前言
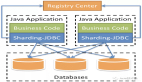
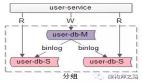
当Mysql数据库数据达到一定量后,查询SQL执行会变慢起来,除了建索引、优化程序代码以及SQL语句等常规手段外,利用经典MHA数据库中间件做数据库读写分离是一个不错的选择。但是在读写分离架构中会出现一个共性问题:SQL读取延迟。
读写实时场景
比如在微服务应用端新增一条业务数据,然后立即读取,这个时候会遇到读取不到情况!
为什么呢?
来源网络
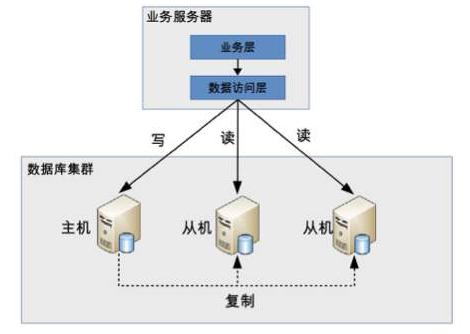
因为在读写分离架构中,主节点负责写入数据,同时mysql利用多线程技术把数据同步到从节点,从节点负责应用端读取请求。
而Mysql主从数据同步数据存在同步时间差,带来的问题是从节点同步不到主节点(Master)数据,应用端从从节点(Slave)读取不到新增的数据情况。
解决方案
利用官方HintManager 分片键值管理器, 强制路由到主库查询
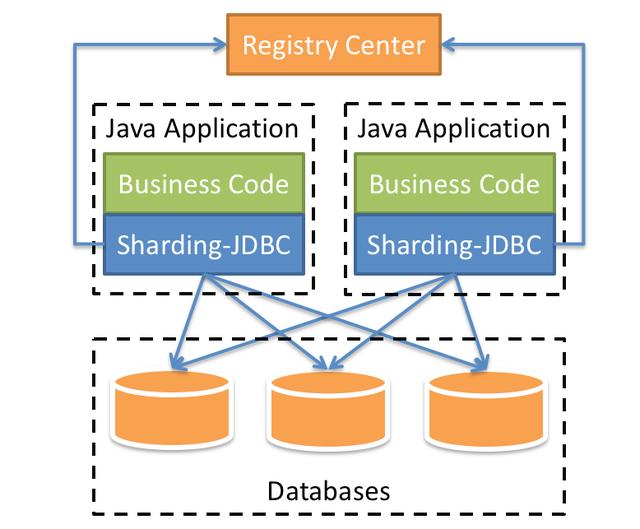
通过调用hintManager.setMasterRouteOnly() 强制路由到主库查询,伪代码如下:
- public ArticleEntity getWithMasterDB(Long id, String wid) {
- HintManager hintManager = HintManager.getInstance() ;
- hintManager.setMasterRouteOnly();
- ArticleEntity article = baseMapper.queryObject(id, wid);
- }
通过强制路由到主库查询有个风险,对于更新并实时查询业务场景比较多,如果都切到主库查询,势必会对主库服务器性能造成影响,可能还影响主从数据同步,所以要根据实际业务场景评估采用这种方式带来的服务器性能问题。
另外,如果业务层面可以做妥协的话,尽量减少这种更新并实时查询方式,一种思路是实时更新库,利用线程异步查询(例如更新后,睡眠1-2秒再查询),伪代码如下:
- public class ArticleCacheTask implements Runnable {
- @Override
- public void run() {
- try {
- // 控制读写分离不同步设置
- Thread.sleep(2000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- ArticleEntity articleEntity = articleService.getWithMasterDB(Long.valueOf(id), wid);
- }
- }