译者简介:北京第二外国语学院国际商务专业研一在读,目前在学习Python编程和量化投资相关知识。
作者:Real Python × DataCamp
干净整洁的数据是后续进行研究和分析的基础。数据科学家们会花费大量的时间来清理数据集,毫不夸张地说,数据清洗会占据他们80%的工作时间,而真正用来分析数据的时间只占到20%左右。
所以,数据清洗到底是在清洗些什么?
通常来说,你所获取到的原始数据不能直接用来分析,因为它们会有各种各样的问题,如包含无效信息, 列名不规范、格式不一致,存在重复值, 缺失值,异常值 等.....
本文会给大家介绍如何用Python中自带的 Pandas 和 NumPy 库进行数据清洗。在正式讲解之前,先简单介绍一下这两个非常好用的库。
Pandas的名称来自于 P anel data 和Python数据分析 data analysis ,是Python的一个数据分析包, 最初由AQR Capital Management于2008年4月开发, 被作为金融数据分析工具,为时间序列分析提供了很好的支持, 并于2009年底开源出来。
NumPy是 Numeric Python 的缩写,是Python的一种开源的数值计算扩展,可用来存储和处理大型矩阵 matrix ,比Python自身的嵌套列表结构要高效的多,提供了许多高级的数值编程工具,如:矩阵数据类型、矢量处理,以及精密的运算库,专为进行严格的数字处理而产生。
目录
一、了解数据
二、清洗数据
去除不需要的行、列
重新命名列
重新设置索引
用字符串操作规范列
用函数规范列
删除重复数据
填充缺失值
三、总结
【注】为了清晰直观地展示数据清洗操作,本文会用到几个不同的数据集,重点是方法的讲解。
【工具】Python 3
一、了解数据
拿到一个全新的数据集,应该从哪里入手?
没错,我们需要先了解数据,看看它长什么样子。这里用 tushare.pro 上面的日线行情数据进行展示,以浦发银行(600000.SH)为例。 常用的方法和属性如下:
.head()
.tail()
.shape
.columns
.info()
.describe()
.value_counts()
首先,获取数据:
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- import tushare as ts
- pd.set_option('display.max_columns', 100) # 设置显示数据的最大列数,防止出现省略号…,导致数据显示不全
- pd.set_option('expand_frame_repr', False) # 当列太多时不自动换行
- pro = ts.pro_api()
- df = pro.daily(ts_code='600000.SH', start_date='20190401', end_date='20190430')
.head() 查看前n行数据,默认值是5
- df.head()
- Out[1]:
- ts_code trade_date open high low close pre_close change pct_chg vol amount
- 0 600000.SH 20190430 11.70 12.09 11.70 11.97 11.48 0.49 4.2683 1234747.38 1466714.710
- 1 600000.SH 20190429 11.35 11.54 11.34 11.48 11.32 0.16 1.4134 385869.38 442046.727
- 2 600000.SH 20190426 11.43 11.56 11.28 11.32 11.54 -0.22 -1.9064 424695.81 485267.261
- 3 600000.SH 20190425 11.56 11.69 11.48 11.54 11.62 -0.08 -0.6885 408761.29 473973.527
- 4 600000.SH 20190424 11.76 11.77 11.51 11.62 11.70 -0.08 -0.6838 382011.08 444929.313
.tail() 查看后n行数据,默认值是5
- df.tail()
- Out[2]:
- ts_code trade_date open high low close pre_close change pct_chg vol amount
- 16 600000.SH 20190408 11.79 11.96 11.65 11.72 11.71 0.01 0.0854 778703.73 920513.531
- 17 600000.SH 20190404 11.55 11.71 11.54 11.71 11.50 0.21 1.8261 752325.27 876099.547
