













本文我们将探索如何创建一个能够交付并支持快速创新的软件架构。提出一种能够处理大量现有数据、响应用户交互并易于试验新的推荐方法的软件体系结构并非易事。在这篇文章中,我们将描述我们如何解决Netflix面临的一些挑战。
首先,我们在下图中展示了推荐系统的总体系统图。该体系结构的主要组件包含一个或多个机器学习算法。
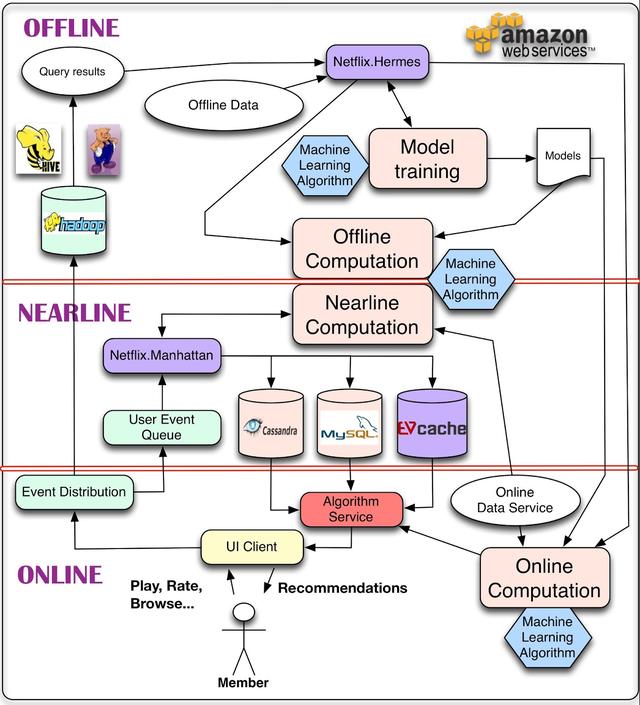
对于数据,我们能做的最简单的事情就是将其存储起来,以便稍后进行脱机处理,这就引出了管理脱机作业的部分体系结构。然而,计算可以离线、近线或在线进行。在线计算可以更好地响应最近的事件和用户交互,但必须实时响应请求。这可以限制所使用算法的计算复杂度以及可处理的数据量。离线计算对数据量和算法的计算复杂度的限制较小,因为它以批处理方式运行,对时间的要求比较宽松。但是,由于没有包含最新的数据,在更新的过程中很容易变得陈旧。
个性化体系结构中的一个关键问题是如何以无缝的方式组合和管理在线和离线计算。近线计算是这两种模式之间的一种折衷,在这种模式下,我们可以执行类似于在线的计算,但不要求它们是实时的。模型训练是使用现有数据生成模型的另一种计算形式,该模型稍后将在实际计算结果时使用。体系结构的另一部分描述了事件和数据分发系统需要如何处理不同类型的事件和数据。一个相关的问题是如何组合不同的信号和模型,这些信号和模型是离线、近线和在线系统所需要的。最后,我们还需要找出如何以一种对用户有意义的方式组合中间推荐结果。
本文的其余部分将详细介绍此体系结构的这些组件及其交互。为了做到这一点,我们将把一般的图分解成不同的子系统,并且我们将详细讨论每一个子系统。当您继续阅读本文时,值得记住的是,我们的整个基础设施都运行在公共Amazon Web Services云上。
Offline, Nearline, and Online Computation
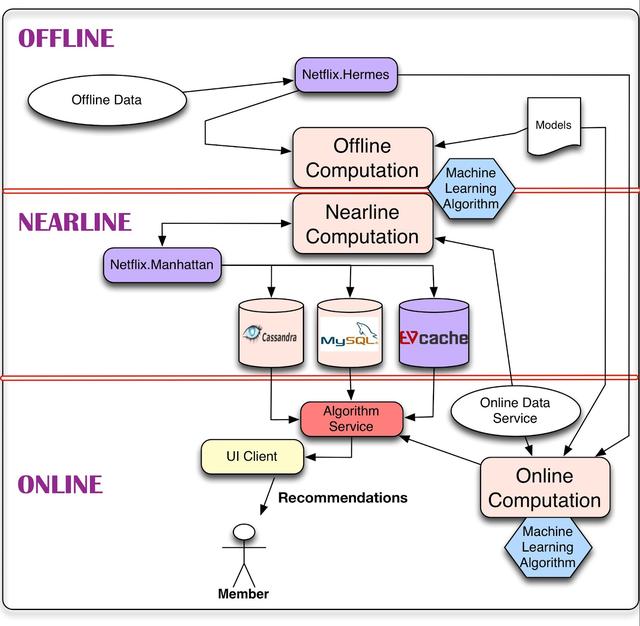
如上所述,我们的算法结果既可以在线实时计算,也可以离线批量计算,或者在两者之间的近线计算。每种方法都有其优点和缺点,需要考虑到每种用例。
在线计算可以快速响应事件并使用最新的数据。例如,使用当前上下文为成员组装一个动作电影库。在线组件受可用性和响应时间服务级别协议(SLA)的约束,SLA指定了在我们的成员等待建议出现时响应客户端应用程序请求的流程的最大延迟。这使得用这种方法来拟合复杂且计算量大的算法变得更加困难。此外,在某些情况下,纯在线计算可能无法满足其SLA,因此考虑快速回退机制(如恢复到预计算结果)总是很重要的。在线计算还意味着所涉及的各种数据源也需要在线可用,这可能需要额外的基础设施。
