Kubernetes设计的初衷是运行无状态工作负载。这些通常采用微服务架构的工作负载,是轻量级,可水平扩展,遵循十二要素应用程序,可以处理环形断路和随机Monkey测试。
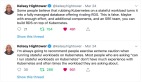
另一方面,Kafka本质上是一个分布式数据库。这意味着你必须处理状态,它比微服务更重量级。Kubernetes支持有状态的工作负载,但你必须谨慎对待它,正如Kelsey Hightower在最近的两条推文中指出的那样:
现在你应该在Kubernetes上运行Kafka吗?我的反问是:没有它,Kafka会跑得更好吗?这就是为什么我要指出Kafka和Kubernetes之间的相互补充性以及你可能遇到的陷阱。
一、运行时
让我们先看一下基本的东西——运行时本身。
1、进程
Kafka brokers对CPU很友好。TLS可能会引入一些开销。如果Kafka客户端使用加密,则需要更多CPU,但这不会影响brokers。
2、内存
Kafka brokers是内存消耗大户。JVM堆通常可以限制为4-5 GB,但由于Kafka大量使用页面缓存,因此还需要足够的系统内存。在Kubernetes中,可以相应地设置容器资源限制和请求。
3、存储
容器中的存储是短暂的——重启后数据将丢失。可以对Kafka数据使用emptyDir卷,这将产生相同的效果:brokers的数据将在停机后丢失。您的消息在其他broker上作为副本还是可以使用的。因此,重新启动后,失败的broker必须得复制所有的数据,这可能是一个耗时过程。
这就是你应该使用持久存储的原因。使用XFS或ext4的非本地持久性块存储更合适。我警告你:不要使用NFS。NFS v3和v4都不会起作用。
简而言之,Kafka broker会因为NFS“愚蠢重命名”问题而无法删除数据目录,自行终止。如果你仍然不相信我,那么请仔细阅读这篇博文[1]。存储必须是非本地的,以便Kubernetes在重新启动或重新定位时可以更灵活地选择另一个节点。
4、网络
与大多数分布式系统一样,Kafka性能在很大程度上取决于低网络延迟和高带宽。不要试图将所有代理放在同一节点上,因为这会降低可用性。
如果Kubernetes节点出现故障,那么整个Kafka集群都会出现故障。不要跨数据中心扩展Kafka集群。这同样适用于Kubernetes集群。不同的可用区域是一个很好的权衡。
二、配置
1、清单
Kubernetes网站包含一个非常好的教程[2],介绍如何使用清单设置ZooKeeper。由于ZooKeeper是Kafka的一部分,因此可以通过这个了解哪些Kubernetes概念被应用在这里。一旦理解,您也可以对Kafka集群使用相同的概念。
1)Pod
Pod是Kubernetes中最小的可部署单元。它包含您的工作负载,它代表群集中的一个进程。一个Pod包含一个或多个容器。整体中的每个ZooKeeper服务器和Kafka集群中的每个Kafka broker都将在一个单独的Pod中运行。
2)StatefulSet
StatefulSet是一个Kubernetes对象,用于处理需要协调的多个有状态工作负载。StatefulSets保证Pod的有序性和唯一性的。
3)Headless Services
服务通过逻辑名称将Pod与客户端分离。Kubernetes负责负载平衡。但是,对于ZooKeeper和Kafka等有状态工作负载,客户端必须与特定实例进行通信。这就是 Headless Services发挥作用的地方:作为客户端,仍然可以获得逻辑名称,但不必直接访问Pod。
4)持久卷
如上所述,需要配置非本地持久块存储。
Yolean[3]提供了一套全面的清单,可以帮助您开始使用Kubernetes上的Kafka。
2、Helm Charts
Helm是Kubernetes的包管理器,类似yum,apt,Homebrew或Chocolatey等OS包管理器。它允许您安装Helm Charts中描述的预定义软件包。
精心设计的Helm Charts能简化所有参数正确配置的复杂任务,以便在Kubernetes上运行Kafka。有几张图表适用于Kafka的的可供选择:一个是处于演进状态的官方图表[4],一个来自Confluent,另一个来自Bitnami,仅举几例。
3、Operators
由于Helm的一些限制,另一种工具变得非常流行:Kubernetes Operators。Operators不仅可以为Kubernetes打包软件,还可以为Kubernetes部署和管理一个软件。
评价很高的Operators名单中提到Kafka有两个,其中一个是Strimzi[5],Strimzi使得在几分钟内启动Kafka集群变得非常容易,几乎不需要任何配置,它增加了一些漂亮的功能,如群集间点对点TLS加密。Confluent还宣布即将推出新的Operator。
4、性能
运行性能测试以对Kafka安装进行基准测试非常重要。在您遇到麻烦之前,它会为您提供有关可能的瓶颈的地方。
幸运的是,Kafka已经提供了两个性能测试工具:kafka-producer-perf-test.sh和kafka-consumer-perf-test.sh。记得经常使用它们。作为参考,可以使用Jay Kreps的博客结果[6],或者 Stéphane Maarek在 Amazon MSK的评论[7]。
三、运维
1、监控
可见性非常重要,否则您将不知道发生了什么。如今,有一种不错的工具可以用云原生方式监控指标。Prometheus和Grafana是两种流行的工具。Prometheus可以直接从JMX导出器收集所有Java进程(Kafka,ZooKeeper,Kafka Connect)的指标。添加cAdvisor指标可为提供有关Kubernetes资源使用情况的其他信息。
Strimzi为Kafka提供了一个优雅的Grafana仪表板示例。它以非常直观的方式可视化关键指标,如未复制的和离线分区。它通过资源使用和性能以及稳定性指标来补充这些指标。因此,可以免费获得基本的Kafka集群监控!
