今天主要从一个案例来介绍一下log file sync这个等待事件及常用的一些解决办法,下面先看下故障时间段的等待事件。
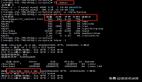
1. 查看卡顿时间段的等待事件及会话
查看故障时间段等待事件、问题sql id及会话访问次数
- select trunc(sample_time, 'mi') tm, sql_id, nvl(event,'CPU'),count(distinct session_id) cnt
- from dba_hist_active_sess_history
- where sample_time between to_date('2019-09-03 9:30:00') and
- to_date('2019-09-03 11:00:00')
- group by trunc(sample_time, 'mi'), sql_id,nvl(event,'CPU')
- order by cnt desc;
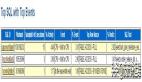
查看该sql相关的等待事件及对应的会话访问次数
- select sql_id, nvl(event, 'CPU'), count(distinct session_id) sz
- from dba_hist_active_sess_history a, dba_hist_snapshot b
- where sample_time between to_date('2019-09-03 09:30:00') and
- to_date('2019-09-03 11:00:00')
- and sql_id = '0spj1q9t1yh2d'
- and a.snap_id = b.snap_id
- and a.instance_number = b.instance_number
- group by sql_id, nvl(event, 'CPU')
- order by sz desc;
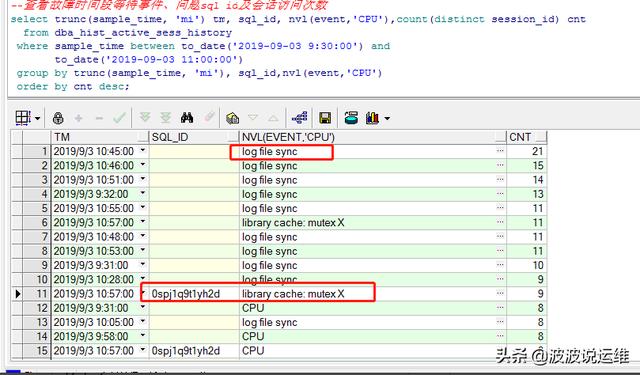
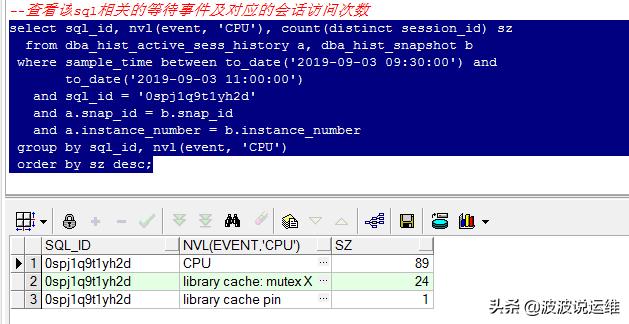
很明显看到都是log file sync等待事件很明显。那什么是log file sync呢?
2. log file sync -- 日志文件同步
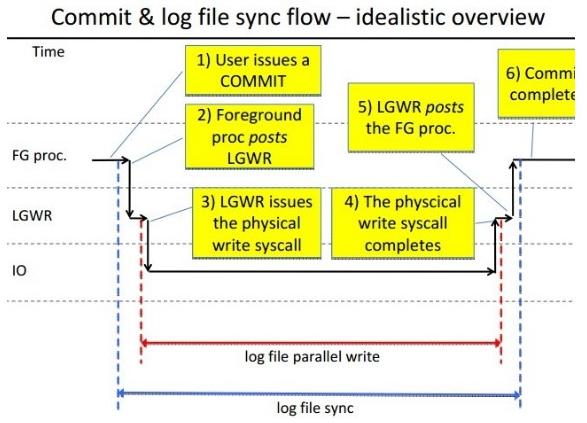
在一个提交(commit)十分频繁的数据库中,一般会出现log file sync等待事件,当这个等待事件出现在top5中,这个时侯我们需要针对log file sync等待事件进行优化,一定要尽快分析并解决问题,否则当log file sync等待时间从几毫秒直接到20几毫秒可能导致系统性能急剧下降,甚至会导致短暂的挂起。
