又到了一年一度的教师节,每次教师节大家都会烦恼不知道送什么礼物?尤其是对于理工男来说,更是一个让人头大的问题。我今天就和大家分享一个用Python爬取淘宝商品信息的项目,希望可以给大家选礼物时提供一个参考。
1.爬取目标
本次项目利用selenium抓取淘宝商品信息,用selenium语法来获取商品信息、价格、购买人数、图片、以及店铺的名字,最后再把获取的信息储存在MongoDB中。
2.准备工作
在开始本次项目前,首先你要确保正确安装好Chome浏览器并配置好对应版本的ChromeDriver;另外,还需要正确安装Python的selenium库和pymongo库;最后还要在电脑上安装好MongoDB。
3.下面给出Windows下安装selenium、pymongo、MongoDB的方法
selenium:
- pip install selenium || pip3 install selenium
pymongo:
- pip install pymongo || pip3 install pymongo
MongoDB:
由于MongoDB现在版本比较多,3.0和4.0安装方法存在差异,我下载的是3.x版本的,安装和配置都比较简单,所以,我也建议大家安装和使用3.x版本的。
下载链接:
https://www.mongodb.com/download-center/community
ChromeDriver下载链接:
https://chromedriver.storage.googleapis.com/index.html
这里下载的ChromeDriver版本要和你下载的谷歌浏览器的版本相一致,否则程序运行会出现错误。下载完后将ChromeDriver.exe放到你Python安装路径下的Scripts中即可。
4.提取单页商品信息
获取各个元素用到的是selenium语法的
- find_element_by_xpath()
括号中需要填入各元素的Xpath路径。
- 获取商品信息

代码如下:
- 'info' : li.find_element_by_xpath('.//div[@class="row row-2 title"]').text
- 获取价格信息

代码如下:
- 'price' : li.find_element_by_xpath('.//a[@class="J_ClickStat"]').get_attribute('trace-price') + '元'
- 获取付款人数

代码如下:
- 'deal' : li.find_element_by_xpath('.//div[@class="deal-cnt"]').text
- 获取图片

代码如下:
- 'image' : li.find_element_by_xpath('.//div[@class="pic"]/a/img').get_attribute('src')
- 获取店铺名字

代码如下:
- 'name' : li.find_element_by_xpath('.//div[@class="shop"]/a/span[2]').text
5.提取多页商品信息
经过上面的分析,只能爬取一页的商品信息,我们想获取多页信息,就需要先定义一个函数,将总页数提取出来,代码如下
- #提取总页数
- def search():
- driver.find_element_by_id('q').send_keys('python')
- driver.find_element_by_class_name("tb-bg").click()
- time.sleep(10)
- token
- = driver.find_element_by_xpath(
- '//*[@id="mainsrp-pager"]/div/div/div/div[1]'
- ).text
- token = int(re.compile('\d+').search(token).group(0))
- return token
6.向下滑动页面
我们都知道selenium用来抓取动态渲染的页面非常有效,我们在抓取页面信息时,需要模拟人来操作下拉、翻页等操作。
对于下拉操作,有爬虫基础的可能会想到用selenium模拟的操作,但本次项目我们用js语法来模拟下拉,这样做的好处就是不容易被淘宝的反爬机制识别,代码如下
- def drop_down():
- for x in range(1,11,2):
- time.sleep(0.5)
- j = x/10 #滑动到的位置
- js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' %j
- driver.execute_script(js)
同理,我们也定义一个函数来模拟翻页,代码如下
- def next_page():
- token = search()
- num = 0
- while num != token - 1:
- driver.get('https://s.taobao.com/search?q={}&s={}'.format(keyword,44*num))
- driver.implicitly_wait(10) #隐式等待
- num += 1
- drop_down()
- get_product()
翻页编写时,需要注意,我在代码加入了keyword,意思就是可以根据你自己的需求,爬取不同种类的商品信息。
7.将数据保存至MongoDB
- def save_to_mongo(result):
- try:
- if db[MONGO_COLLECTION].insert(result):
- print('储存到MongoDB成功')
- except Exception:
- print('储存到MongoDB失败')
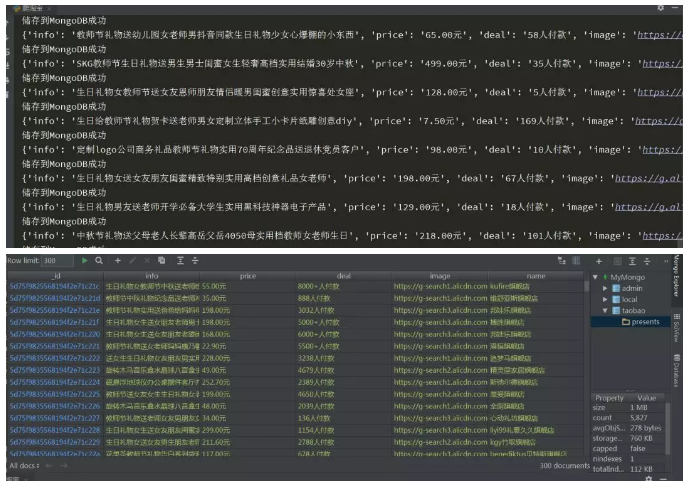
8.结果展示
总结
这次用selenium爬取淘宝商品信息,代码逻辑框架如下

由于我能力有限,暂时只能实现这么多功能,下一步准备对MongoDB储存的数据进行分析,这样就完成了从数据爬取——数据储存——数据分析一个完整的过程。
最后,祝所有的老师们:教师节快乐!