对数据进行分类整理是数据科学家和数据工程师的基础工作。Python会提供许多内置库,优化排序选项。有些库甚至可以同时在GPU上运行。令人惊奇的是,一些排序方法并没有使用之前所述的算法类型,其他方法的执行效果也不如预期。
选择使用哪种库和哪类排序算法着实难办,因为算法的执行变化很快。本文将具体展开讲解,提供一些帮助记忆算法的技巧,分享测速的结果。
分好类的茶
开始排序吧!
更新于2019年7月17日:速度测试结果现在包括PyTorch和TensorFlow的GPU执行。TensorFlow还包括tensorflow==2.0.0-beta1和tensorflow-gpu==2.0.0-beta1下的CPU结果。令人感到惊奇的发现是:PyTorch GPU变亮的速度更快,TensorFlow GPU比TensorFlow CPU速度更慢。
有许多不同的基本排序算法。有些比其他执行速度更快、占用内存更小。有些适合处理大数据,还有些可以更好地对特定序列数据进行排排序。可参见下表了解许多常用算法的时间和空间复杂性。
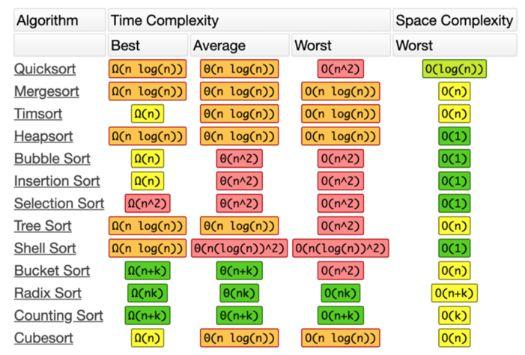
图片来自 http://bigocheatsheet.com/
了解基础的算法并不能解决大多数数据科学问题。事实上,过早的优化处理说不定什么时候就会被视为错误源泉。不过需要重复排序大量数据时,知道使用哪个库和哪些关键字参数会十分有用。以下是一个备忘表。

Google表格可在此处获取
多年来,许多库的排序算法都发生了变化。用于本文分析的软件版本如下。
- python 3.6.8
- numpy 1.16.4
- pandas 0.24.2
- tensorflow==2.0.0-beta1
- #tensorflow-gpu==2.0.0-beta1 slows sorting
- pytorch 1.1
让我们从基础开始吧!
Python (vanilla版)

Python包含两个内置排序法。
- my_list.sort()对原有列表进行排序。改变了列表。sort()返回None。
- sorted(my_list)生成任何可迭代的排序副本。sorted()返回已排序的迭代。sort()不会改变原始迭代。
sort()应该更快,因为已到位。神奇的是这不是下面测试中的发现。就地排序更危险,因为会改变原始数据。
香草味冰激凌
说到vanilla版Python,本文呈现的默认排序顺序都是升序—从小到大。大多数排序方法采用关键字参数,将顺序切换为降序。对大脑来说很不幸,因为每个库的参数名称都不同。
要将vanilla Python中排序方式更改为降序,通过reverse = True.
key可以作为关键字参数来传递,从而创建自己的排序标准。例如,sort(key = len)将按照每个列表项的长度排序。
Vanilla Python中唯一使用的排序算法是Timsort。Timsort会根据要排序的数据特征选择排序方法。举个例子,如果排短列表,就采用插入排序。
Timsort以及Vanilla Python的其他算法都很稳定。这意味着如果有多个相同值,这些数据在排序后仍维持原始顺序。
想要记住sort()与sorted()不同,就记着sorted比sort单词长,并且因复制需要排序时间会更长。虽然下面的结果与传统观念相悖,但助记符仍然起作用。
NumPy

