3 | DEPENDENT UNION | test2 | eq_ref | PRIMARY | PRIMARY | 8 | func | 1 | Using index |
| NULL | UNION RESULT | <union2,3> | ALL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------------+------------+--------+---------------+---------+---------+-------+-------+-----------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
subquery: 子查询中的第一个select查询,不依赖与外部查询的结果集
mysql> explain select * from test where id = (select id from test where id = 1000);
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------------+
| 1 | PRIMARY | test | const | PRIMARY | PRIMARY | 8 | const | 1 | NULL |
| 2 | SUBQUERY | test | const | PRIMARY | PRIMARY | 8 | const | 1 | Using index |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
dependent subquery: 子查询中的第一个select查询,依赖于外部查询的结果集
mysql> explain select * from test where id in (select id from test where id = 1000 union all select id from test2) ;
+----+--------------------+------------+--------+---------------+---------+---------+-------+-------+-----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------------+------------+--------+---------------+---------+---------+-------+-------+-----------------+
| 1 | PRIMARY | test | ALL | NULL | NULL | NULL | NULL | 68505 | Using where |
| 2 | DEPENDENT SUBQUERY | test | const | PRIMARY | PRIMARY | 8 | const | 1 | Using index |
| 3 | DEPENDENT UNION | test2 | eq_ref | PRIMARY | PRIMARY | 8 | func | 1 | Using index |
| NULL | UNION RESULT | <union2,3> | ALL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------------+------------+--------+---------------+---------+---------+-------+-------+-----------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
derived: 用于from子句中有子查询的情况,mysql会递归执行这些子查询,此结果集放在临时表中
mysql> explain select * from (select * from test2 where id = 1000)a;
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | NULL |
| 2 | DERIVED | test2 | const | PRIMARY | PRIMARY | 8 | const | 1 | NULL |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
3、table
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
3、table
table用来表示输出行所引用的表名
4、type(重要)
type表示访问类型,下面依次解释各种类型,类型顺序从最好到最差排列
system: 表仅有一行,是const类型的一个特例
mysql> explain select * from (select * from test2 where id = 1000)a;
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | NULL |
| 2 | DERIVED | test2 | const | PRIMARY | PRIMARY | 8 | const | 1 | NULL |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
因为子查询只有一行数据,模拟了单表只有一行数据,此时type为system
const: 确定只有一行匹配的时候,mysql优化器会在查询前读取它并且只读取一次,速度非常快
mysql> explain select * from test where id =1 ;
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | test | const | PRIMARY | PRIMARY | 8 | const | 1 | NULL |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
1 row in set (0.00 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
eq_ref: 对于每个来自于前面的表的行组合,从该表中读取一行,常用在一个索引是unique key或者primary key
mysql> explain select * from test,test2 where test.com_key=test2.com_key;
+----+-------------+-------+--------+---------------+--------------+---------+--------------------+-------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+--------------+---------+--------------------+-------+-------+
| 1 | SIMPLE | test2 | ALL | IDX(com_key) | NULL | NULL | NULL | 67993 | NULL |
| 1 | SIMPLE | test | eq_ref | IDX(com_key) | IDX(com_key) | 194 | test.test2.com_key | 1 | NULL |
+----+-------------+-------+--------+---------------+--------------+---------+--------------------+-------+-------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
ref: 对于来自前面的表的行组合,所有有匹配索引值的行都从这张表中读取,如果联接只使用键的最左边的前缀,或如果键不是UNIQUE或PRIMARY KEY(换句话说,如果联接不能基于关键字选择单个行的话),则使用ref
ref可以用于使用=或<=>操作符的带索引的列
mysql> explain select * from test ,test2 where test.bnet_id=test2.aid;
+----+-------------+-------+------+---------------+---------+---------+-------------------+-------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+---------+---------+-------------------+-------+-----------------------+