另一方面,离线计算允许在算法方法上有更多的选择,比如复杂的算法,并且对使用的数据量有更少的限制。一个简单的例子可能是定期聚合来自数百万电影播放事件的统计数据,以编译推荐的基准流行度指标。离线系统也有更简单的工程需求。例如,可以很容易地满足客户机施加的宽松响应时间sla。可以在生产环境中部署新的算法,而不需要在性能调优方面投入太多精力。这种灵活性支持敏捷创新。在Netflix,我们利用这个来支持快速实验:如果一个新的实验算法执行慢,我们可以选择简单的部署更多的Amazon EC2实例来达到所需的吞吐量运行实验,而不是花费宝贵的工程时间算法的优化性能,可能小的业务价值。然而,由于离线处理没有很强的延迟需求,它不会对上下文或新数据中的更改做出快速反应。最终,这可能导致过时,降低成员的体验。离线计算还需要存储、计算和访问大量预计算结果集的基础设施。
近线计算可以看作是前两种模式的折衷。在本例中,计算的执行与在线情况完全相同。但是,我们删除了在计算结果时立即提供结果的需求,并可以存储它们,从而允许它是异步的。近线计算是根据用户事件进行的,因此系统可以在请求之间做出更快速的响应。这为每个事件可能进行的更复杂的处理打开了大门。例如,更新建议,以反映在成员开始观看电影之后,电影已经立即被观看。结果可以存储在中间缓存或后端存储中。近线计算也是应用增量学习算法的一种自然设置。
在任何情况下,选择联机/近线/脱机处理都不是一个非此即非的问题。所有的方法都可以而且应该结合起来。组合它们的方法有很多。我们已经提到了使用离线计算作为备份的想法。另一种选择是使用离线进程预先计算结果的一部分,而将算法中成本较低或上下文敏感的部分留给在线计算。
甚至建模部分也可以以离线/在线混合方式完成。在传统的监督分类应用中,分类器必须从标记数据批量训练,并且只能在线应用于对新输入进行分类,这并不自然适合。然而,矩阵分解等方法更自然地适合于混合的在线/离线建模:一些因素可以离线预先计算,而另一些可以实时更新,以创建更新鲜的结果。其他非监督方法,如集群,也允许离线计算集群中心和在线分配集群。这些例子表明,一方面可以将我们的模型培训划分为大规模的、潜在复杂的全局模型培训,另一方面可以在线执行更轻松的特定于用户的模型培训或更新阶段。
Offline Jobs
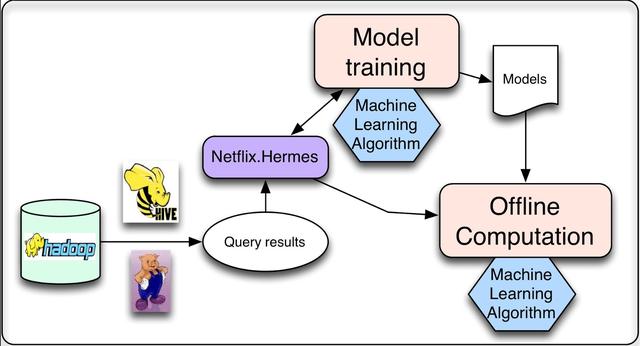