- 18 600000.SH 20190403 11.37 11.54 11.34 11.50 11.44 0.06 0.5245 502710.29 575799.446
- 19 600000.SH 20190402 11.50 11.52 11.41 11.44 11.44 0.00 0.0000 467147.10 534896.810
- 20 600000.SH 20190401 11.36 11.52 11.29 11.44 11.28 0.16 1.4184 706374.05 808657.530
.shape 查看数据维数
- df.shape
- Out[3]: (21, 11)
.columns 查看所有列名
- df.columns
- Out[4]:
- Index(['ts_code', 'trade_date', 'open', 'high', 'low', 'close', 'pre_close',
- 'change', 'pct_chg', 'vol', 'amount'],
- dtype='object')
.info() 查看索引、数据类型和内存信息
- df.info()
- <class 'pandas.core.frame.DataFrame'>
- RangeIndex: 21 entries, 0 to 20
- Data columns (total 11 columns):
- ts_code 21 non-null object
- trade_date 21 non-null object
- open 21 non-null float64
- high 21 non-null float64
- low 21 non-null float64
- close 21 non-null float64
- pre_close 21 non-null float64
- change 21 non-null float64
- pct_chg 21 non-null float64
- vol 21 non-null float64
- amount 21 non-null float64
- dtypes: float64(9), object(2)
- memory usage: 1.9+ KB
.describe() 查看每列数据的基本统计值,包括计数值、均值、标准差、最小最大值、1/4、1/2、3/4分位数。
- df.describe()
- Out[7]:
- open high low close pre_close change pct_chg vol amount
- count 21.000000 21.000000 21.000000 21.000000 21.000000 21.000000 21.000000 2.100000e+01 2.100000e+01
- mean 11.630476 11.777619 11.524286 11.637143 11.604286 0.032857 0.296252 5.734931e+05 6.704836e+05
- std 0.215348 0.228930 0.184840 0.207512 0.206799 0.193213 1.671099 2.333355e+05 2.792896e+05
- min 11.350000 11.520000 11.280000 11.320000 11.280000 -0.300000 -2.497900 2.627369e+05 3.017520e+05
- 25% 11.470000 11.560000 11.410000 11.480000 11.470000 -0.060000 -0.519900 4.102754e+05 4.739735e+05
- 50% 11.560000 11.750000 11.480000 11.540000 11.540000 0.000000 0.000000 5.027103e+05 5.757994e+05
- 75% 11.760000 11.990000 11.650000 11.720000 11.710000 0.100000 0.839600 7.050917e+05 8.161270e+05
- max 12.020000 12.200000 11.880000 12.010000 12.010000 0.490000 4.268300 1.234747e+06 1.466715e+06
.value_counts() 查看Series对象的唯一值和计数值
- df['close'].value_counts(dropna=False)
- Out[8]:
- 11.48 2
- 11.47 2
- 11.71 2
- 11.54 2
- 11.91 2