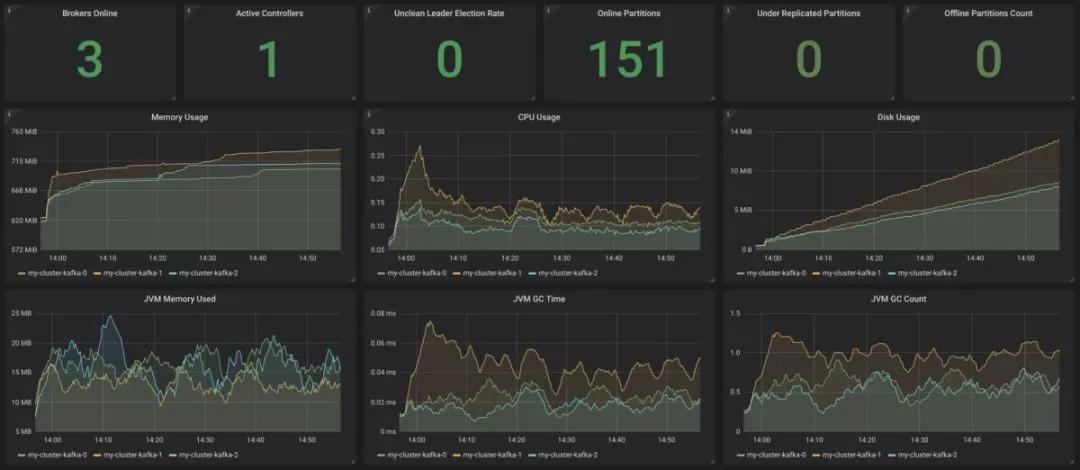
▲ 资料来源:https://strimzi.io/docs/master/#kafka_dashboard
可以通过客户端监控(消费者和生产者指标),使用Burrow滞后监控,使用Kafka Monitor[8]进行端到端监控,来完成这个任务。
2、日志记录
日志记录是另一个关键部分。确保Kafka安装中的所有容器都记录到标准输出(stdout)和标准错误输出(stderr),并确保Kubernetes集群将所有日志聚合到中央日志记录设施中如Elasticsearch中。
3、健康检查
Kubernetes使用活跃度和就绪探测器来确定Pod是否健康。如果活跃度探测失败,Kubernetes将终止容器并在相应设置重启策略时自动重启。如果准备就绪探测失败,那么Kubernetes将通过服务从服务请求中删除该Pod。这意味着在这种情况下不再需要人工干预,这是一大优点。
4、滚动更新
StatefulSets支持自动更新:滚动更新策略将一次更新一个Kafka Pod。通过这种方式,可以实现零停机时间,这是Kubernetes带来的另一大优势。
5、扩展
扩展Kafka集群并非易事。但是,Kubernetes可以很容易地将Pod缩放到一定数量的副本,这意味着可以声明式地定义所需数量的Kafka brokers。困难的部分是在放大或缩小之前重新分配部分。同样,Kubernetes可以帮助您完成这项任务。
6、管理
通过在Pod中打开shell,可以使用现有的shell脚本完成Kafka群集的管理任务,例如创建主题和重新分配分区。这不是一个很好的解决方案。Strimzi支持与另一个Operator管理主题。这还有改进的余地。
7、备份和还原
现在Kafka的可用性还取决于Kubernetes的可用性。如果Kubernetes群集出现故障,那么在最坏的情况下Kafka群集也会故障。
墨菲定律告诉我们,这也会发生在你身上,你会丢失数据。要降低此风险,请确保您具有备份想法。MirrorMaker是一种可选方案,另一种可能是利用S3进行连接备份,如Zalando的博客文章[9]所述。
四、结论
对于中小型Kafka集群,我肯定会选择Kubernetes,因为它提供了更大的灵活性并简化了操作。如果您在延迟和/或吞吐量方面具有非常高的非功能性要求,则不同的部署选项可能更有益。
>>>>
参考链接
[1]https://engineering.skybettingandgaming.com/2018/07/10/kafka-nfs/
[2]https://kubernetes.io/docs/tutorials/stateful-application/zookeeper/
[3]https://github.com/Yolean/kubernetes-kafka
[4]https://github.com/helm/charts/tree/master/incubator/kafka
[5]https://strimzi.io/
[6]https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
[7]https://medium.com/@stephane.maarek/an-honest-review-of-aws-managed-apache-kafka-amazon-msk-94b1ff9459d8
[8]https://github.com/linkedin/kafka-monitor
[9]https://jobs.zalando.com/tech/blog/backing-up-kafka-zookeeper/
原文链接:https://blog.usejournal.com/kafka-on-kubernetes-a-good-fit-95251da55837