当运行个性化机器学习算法时,我们需要做的大部分计算都可以离线完成。这意味着可以将作业计划为定期执行,并且它们的执行不需要与结果的请求或表示同步。这类任务主要有两类:模型训练和中间结果或最终结果的批处理计算。在模型训练工作中,我们收集相关的现有数据,应用机器学习算法生成一组模型参数(我们将其称为模型)。这个模型通常会被编码并存储在一个文件中供以后使用。虽然大多数模型都是离线批处理模式培训的,但我们也有一些在线学习技术,其中增量培训确实是在线执行的。批量计算结果是上面定义的离线计算过程,我们使用现有的模型和相应的输入数据来计算结果,这些结果将在稍后用于后续的在线处理或直接呈现给用户。
这两个任务都需要处理精制的数据,而这些数据通常是通过运行数据库查询生成的。由于这些查询运行在大量数据上,因此以分布式方式运行它们是有益的,这使得它们非常适合通过Hive或Pig作业在Hadoop上运行。一旦查询完成,我们就需要一种发布结果数据的机制。我们对该机制有几个要求:首先,当查询结果准备好时,它应该通知订阅者。其次,它应该支持不同的存储库(例如,不仅支持HDFS,还支持S3或Cassandra)。最后,它应该透明地处理错误,允许监视和警报。在Netflix,我们使用一个名为Hermes的内部工具,它提供所有这些功能,并将它们集成到一个一致的发布-订阅框架中。它允许向订阅者提供近乎实时的数据。在某种意义上,它涵盖了与Apache Kafka相同的一些用例,但它不是消息/事件队列系统。
信号和模型
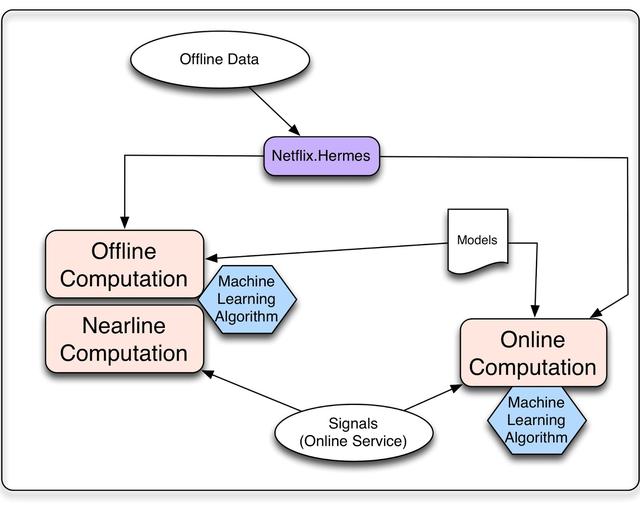
无论我们是在线计算还是离线计算,我们都需要考虑算法将如何处理三种输入:模型、数据和信号。模型通常是之前离线训练的参数的小文件。数据是预先处理的信息,这些信息已经存储在某种数据库中,比如电影元数据或流行度。我们使用"信号"这个术语来指代我们输入到算法中的新信息。这些数据来自live services,可以由用户相关的信息(如成员最近观看了什么)或上下文数据(如会话、设备、日期或时间)组成。
Event & Data Distribution
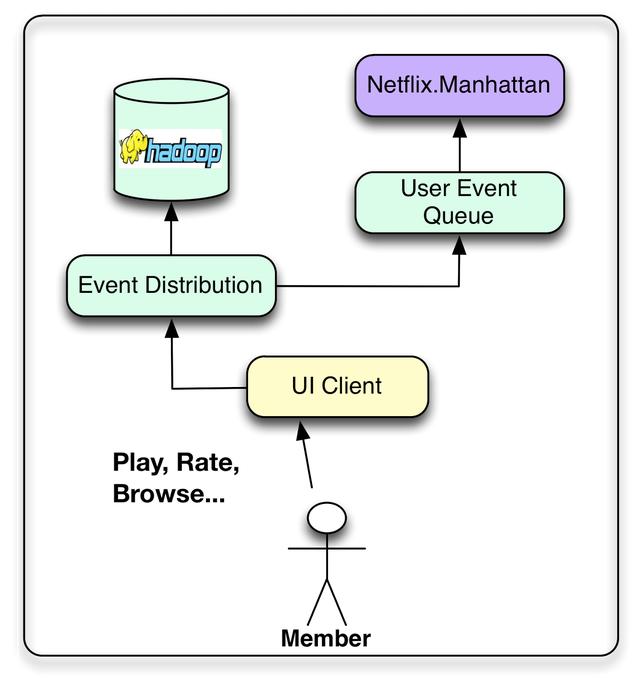
我们的目标是将成员交互数据转换为可用于改进成员体验的洞察力。因此,我们希望Netflix的各种用户界面应用程序(智能电视、平板电脑、游戏机等)不仅能提供令人愉快的用户体验,还能收集尽可能多的用户事件。这些操作可以与任何时候的单击、浏览、查看,甚至是视图的内容相关。然后可以聚合事件,为我们的算法提供基本数据。在这里,我们试图在数据和事件之间做出区分,尽管边界肯定是模糊的。我们认为事件是时间敏感信息的小单元,需要以尽可能少的延迟处理。这些事件被路由来触发后续的操作或过程,例如更新近线结果集。另一方面,我们认为数据是更密集的信息单元,可能需要处理和存储以便稍后使用。在这里,延迟并不像信息的质量和数量那么重要。当然,有些用户事件可以同时作为事件和数据处理,因此可以发送到两个流。