- 11.44 2
- 11.72 1
- 11.95 1
- 11.70 1
- 11.32 1
- 11.49 1
- 12.01 1
- 11.62 1
- 11.50 1
- 11.97 1
- Name: close, dtype: int64
如果上面这些操作还不够直观的话,就作图看看,需要先导入Python可视化库 matplotlib , 为了规范代码书写,统一写在了最前面。
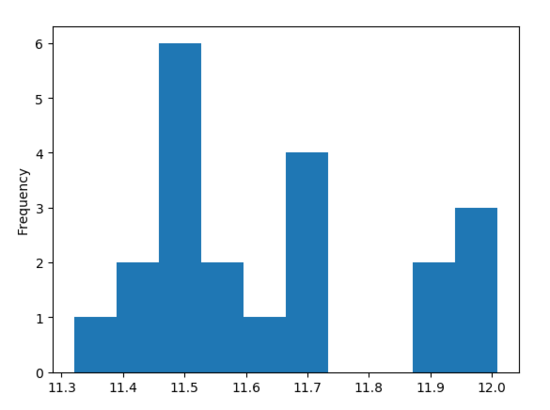
① 直方图
- df['close'].plot(kind='hist', rot=0)
- plt.show()
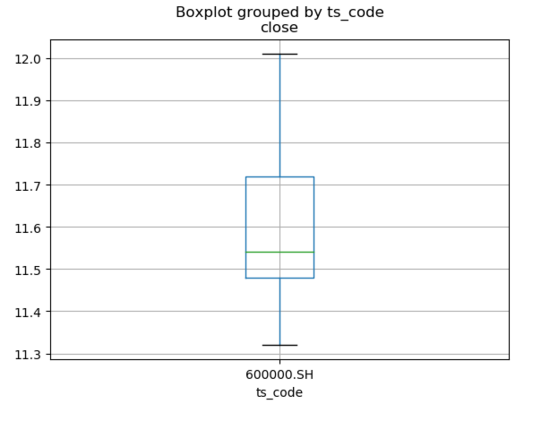
② 箱型图
- df.boxplot(column='close', by='ts_code', rot=0)
- plt.show()
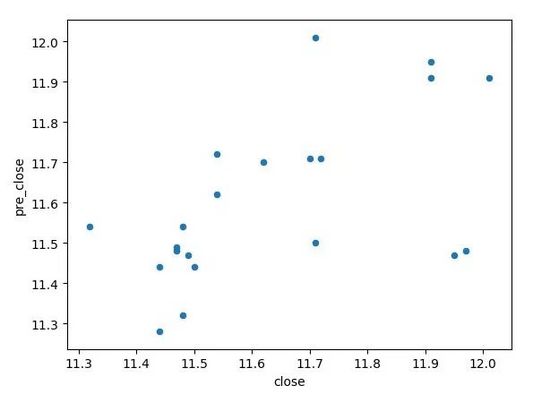
③ 散点图
- df.plot(kind='scatter', x='close', y='pre_close', rot=0)
- plt.show()
二、清洗数据
了解数据集之后,我们就可以开始对数据集进行清洗了,前面提到通常要处理的问题有 包含无效信息, 列名不规范、格式不一致,存在重复值,缺失值,异常值等,下面我们一个一个来看。
01
去除不需要的行、列
在分析一个数据集的时候,很多信息其实是用不到的,因此,需要去除不必要的行或列。这里以csv文件为例,在导入的时候就可以通过设置 pd.read_csv() 里面的参数来实现这个目的。
先来感受一下官方文档中给出的详细解释,里面的参数是相当的多,本文只介绍比较常用的几个,感兴趣的话,可以好好研究一下文档,这些参数还是非常好用的,能省去很多导入后整理的工作。

【 header 】默认header=0,即将文件中的0行作为列名和数据的开头,但有时候0行的数据是无关的,我们想跳过0行,让1行作为数据的开头,可以通过将header设置为1来实现。
【 usecols 】 根据列的位置或名字,如[0,1,2]或[‘a’, ‘b’, ‘c’],选出特定的列。
【 nrows 】 要导入的数据行数,在数据量很大、但只想导入其中一部分时使用。
获取数据:
从NYC OpenData网站下载csv格式原始数据
数据样本如下:
导入数据,只选取前100行和特定几列。
- subset_columns = ['Job #', 'Doc #', 'Borough', 'Initial Cost', 'Total Est. Fee']
- df = pd.read_csv('文件路径', nrows=100, usecols=subset_columns)
- df.head()
- Out[15]:
- Job # Doc # Borough Initial Cost Total Est. Fee
- 0 420291794 1 QUEENS $2000.00 $100.00
- 1 420291801 1 QUEENS $15000.00 $151.50
- 2 340644128 1 BROOKLYN $44726.00 $234.00
- 3 421685439 1 QUEENS $0.00 $243.00
- 4 421677974 2 QUEENS $105000.00 $1275.60
再看一下将header设置为1的效果,但这里其实不需要这么做,因为0行数据是有用的。
- df = pd.read_csv('文件路径', nrows=100, header=1)
- df.head()
- Out[15]:
- 0 420291794 1 QUEENS $2000.00 $100.00
- 1 420291801 1 QUEENS $15000.00 $151.50
- 2 340644128 1 BROOKLYN $44726.00 $234.00
- 3 421685439 1 QUEENS $0.00 $243.00
- 4 421677974 2 QUEENS $105000.00 $1275.60
如果在数据导入之后,还想删除某些行和列,可以用 .drop() 方法。
先创建一个列表list,把不需要的列名放进去,再调用 .drop() 方法,参数 axis 为 1 时代表列,为 0 时代表行,参数 inplace=True 表示不创建新的对象,直接对原始对象进行修改。这里我们删除前两列。
- to_drop = ['Job #', 'Doc #']
- df.drop(to_drop, axis=1, inplace=True)
- df.head()
- Out[22]:
- Borough Initial Cost Total Est. Fee