当一个用户提交或回滚数据时, LGWR 将会话期的重做由 Log Buffer 写入到重做日志中,LGWR 完成任务以后会通知用户进程。 日志文件同步等待( Log File Sync) 就是指进程等待LGWR 写完成这个过程, 对于回滚操作,该事件记录从用户发出 rollback 命令到回滚完成的时间。如果该等待过多,可能说明 LGWR 的写出效率低下,或者系统提交过于频繁。 针对该问题,可以关注 log file parallel write 等待事件,或者通过 user commits,user rollback 等统计信息观察提交或回滚次数。
总之,log file sync的根源一般是频繁commit/rollback或磁盘I/O有问题,大量物理读写争用。
可以通过如下公式计算平均 Redo 写大小:
- avg.redo write size = (Redo block written/redo writes)*512 bytes
如果系统产生 Redo 很多,而每次写的较少,一般说明 LGWR 被过于频繁地激活了。 可能导致过多的 Redo 相关 Latch 的竞争, 而且 Oracle 可能无法有效地使用 piggyback 的功能。从一个AWR报告中提取一些数据来研究一下这个问题。
log file sync等待事件的优化方案:
- 优化了redo日志的I/O性能,尽量使用快速磁盘,不要把redo log file存放在raid 5的磁盘上;
- 加大日志缓冲区(log buffer);
- 使用批量提交,减少提交的次数;
- 部分经常提交的事务设置为异步提交;
- 适当使用NOLOGGING/UNRECOVERABLE等选项;
- 采用专用网络,正确设置网络UDP buffer参数;
- 安装最新版本数据库避免bug
3. awr报告--rman备份
收集一下awr报告来分析,收集过程这里就不做介绍了。
(1) 报告如下:
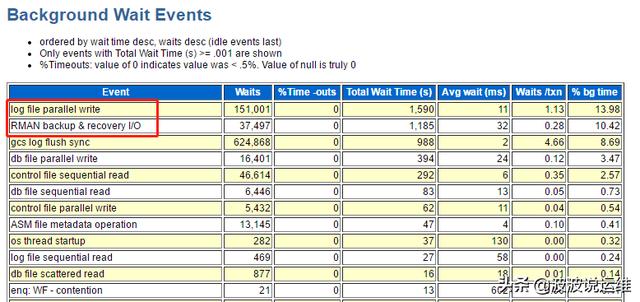
这里可以注意到有一个异常的等待事件--RMAN backup & recovery I/O,应该是rman刚好在做备份导致的磁盘IO繁忙
(2) 观察RMAN日志
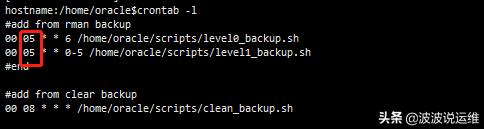
很明显是从凌晨5点开始备份,一直备份到接近10点导致,这里也消耗了一部分的磁盘IO
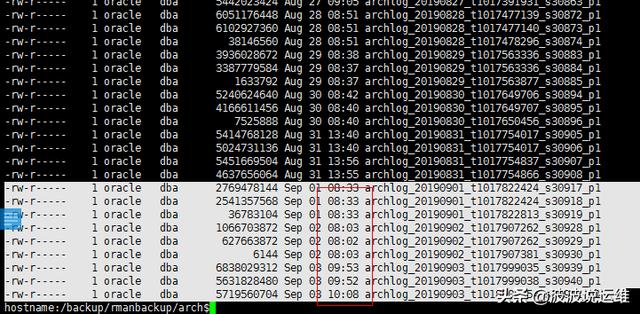
(3) 调整备份时间
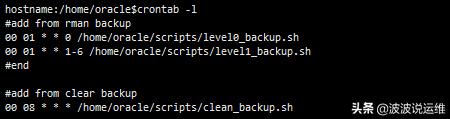
下面回到log file sync的分析上。
4. awr报告--log file sync
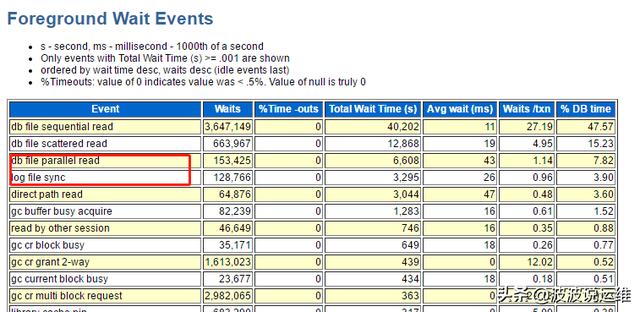
注意以上输出信息,这里 log file sync 和 db file parallel write 等等待事件同时出现,那么可能的一个原因是 I/O 竞争导致了性能问题, 实际用户环境正是日志文件和数据文件同时存放在 RAID5 的磁盘上,存在性能问题需要调整。