在Netflix,我们近乎实时的活动流程是通过一个名为Manhattan的内部框架来管理的。曼哈顿是一个分布式计算系统,它是我们推荐算法体系结构的核心。这有点类似于Twitter的Storm,但它解决了不同的问题,并响应了不同的一组内部需求。数据流主要通过从Chukwa到Hadoop的日志记录来管理,以完成流程的初始步骤。稍后,我们使用Hermes作为发布-订阅机制。
推荐结果
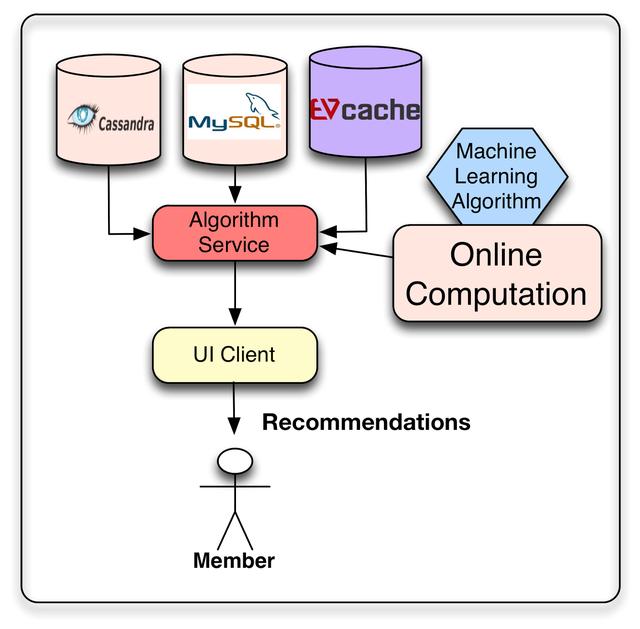
我们机器学习方法的目标是提出个性化的建议。这些推荐结果可以直接从我们之前计算过的列表中得到,也可以通过在线算法动态生成。当然,我们可以考虑同时使用这两种方法,离线计算推荐的大部分内容,并使用使用实时信号的在线算法对列表进行后处理,从而增加一些新鲜度。
在Netflix,我们将离线和中间结果存储在各种存储库中,以便稍后在请求时使用:我们使用的主要数据存储库是Cassandra、EVCache和MySQL。每种解决方案都有其优缺点。MySQL允许存储结构化关系数据,这些数据将来可能需要通过通用查询进行处理。然而,这种通用性是以分布式环境中的可伸缩性问题为代价的。Cassandra和EVCache都提供了键值存储的优点。当需要分布式和可伸缩的无sql存储时,Cassandra是一个著名的标准解决方案。Cassandra在某些情况下工作得很好,但是在我们需要密集且持续的写操作的情况下,我们发现EVCache更适合。然而,关键问题不在于将它们存储在哪里,而在于如何以一种相互冲突的目标(如查询复杂性、读写延迟和事务一致性)在每个用例的最优点上满足的方式处理需求。
结论
在以前的文章中,我们强调了数据、模型和用户界面对于创建世界级推荐系统的重要性。在构建这样一个系统时,还必须考虑将在其中部署该系统的软件体系结构。我们希望能够使用复杂的机器学习算法,可以增长到任意的复杂性,并能够处理大量的数据。我们还需要一个允许灵活和敏捷创新的体系结构,在这个体系结构中可以轻松地开发和插入新方法。此外,我们希望我们的推荐结果是新鲜的,并快速响应新的数据和用户操作。在这些需求之间找到最佳平衡点并非易事:它需要对需求进行深思熟虑的分析,仔细选择技术,并对推荐算法进行战略性分解,从而为我们的成员实现最佳结果。