- 0 QUEENS $2000.00 $100.00
- 1 QUEENS $15000.00 $151.50
- 2 BROOKLYN $44726.00 $234.00
- 3 QUEENS $0.00 $243.00
- 4 QUEENS $105000.00 $1275.60
02
重新命名列
当原始数据的列名不好理解,或者不够简洁时,可以用 .rename() 方法进行修改。这里我们把英文的列名改成中文, 先创建一个字典,把要修改的列名定义好,然后调用 rename() 方法。
- new_names = {'Borough': '区', 'Initial Cost': '初始成本', 'Total Est. Fee': '总附加费用'}
- df.rename(columns=new_names, inplace=True)
- df.head()
- Out[23]:
- 区 初始成本 总附加费用
- 0 QUEENS $2000.00 $100.00
- 1 QUEENS $15000.00 $151.50
- 2 BROOKLYN $44726.00 $234.00
- 3 QUEENS $0.00 $243.00
- 4 QUEENS $105000.00 $1275.60
03
重新设置索引
数据默认的索引是从0开始的有序整数,但如果想把某一列设置为新的索引,可以用 .set_index() 方法实现,在示例中我们把"区"这列设置为新索引。
- df.set_index('区', inplace=True)
- df.head()
- Out[24]:
- 初始成本 总附加费用
- 区
- QUEENS $2000.00 $100.00
- QUEENS $15000.00 $151.50
- BROOKLYN $44726.00 $234.00
- QUEENS $0.00 $243.00
- QUEENS $105000.00 $1275.60
04
用字符串操作规范列
字符串 str 操作是非常实用的,因为列中总是会包含不必要的字符,常用的方法如下:
lower()
upper()
capitalize()
replace()
strip()
split()
get()
contains()
find()
str.lower() 是把大写转换成小写, 同理, str.upper() 是把小写转换成大写,将示例中用大写字母表示的索引转换成小写,效果如下:
- df.index = df.index.str.lower()
- df.head()
- Out[25]:
- 初始成本 总附加费用
- 区
- queens $2000.00 $100.00
- queens $15000.00 $151.50
- brooklyn $44726.00 $234.00
- queens $0.00 $243.00
- queens $105000.00 $1275.60
str.capitalize() 设置首字母大写
- df.index = df.index.str.capitalize()
- df.head()
- Out[26]:
- 初始成本 总附加费用
- 区
- Queens $2000.00 $100.00
- Queens $15000.00 $151.50
- Brooklyn $44726.00 $234.00
- Queens $0.00 $243.00
- Queens $105000.00 $1275.60
str.replace('$', '') 替换特定字符。这里把列中的美元符号$去掉,替换成空字符。
- df['初始成本'] = df['初始成本'].str.replace('$', '')
- df['总附加费用'] = df['总附加费用'].str.replace('$', '')
- df.head()
- Out[27]:
- 初始成本 总附加费用
- 区
- Queens 2000.00 100.00
- Queens 15000.00 151.50
- Brooklyn 44726.00 234.00
- Queens 0.00 243.00
- Queens 105000.00 1275.60
str.strip() 去除字符串中的头尾空格、以及\n \t
- df['初始成本'] = ' ' + df['初始成本']
- df['初始成本'][0]
- Out[28]: ' 2000.00'
- df['初始成本'] = df['初始成本'].str.strip()
- df['初始成本'][0]
- Out[29]: '2000.00'
str.split('x') 使用字符串中的 'x' 字符作为分隔符,将字符串分隔成列表。这里将列中的值以 '.' 进行分割,效果如下:
- df['总附加费用'] = df['总附加费用'].str.split('.')