| 1 | SIMPLE | test | ALL | NULL | NULL | NULL | NULL | 68505 | Using where |
| 1 | SIMPLE | test2 | ref | idx_aid | idx_aid | 5 | test.test.bnet_id | 34266 | Using index condition |
+----+-------------+-------+------+---------------+---------+---------+-------------------+-------+-----------------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
test表bnet_id不是索引,test2表aid为索引列
ref_or_null: 类似ref,但是添加了可以专门搜索null值的行
mysql> explain select * from test where bnet_id=1 or bnet_id is null;
+----+-------------+-------+-------------+---------------+----------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------------+---------------+----------+---------+-------+------+-----------------------+
| 1 | SIMPLE | test | ref_or_null | idx_bnet | idx_bnet | 9 | const | 2 | Using index condition |
+----+-------------+-------+-------------+---------------+----------+---------+-------+------+-----------------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
前提为bnet_id列为索引,且bnet_id列有null值
index_merge: 该访问类型使用了索引合并优化方法,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素
mysql> explain select * from test where id = 1 or bnet_id = 1;
+----+-------------+-------+-------------+------------------+------------------+---------+------+------+--------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------------+------------------+------------------+---------+------+------+--------------------------------------------+
| 1 | SIMPLE | test | index_merge | PRIMARY,idx_bnet | PRIMARY,idx_bnet | 8,9 | NULL | 2 | Using union(PRIMARY,idx_bnet); Using where |
+----+-------------+-------+-------------+------------------+------------------+---------+------+------+--------------------------------------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
前提条件为id列和bnet_id列都有单列索引。如果出现index_merge,并且这类SQL后期使用较频繁,可以考虑把单列索引换为组合索引,这样效率更高
range: 只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。在该类型中ref列为NULL
当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range
mysql> explain select * from test where bnet_id > 1000 and bnet_id < 10000;
+----+-------------+-------+-------+---------------+----------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-----------------------+
| 1 | SIMPLE | test | range | idx_bnet | idx_bnet | 9 | NULL | 1 | Using index condition |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-----------------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
前提条件为bnet_id列有索引
index: 在进行统计时非常常见,此联接类型实际上会扫描索引树
mysql> explain select count(*) from test;
+----+-------------+-------+-------+---------------+----------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+-------+-------------+
| 1 | SIMPLE | test | index | NULL | idx_bnet | 9 | NULL | 68505 | Using index |
+----+-------------+-------+-------+---------------+----------+---------+------+-------+-------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
all: 对于每个来自于先前的表的行组合,进行完整的表扫描,通常可以增加更多的索引而不要使用ALL,使得行能基于前面的表中的常数值或列值被检索出
mysql> explain select * from test where create_time = '0000-00-00 00:00:00';
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | test | ALL | NULL | NULL | NULL | NULL | 68505 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+-------+-------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
5、possible_keys
possible_keys是指在这个SQL中,mysql可以使用这个索引去辅助查找记录,当查询涉及到的字段,都会被列出,但不一定被查询使用.若为空则表示没有可以使用的索引,此时可以通过检查where语句看是否可以引用某些列或者新建索引来提高性能。
6、key(重要)
key列显示的是当前表实际使用的索引,如果没有选择索引,则此列为null,要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX
7、key_len
key_len列显示MySQL决定使用的键长度。如果KEY键是NULL,则长度为NULL。在不损失精确性的情况下,长度越短越好
key len的长度还和字符集有关,latin1一个字符占用1个字节,gbk一个字符占用2个字节,utf8一个字符占用3个字节。key_len的计算法方法:
| 列类型 | 长度 | 备注 |
|---|---|---|
| id int | 4+1 | int为4bytes,允许为NULL,加1byte |
| id bigint not null | 8 | bigint为8bytes |
| user char(30) utf8 | 30*3+1 | utf8每个字符为3bytes,允许为NULL,加1byte |
| user varchar(30) not null utf8 | 30*3+2 | utf8每个字符为3bytes,变长数据类型,加2bytes |