Numpy是用于科学计算的Python基础库。与vanilla Python一样,有两种执行方式,一种是变异数组,另一种是数据的复制。
- my_array.sort()改变有序数组并返回已排序数组。
- np.sort(my_array)返回已排序数组的副本,因此原始数组不会改变。
以下是可选参数。
- axis:int,可选—要排序的轴。默认值为-1,表示沿最后一个轴排序。
- kind:{'quicksort','mergesort','heapsort','stable'},可选—排序算法。默认为'quicksort'。详细信息如下。
- order:str或str的列表,可选—当a是已定义字段的数组时,该参数会指定首先比较哪一字段,其次是哪个等等。可以指定单个字段为字符串,而且不是所有字段都需指定,不过仍需按照未指定字段在dtype中的顺序执行,打破联系。
现在,人们使用的排序算法与根据名字联想的略有不同。通过kind = quicksort意味着排序实际是从introsort算法开始的。
若[它]没有明显进展,则会切换成堆排序算法。执行该操作最坏的情况就是产生快速排序O(n * log(n))。Stable会自动为正在排序的数据类型选择最稳定的排序算法。目前依据数据类型,它与合并排序一起映射到tim排序或基数排序中。API前向兼容性目前抑制了选择执行的能力,并且是不同数据类型的硬连线。添加Timsort是为了更好地处理已完成或几乎排好序的数据。对于随机数据,timsort在处理方式上几乎与mergesort相同。现在timsort用于稳定排序,而在没有其他选择的情况下,quicksort仍为默认排序...'mergesort'和'stable'会映射到整数数据类型的基数排序。 来自Numpy文档 -(部分内容有改动)
其中一点是Numpy提供了比vanilla Python排序算法选项更大的控制范围。第二点是kind关键字值不一定与实际排序类型相对应。最后一点是mergesort和stable值是稳定的,但quicksort和heapsort不是。
Numpy排序是列表中唯一没有用关键字参数来反转排序顺序的操作。幸运的是,这个可快速反转数组顺序:my_arr [:: -1]。
Numpy算法选项在更受欢迎的Pandas中也适用—而且这些功能更容易保持稳定。
Pandas
通过df.sort_values(by = my_column)对Pandas DataFrame进行排序。有许多可用关键字参数。
- by:str或str of list,required—要排序的名称或名称列表。如果axis为0或index,那by可能会有索引级别和/或列标签。如果axis为1或columns,则by可能含级别和/或索引标签。
- axis:{0或index,1或columns},默认为0—排序轴。
- ascending:bool或bool列表,默认为True—按升序与降序排序。指定多个排序顺序的列表。如果是bool列表,就必须与by参数长度匹配。
- inplace:bool,默认为False—如果为True,则直接对其执行操作。
- kind:{quicksort,mergesort,heapsort或stable},默认快速排序—选择排序算法。可另参见ndarray.np.sort了解更多内容。对于DataFrames,此法仅应用于单列或单标签的排序。
- na_position:{‘first’,‘last’},默认‘last’ - 首先以NaNs作为开头,最后将NaNs作为结尾。
按照相同的句法对Pandas系列进行排序。用Series时,不需要输入by关键字,因为列不多。
Pandas用到了Numpy计算法,动动手指即可轻松获得同等优化的排序选项。但是,Pandas操作需要更多的时间。
按单列排序时的默认设置是Numpy的quicksort。如果排序进度很慢,那么实际为内省排序的quicksort会变为堆排序。Pandas确保多列排序使用Numpy的mergesort。Numpy中的mergesort实际用的是Timsort和Radix排序算法。这些排序算法都很稳定,而且多数列排序中稳定排序是很有必要的。
使用Pandas需记住的关键内容:
- 函数名称:sort_values()。
- by= column_name或列名列表。
- “ ascending”是逆转的关键字。
- 用mergesort进行稳定排序。
在进行探索性数据分析时,常发现自己是用Series.value_counts()在Pandas DataFrame中对值进行求和排序的。这是一个代码片段,用于每列常用值的求和和排序。
- for c in df.columns:
- print(f"---- {c} ---")
- print(df[c].value_counts().head())
Dask,实际上是用于大数据的Pandas,到2019年中期还没有实现并行排序,尽管大家一直在讨论这个。
对小数据集进行探索性数据分析,Pandas排序是个不错的选择。当数据很大,想要在GPU上并行搜索时,你也许会想到TensorFlow或PyTorch。
TensorFlow

TensorFlow是最受欢迎的深度学习框架。以下是TensorFlow 2.0的简介。
tf.sort(my_tensor)返回tensor排序副本。可选参数有:
- axis:{int,optional}待排序轴。默认值为-1,对最后一个轴进行排序。
- direction:{ascending or descending}—数值排序的方向。
- name:{str,optional}—操作的名称。
tf.sort在幕后使用top_k()方法。top_k使用CUB库的CUDA GPU促使并行性更容易实现。正如文档所述“CUB为CUDA编程模型的每一项程序都提供了最先进、可重复利用的软件组件。”TensorFlow通过CUB在GPU上使用基数排序。
为了使GPU能够满足TensorFlow 2.0,你需要!pip3 install tensorflow-gpu==2.0.0-beta1。我们会从下面的评论看到,如果你要进行排序,你可能想坚持tensorflow==2.0.0-beta1。
使用下面一小段代码来检查代码的每一行是否都能在CPU 或GPU中运行:
- tf.debugging.set_log_device_placement(True)
为了详述你想要使用GPU,使用下面代码:
- with tf.device('/GPU:0'):
- %time tf.sort(my_tf_tensor)
使用 with tf.device('/CPU:0'):为了使用CPU。
假如在TensorFlow中工作,tf.sort()是非常直观的记忆和使用方法。只需记住direction = descending可转换排序顺序。
PyTorch