- df.head()
- Out[30]:
- 初始成本 总附加费用
- 区
- Queens 2000.00 [100, 00]
- Queens 15000.00 [151, 50]
- Brooklyn 44726.00 [234, 00]
- Queens 0.00 [243, 00]
- Queens 105000.00 [1275, 60]
str.get() 选取列表中某个位置的值。接着上面分割后的结果,我们用 str.get(0) 取出列表中前一个位置的数值,生成新的一列“总附加费用_整数”,即取出金额中的整数部分。
- df['总附加费用_整数'] = df['总附加费用'].str.get(0)
- df.head()
- Out[31]:
- 初始成本 总附加费用 总附加费用_整数
- 区
- Queens 2000.00 [100, 00] 100
- Queens 15000.00 [151, 50] 151
- Brooklyn 44726.00 [234, 00] 234
- Queens 0.00 [243, 00] 243
- Queens 105000.00 [1275, 60] 1275
str.contains() 判断是否存在某个字符,返回的是布尔值。这里判断一下"总附加费用_整数"列中是否包含字符'0'。
- df['总附加费用_整数'].str.contains('0')
- Out[33]:
- 区
- Queens True
- Queens False
- Brooklyn False
- Queens False
- Queens False
str.find() 检测字符串中是否包含子字符串str,如果是,则返回该子字符串开始位置的索引值。示例中的'0'字符最开始出现的位置是1。
- df['总附加费用_整数'][0]
- Out[13]: '100'
- df['总附加费用_整数'][0].find('0')
- Out[14]: 1
学完基本的字符串操作方 法,我们来看一下如何结合 NumPy 来提高字符串操作的效率。
获取数据,这里我们用一个新的数据集,下载链接如下,里面包含两个csv文件和一个txt文件:
https://github.com/realpython/python-data-cleaning
① BL-Flickr-Images-Book.csv
② olympics.csv
③ university_towns.txt
导入csv文件①,先观察一下" Place of Publication"这一列。
- df = pd.read_csv('文件路径')
- df['Place of Publication'].head(10)
- Out[38]:
- 0 London
- 1 London; Virtue & Yorston
- 2 London
- 3 London
- 4 London
- 5 London
- 6 London
- 7 pp. 40. G. Bryan & Co: Oxford, 1898
- 8 London]
- 9 London
- Name: Place of Publication, dtype: object
我们发现,这一列中的格式并不统一,比如1行中的London; Virtue & Yorston,London后面的部分我们不需要,还有7行的pp. 40. G. Bryan & Co: Oxford, 1898,有效信息只是Oxford。
再用 .tail(10) 方法观察这一列的最后十行:
- df['Place of Publication'].tail(10)
- Out[39]:
- 8277 New York
- 8278 London
- 8279 New York
- 8280 London
- 8281 Newcastle-upon-Tyne
- 8282 London
- 8283 Derby
- 8284 London
- 8285 Newcastle upon Tyne
- 8286 London
- Name: Place of Publication, dtype: object
我们发现,8281行的Newcastle-upon-Tyne中间有连字符,但8285行却没有,这些都是要解决的格式不规范的问题。
为了清洗这一列,我们可以将Pandas中的 .str() 方法与NumPy的 np.where 函数相结合, np.where 函数是Excel的IF()宏的矢量化形式,它的语法如下:
- >>> np.where(condition, then, else)
如果 condition 条件为真,则执行 then ,否则执行 else 。这里的condition条件可以是一个类数组的对象,也可以是一个布尔表达式,我们也可以利用 np.where 函数嵌套多个条件进行矢量化计算和判断。
- >>> np.where(condition1, x1,
- np.where(condition2, x2,
- np.where(condition3, x3, ...)))