| user varchar(30) utf8 | 30*3+2+1 | utf8每个字符为3bytes,允许为NULL,加1byte,变长数据类型,加2bytes |
| detail text(10) utf8 | 30*3+2+1 | TEXT截取部分,被视为动态列类型。 |
key_len只指示了where中用于条件过滤时被选中的索引列,是不包含order by或group by这一部分被选中的索引列
8、ref
ref列用来显示使用哪个列或常数与key一起从表中选择相应的行。它显示的列的名字(或const),此列多数时候为null
9、rows
rows列显示的是mysql解析器认为执行此SQL时必须扫描的行数。此数值为一个预估值,不是具体值,通常比实际值小
10、filtered
此参数为mysql 5.7 新加参数,指的是返回结果的行数所占需要读到的行(rows的值)的比例
对于使用join时,前一个表的结果集大小直接影响了循环的行数
11、extra(重要)
extra表示不在其他列并且也很重要的额外信息
using index: 该值表示这个SQL语句使用了覆盖索引(覆盖索引是指可以直接在索引列中得到想要的结果,而不用去回表),此时效率最高
mysql> explain select id from test;
+----+-------------+-------+-------+---------------+----------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+-------+-------------+
| 1 | SIMPLE | test | index | NULL | idx_bnet | 9 | NULL | 68505 | Using index |
+----+-------------+-------+-------+---------------+----------+---------+------+-------+-------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
这个例子中id字段为主键,但是key那里显示走的并不是主键索引,这个是因为mysql的所有二级索引中都会包含所有的主键信息,而mysql没有单独的存储主键索引,所以扫描二级索引的开销比全表扫描更快
using where: 表示存储引擎搜到记录后进行了后过滤(POST-FILTER),如果查询未能使用索引,using where的作用只是提醒我们mysql要用where条件过滤结果集
mysql> explain select * from test where id > 1;
+----+-------------+-------+-------+---------------+---------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+------+-------+-------------+
| 1 | SIMPLE | test | range | PRIMARY | PRIMARY | 8 | NULL | 34252 | Using where |
+----+-------------+-------+-------+---------------+---------+---------+------+-------+-------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
using temporary 表示mysql需要使用临时表来存储结果集,常见于排序和分组查询
mysql> explain select * from test where id in (1,2) group by bnet_id;
+----+-------------+-------+-------+-----------------------------------------+---------+---------+------+------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+-----------------------------------------+---------+---------+------+------+----------------------------------------------+
| 1 | SIMPLE | test | range | PRIMARY,IDX(event_key-bnet_Id),idx_bnet | PRIMARY | 8 | NULL | 2 | Using where; Using temporary; Using filesort |
+----+-------------+-------+-------+-----------------------------------------+---------+---------+------+------+----------------------------------------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
using filesort: 是指mysql无法利用索引直接完成排序(排序的字段不是索引字段),此时会用到缓冲空间来进行排序
mysql> explain select * from test order by bnet_id;
+----+-------------+-------+------+---------------+------+---------+------+-------+----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+-------+----------------+
| 1 | SIMPLE | test | ALL | NULL | NULL | NULL | NULL | 68505 | Using filesort |
+----+-------------+-------+------+---------------+------+---------+------+-------+----------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
using join buffer: 强调在获取连接条件时没有用到索引,并且需要连接缓冲区来存储中间结果。(性能可以通过添加索引或者修改连接字段改进)
mysql> explain select * from test left join test2 on test.create_time = test2.create_time;
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------------------------------------------+
| 1 | SIMPLE | test | NULL | ALL | NULL | NULL | NULL | NULL | 959692 | 100.00 | NULL |
| 1 | SIMPLE | test2 | NULL | ALL | NULL | NULL | NULL | NULL | 958353 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
Block Nested Loop是指Block Nested-Loop Join算法:将外层循环的行/结果集存入join buffer, 内层循环的每一行与整个buffer中的记录做比较,从而减少内层循环的次数.
impossible where: 表示where条件导致没有返回的行
mysql> explain select * from test where id is null;
+----+-------------+-------+------+---------------+------+---------+------+------+------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Impossible WHERE |
+----+-------------+-------+------+---------------+------+---------+------+------+------------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
using index condition: 是mysql 5.6 之后新加的特性,结合mysql的ICP(Index Condition Pushdown)特性使用。主要是优化了可以在索引(仅限二级索引)上进行 like 查找
如果extra中出现多个上面结果,则表示顺序使用上面的方法进行解析查询