torch.sort(my_tensor)返回tensor排序副本。可选参数有:
- dim:{int,optional} - 待排序维度
- descending:{bool,optional} - 控制排序顺序(升序或降序)。
- out:{tuple,optional} - (Tensor,LongTensor)的输出元组,可以作为输出缓冲区。
通过将.cuda()粘贴到张量的末尾来指定要使用GPU进行排序。
- gpu_tensor=my_pytorch_tensor.cuda()
- %time torch.sort(gpu_tensor)
一些分析表明,如果任何大于100万行乘以100,000列的数据集要排序,PyTorch将通过Thrust利用分段式并行排序。
不幸的是,当我们试图通过Google Colab中的Numpy创建1.1M x 100K随机数据点时,发现内存已不足。然后尝试了416 MB RAM的GCP,依旧没有内存。
分段排序和位置排序是mergesort的高性能体现,处理非均匀随机数据。分段排序使我们能够并行排序许多长度可变数组。 https://moderngpu.github.io/segsort.html
Thrust作为并行算法库,实现了GPU与多核CPU之间的联系。提供了排序原语,可自动选择最有效的执行方式。TensorFlow使用的CUB库会用来包装Thrust。PyTorch和TensorFlow在操作时GPU分类法相似 - 无论选择何种。
与TensorFlow一样,PyTorch的排序方法记起来相当容易:torch.sort()。唯一费脑子的是排序值的方向:TensorFlow使用direction,而PyTorch使用descending。
虽然用GPU进行排序对于非常大的数据集来说可能是一个很好的选择,但直接在SQL中对数据进行排序也是可以的。
SQL
SQL中的排序通常非常快,特别是在内存中执行时。
SQL很规范,但没有规定某操作必须使用哪种排序算法。Postgres使用磁盘合并排序,堆排序或快速排序,视情况而定。如果内存够,在内存中排序会更快。通过work_mem设置增加排序的可用内存。
其他SQL的执行使用不同排序算法。例如,根据Stack Overflow的回答,谷歌BigQuery的内省排序采取了一些措施。
SQL中的排序由ORDER BY命令执行。这种句法不同于所有使用单词sort的Python排序执行。其实更容易记住SQR语句与ODER BY,因为非常独特。
为使排序降序,请用关键字DESC。因此,按字母顺序从最后一个到第一个反馈给客户的查询如下所示:
- SELECT Names FROM Customers
- ORDER BY Names DESC;
比较
对于上面的每个Python库,我们对wall time进行了分析,以便在单列,单数组或单列表中对相同的1,000,000个数据点进行排序。同时使用了配有T4 GPU的Google Colab Jupyter笔记本。
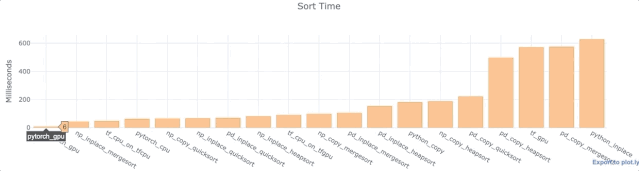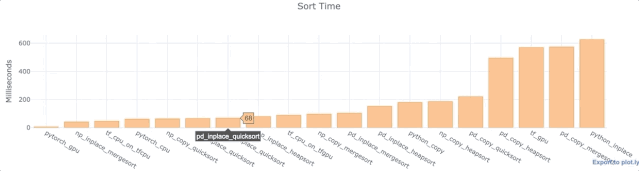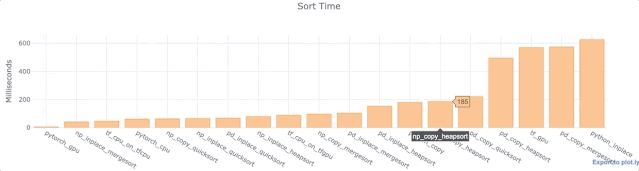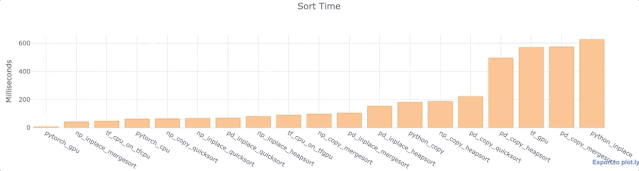
数据来源: https://colab.research.google.com/drive/1NNarscUZHUnQ5v-FjbfJmB5D3kyyq9Av
观察
- 对于Numpy和Pandas,inplace比复制数据更快。这并不奇怪。
- Pandas默认快速排序相当快。
- 大多数Pandas功能相对较慢。
- TensorFlow操作相当快。
- Python inplace排序慢得出奇。比Numpy inplace mergesort和TensorFlow慢了10倍。曾多次对其进行测试(使用不同的数据)来确认这不是一个异常现象。
重申,这只是一个小测试。绝对不是决定性的。
Wrap
通常不需要自定义排序。选择很多。一般不会采用单一的排序方法。相反,首先对数据进行评估,然后用效果更好的排序算法。如果排序进展不快,执行操作时也会自行改变算法。
在本文中,你已经了解了如何在Python数据科学堆和SQL中的每个板块里进行排序。
只需要记住选择哪个选项以及如何调用它们。可用上面的备忘表,节省时间。大致建议如下:
- 使用默认的Pandas sort_values()来探索相对较小的数据集。
- 数据集较大或运行速度较高时,尝试Numpy的就地合并,PyTorch或TensorFlow并行GPU方式或SQL。