下面的这个实例,就是同时嵌套两个条件解决上面提到的那两个字符串问题。思路是,如果字符串里面包含'London',就用'London'代替,这样可以去除其他冗余信息,否则,如果字符串里面包含'Oxford',则用'Oxford'代替,同时如果字符串里面包含符号'-',则用空格代替。
- pub = df['Place of Publication']
- london = pub.str.contains('London')
- oxford = pub.str.contains('Oxford')
- df['Place of Publication'] = np.where(london, 'London',
- np.where(oxford, 'Oxford',
- pub.str.replace('-', ' ')))
打印出前十行和后十行,结果如下,可以和整理前的数据进行对比。
- df['Place of Publication'].head(10)
- Out[42]:
- 0 London
- 1 London
- 2 London
- 3 London
- 4 London
- 5 London
- 6 London
- 7 Oxford
- 8 London
- 9 London
- Name: Place of Publication, dtype: object
- df['Place of Publication'].tail(10)
- Out[43]:
- 8277 New York
- 8278 London
- 8279 New York
- 8280 London
- 8281 Newcastle upon Tyne
- 8282 London
- 8283 Derby
- 8284 London
- 8285 Newcastle upon Tyne
- 8286 London
- Name: Place of Publication, dtype: object
05
用函数规范列
在某些情况下,数据不规范的情况并不局限于某一列,而是更广泛地分布在整个表格中。因此,自定义函数并应用于整个表格中的每个元素会更加高效。用 applymap() 方法可以实现这个功能,它类似于内置的 map() 函数,只不过它是将函数应用于整个表格中的所有元素。
我们打开文件txt文件 ③ ,先观察一下数据:
- $ head Datasets/univerisity_towns.txt
- Alabama[edit]
- Auburn (Auburn University)[1]
- Florence (University of North Alabama)
- Jacksonville (Jacksonville State University)[2]
- Livingston (University of West Alabama)[2]
- Montevallo (University of Montevallo)[2]
- Troy (Troy University)[2]
- Tuscaloosa (University of Alabama, Stillman College, Shelton State)[3][4]
- Tuskegee (Tuskegee University)[5]
- Alaska[edit]
观察发现,数据格式有如下特点:
州A[edit]
城市A(大学)
城市B(大学)
州B[edit]
城市A(大学)
城市B(大学)
......
我们可以利用这一数据格式,创建一个(州、市)元组列表,并将该列表转化成一个DataFrame。先创建一个列表,列表中包含州和城市(大学)信息。
- university_towns = []
- with open('D:/code/tushare interpret and tech team/python-data-cleaning-master/Datasets/university_towns.txt') as file:
- for line in file:
- if '[edit]' in line: # 该行有[edit]
- state = line # 将改行信息赋值给“州”,记住这个“州”,直到找到下一个为止
- else:
- university_towns.append((state, line)) # 否则,改行为城市信息,并且它们都属于上面的“州”
- university_towns[:5]
- Out[44]:
- [('Alabama[edit]\n', 'Auburn (Auburn University)[1]\n'),
- ('Alabama[edit]\n', 'Florence (University of North Alabama)\n'),
- ('Alabama[edit]\n', 'Jacksonville (Jacksonville State University)[2]\n'),
- ('Alabama[edit]\n', 'Livingston (University of West Alabama)[2]\n'),
- ('Alabama[edit]\n', 'Montevallo (University of Montevallo)[2]\n')]
用 pd.DataFrame() 方法将这个列表转换成一个DataFrame,并将列设置为"State"和"RegionName"。Pandas 将接受列表中的每个元素,并将元组左边的值传入"State"列,右边的值传入"RegionName"列。
- towns_df = pd.DataFrame(university_towns, columns=['State', 'RegionName'])
- towns_df.head()
- Out[45]:
- State RegionName
- 0 Alabama[edit]\n Auburn (Auburn University)[1]\n
- 1 Alabama[edit]\n Florence (University of North Alabama)\n
- 2 Alabama[edit]\n Jacksonville (Jacksonville State University)[2]\n
- 3 Alabama[edit]\n Livingston (University of West Alabama)[2]\n
- 4 Alabama[edit]\n Montevallo (University of Montevallo)[2]\n
接下来就要对列中的字符串进行整理,"State"列中的有效信息是州名,"RegionName"列中的有效信息是城市名,其他的字符都可以删掉。当然,除了用之前提到的利用循环和 .str() 方法相结合的方式进行操作,我们还可以选择用 applymap() 方法,它会将传入的函数作用于整个DataFrame所有行列中的每个元素。
先定义函数 get_citystate(item) ,功能是只提取元素中的有效信息。
- def get_citystate(item):
- if ' (' in item:
- return item[:item.find(' (')]
- elif '[' in item:
- return item[:item.find('[')]
- else:
- return item
然后,我们将这个函数传入 applymap() ,并应用于towns_df,结果如下:
- towns_df = towns_df.applymap(get_citystate)
- towns_df.head()
- Out[48]:
- State RegionName
- 0 Alabama Auburn
- 1 Alabama Florence
- 2 Alabama Jacksonville
- 3 Alabama Livingston
- 4 Alabama Montevallo
现在towns_df表格看起来是不是干净多了!