(RAID 5不对数据进行备份,而是把数据和与其相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上。当RAID5的一个磁盘数据损坏后,利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。)
5. 计算平均日志写大小:
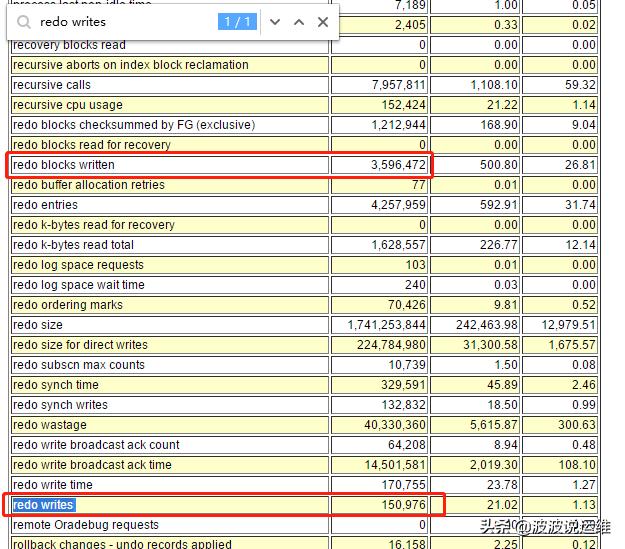
- avg.redo write size = (Redo block written/redo writes)*512 bytes= ( 3,596,472/ 150,976 )*512 =12196 bytes =11KB
这个平均值有点小了,说明系统的提交过于频繁。
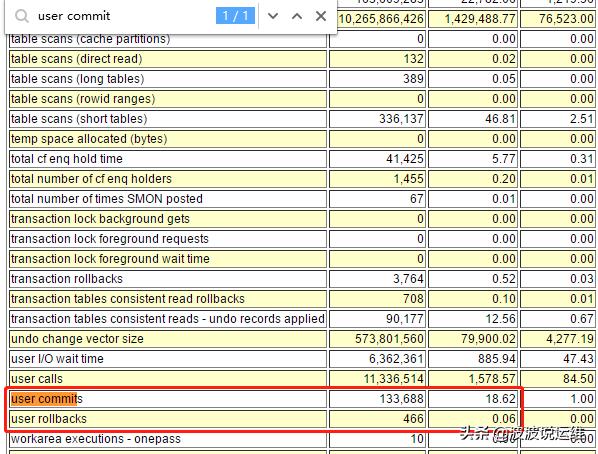
从以上的统计信息中, 可以看到平均每秒数据库的提交数量是18.62 次。 如果可能, 在设计应用时应该选择合适的提交批量,从而提高数据库的效率。
6. Oracle11g新特性(Adaptive Log File Sync - 自适应的Log File Sync)
关于 Log File Sync 等待的优化,在Oracle数据库中一直是常见问题,LOG FILE的写出性能一旦出现波动,该等待就可能十分突出。
在Oracle 11.2.0.3 版本中,Oracle 将隐含参数 _use_adaptive_log_file_sync 的初始值设置为 TRUE,由此带来了很多 Log File Sync 等待异常的情况,当前台进程提交事务(commit)后,LGWR需要执行日志写出操作,而前台进程因此进入 Log File Sync 等待周期。
在以前版本中,LGWR 执行写入操作完成后,会通知前台进程,这也就是 Post/Wait 模式;在11gR2 中,为了优化这个过程,前台进程通知LGWR写之后,可以通过定时获取的方式来查询写出进度,这被称为 Poll 的模式,在11.2.0.3中,这个特性被默认开启。这个参数的含义是:数据库可以在自适应的在 post/wait 和 polling 模式间选择和切换。
_use_adaptive_log_file_sync 参数的解释就是: Adaptively switch between post/wait and polling ,正是由于这个原因,带来了很多Bug,反而使得 Log File Sync 的等待异常的高,在遇到问题时,通常将 _use_adaptive_log_file_sync 参数设置为 False,回归以前的模式,将会有助于问题的解决。
这里我的数据库版本是11.2.0.1,检查发现也有这种情况,所以做了一些参数上的调整:
- SQL> show parameter parallel_adaptive_multi_user;
- SQL> alter system set parallel_adaptive_multi_user=false scope=both;