












2017 年,英伟达发布了深度学习加速器 NVDLA,全称 NVIDIA DeepLearning Accelerator,以推动在定制硬件设计中采用高效的 AI 推理。
在英伟达的开发套件 Jetson AGX Xavier 中,它能为 AI 模型提供 7.9 TOPS/W 的最佳峰值效率。
而最近,英伟达在 GitHub 上开源了 NVDLA 编译器的源代码,这是世界上首个软硬件推理平台的完整开源代码。系统架构师和软件开发者们,现在已可访问这个软硬件推理平台。

使用 NVDLA 进行物体检测
在本文中,将详细介绍网络图形编译器,是如何提升了专用硬件加速器的性能,并介绍在云端,如何构建和运行自定义 NVDLA 软硬件设计。
NVDLA 编译器的性能和效率
编译器是 NVDLA 软件栈的关键组件。它能生成优化的执行图,将预训练的神经网络模型层中定义的任务,映射到 NVDLA 中的各个执行单元。
一方面能最大限度地利用计算硬件,另一方面尽可能地减少数据移动。
NVDLA 核心硬件有六个专门的硬件单元,可以实现同时调度,或者在流水线配置中实现调度。
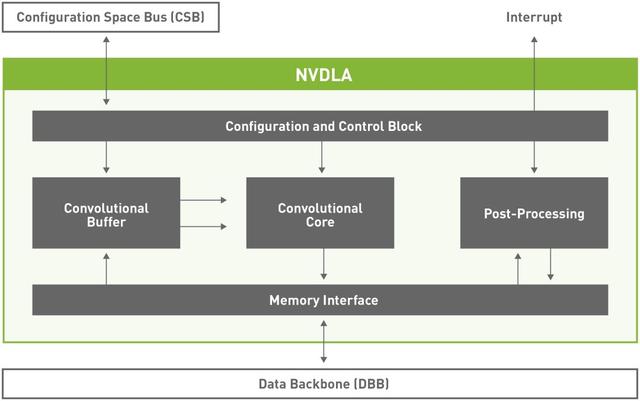
NVDLA 架构图
此外,它还具有小型和大型硬件配置文件。其中大型配置文件含有一些高级特性,如芯片上的 SRAM 接口、连接微控制器的能力。
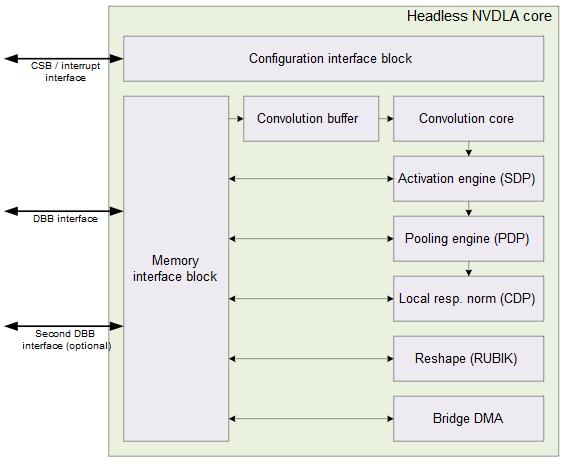
NVDLA 小型配置文件模型
硬件架构是模块化的,它被设计成可自由伸缩的形态,小到嵌入式物联网设计,大到使用NVDLA 单元阵列的大型数据中心,都能完美适用。
编译器可以根据多项因素进行调优:NVDLA 硬件配置、系统的 CPU 和内存控制配置,以及应用程序的自定义神经网络用例等等。
NVDLA 是如何提升性能的
在大型的 NVDLA 设计上,层融合和管道调度之类的编译器优化,表现性能良好,可广泛应用于多种神经网络架构,能提供高达 3 倍的性能效益。
这种优化后的灵活性,是实现跨大型网络模型(如ResNet-50)和小型网络模型(如 MobileNet)的性能优化的重要原因。
对于较小的 NVDLA 设计,编译器优化(如 Memory tiling )也是提高性能效率的关键。
Memory tiling 设计能在权重和激活数据之间,平衡芯片上缓冲区的使用,从而最小化芯片外存储的流量和能耗。
用户还可以自由地创建定制的图层,并根据自己的特殊用例进行调优,或者使用最新的算法进行实验。
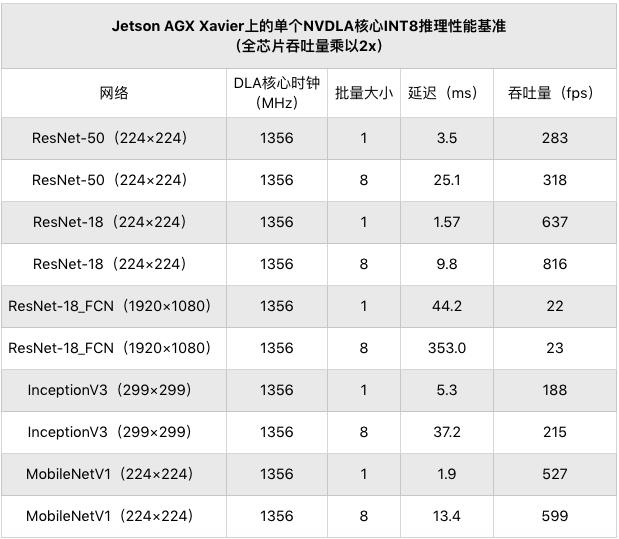
为了方便对比,可以根据下面的性能数字,评估 NVDLA 大型模型的预期性能。测量数据来自 Jetson AGX Xavier 开发工具上的一个 NVDLA 核心捕获。
使用 RISC-V 和 FireSim 在云端设计
通过这个编译器版本,NVDLA 用户可以访问集成、增添和探索 NVDLA 平台所需的软件和硬件源代码。
如果想要尝试入手,建议的方式是直接使用 NVDLA 上的 YOLOv3 ,以及云端的 RISC-V 和 FireSim 进行物体检测。
在使用 FireSim- NVADLA 时,可按照 FireSim 的说明操作,直到能够运行单节点模拟为止。
使用指南:http://docs.fires.im/en/1.5.0/index.html
按照教程中的步骤操作,在「设置FireSim Repo」一节中,验证是否正使用 FireSim -NVADLA 存储库,具体的操作代码如下:
- git clone https://github.com/CSL-KU/firesim-nvdla
- cd firesim-nvdla
- ./build-setup.sh fast
使用 NVDLA 运行单节点模拟之后,按照 NVDLA 教程中的步骤可以立即启动 YOLOv3。(地址:https://github.com/CSL-KU/firesim-nvdla#running-yolov3-on-nvdla)
这套编译器已经被 SiFive 这类初创公司所使用,并从中得到了受益。

SiFive 使用 NVDLA 进行深度学习推理
据悉,SiFive 在一年前首次在自己的平台上开始使用 NVDLA,而经过了性能优化的开源 NVDLA 编译器,能够创建特定领域的优化 SoC 设计,为 IoT Edge 中的 AI 现代计算需求做足准备。
项目开源地址:
https://github.com/nvdla/sw/releases/tag/v1.2.0-OC