06
删除重复数据
重复数据会消耗不必要的内存,在处理数据时执行不必要的计算,还会使分析结果出现偏差。因此,我们有必要学习如何删除重复数据。
先看一个来自DataCamp的数据集,调用info()方法打印出每列数据的具体信息和内存信息,共有24092行数据,内存占用量是 753.0+ KB。
- tracks = billboard[['year', 'artist', 'track', 'time']]
- print(tracks.info())
- <class 'pandas.core.frame.DataFrame'>
- RangeIndex: 24092 entries, 0 to 24091
- Data columns (total 4 columns):
- year 24092 non-null int64
- artist 24092 non-null object
- track 24092 non-null object
- time 24092 non-null object
- dtypes: int64(1), object(3)
- memory usage: 753.0+ KB
- None
下面调用 .drop_duplicates() 函数删除重复数据。
- In [11]: tracks_no_duplicates = tracks.drop_duplicates()
- ... print(tracks_no_duplicates.info())
- ...
- <class 'pandas.core.frame.DataFrame'>
- Int64Index: 317 entries, 0 to 316
- Data columns (total 4 columns):
- year 317 non-null int64
- artist 317 non-null object
- track 317 non-null object
- time 317 non-null object
- dtypes: int64(1), object(3)
- memory usage: 12.4+ KB
- None
删完之后我们发现,数据量减少到了317个,内存占用缩减至 12.4+ KB。
07
填充缺失值
数据集中经常会存在缺失值,学会正确处理它们很重要,因为在计算的时候,有些无法处理缺失值,有些则在默认情况下跳过缺失值。 而且,了解缺失的数据,并思考用什么值来填充它们,对做出无偏的数据分析至关重要。
同样是来自DataCamp的一个存在缺失值的数据集:
- In [3]: airquality.head(10)
- Out[3]:
- Ozone Solar.R Wind Temp Month Day
- 0 41.0 190.0 7.4 67 5 1
- 1 36.0 118.0 8.0 72 5 2
- 2 12.0 149.0 12.6 74 5 3
- 3 18.0 313.0 11.5 62 5 4
- 4 NaN NaN 14.3 56 5 5
- 5 28.0 NaN 14.9 66 5 6
- 6 23.0 299.0 8.6 65 5 7
- 7 19.0 99.0 13.8 59 5 8
- 8 8.0 19.0 20.1 61 5 9
- 9 NaN 194.0 8.6 69 5 10
以"Ozone"列为例,我们可以调用 fillna() 函数,用该列的均值 .mean() 填充NaN值。
- oz_mean = airquality.Ozone.mean()
- airquality['Ozone'] = airquality['Ozone'].fillna(oz_mean)
- print(airquality.head(10))
- Ozone Solar.R Wind Temp Month Day
- 0 41.000000 190.0 7.4 67 5 1
- 1 36.000000 118.0 8.0 72 5 2
- 2 12.000000 149.0 12.6 74 5 3
- 3 18.000000 313.0 11.5 62 5 4
- 4 43.195402 NaN 14.3 56 5 5
- 5 28.000000 NaN 14.9 66 5 6
- 6 23.000000 299.0 8.6 65 5 7
- 7 19.000000 99.0 13.8 59 5 8
- 8 8.000000 19.0 20.1 61 5 9
- 9 43.195402 194.0 8.6 69 5 10
三、总结
了解如何进行数据清洗非常重要,因为它是数据科学的重要组成部分。好在Python提供了非常好用的 Pandas 和 NumPy 库来帮助我们清理数据集,本文介绍的方法都是在实际中经常会用到的,希望大家能牢记于心。