分布式缓存方面,redis勇夺花魁。但对于消息队列mq来说,还处于百花齐放的年代。

缓存系统,基本上解决一个存取问题,就万事大吉了,调用是同步的。对于消息队列来说,就不太一样。它的使用场景多样,可靠级别多变,从生产端到消费端,过程是异步的。
消息系统的设计要点,有很多。现在,很难有一个消息系统,能够兼顾下面提到的设计要点。它要是说可以,那就是母体在吹。
所以很多时候,现在流行的Kafka、RabbitMQ、RocketMQ等,会被同时使用。如果你在做相关方面的选型,下面这些技术点就是权衡之处。那句话叫什么来着:牝鸡司晨,惟家之索。
要点
本文将针对这些mq,从整体上抽象一些共有特性。包括:协议、类型、消费方式、堆积能力、高可用、高可靠、高性能、扩展性和生态。如果你想要深入某个mq,这里也有几篇关于kafka的文章。
高可用
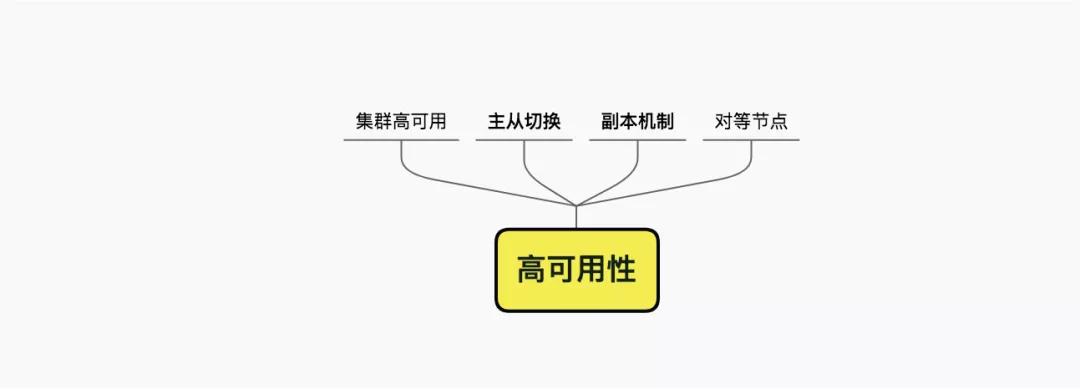
高可用主要解决集群单节点,在异常情况下的failover和HA。解决高可用问题的一般思路就是副本机制。
通过增加副本,可以将数据的风险分散到多台机器上。这就需要在主分片出现问题时,能够从副本中找出一个作为新的主分片。有很多这样的协调工具,比如zk。也有的mq,自己去实现这个过程。
有的模式就比较浪费资源了,比如rocketmq,使用standby从机进行高可用保证,出问题再顶上来。
高可靠
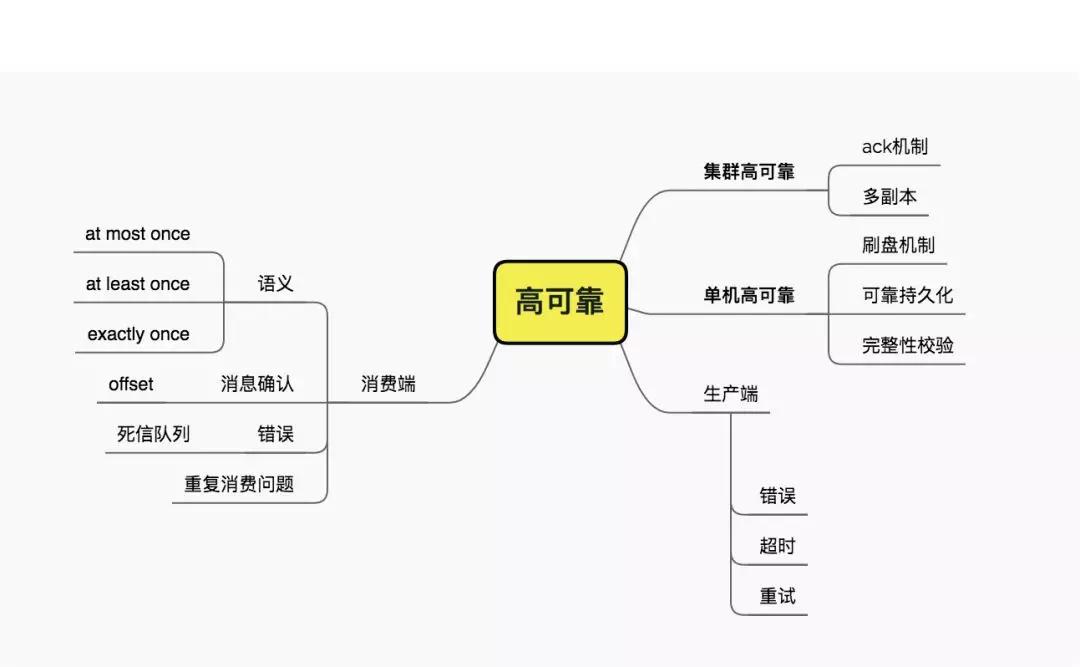
消息系统的可靠性和性能是相悖的。一般的mq,可靠性级别都是可以调节的,但性能会发生相反的联动性。从消息级别来说,大体路线有:
发出去就不管了->单节点确认->多节点确认->多节点确认同步刷盘->所有节点同步刷盘->事务消息等。
单机高可靠
集群的高可靠方面,会有ack机制和多副本机制进行保证。对于单个节点来说,断电或者主机异常,会是一个比较大的挑战。为了处理这种情况,需要有刷盘机制或者其他持久化机制。同时,数据的完整性校验也是需要的,这也是类似kafka这种消息系统,数据量大的时候,启动时间非常长的原因。
生产端
生产端除了要考虑buffer丢失的问题,还要考虑到一些发送错误的情况,包括与集群通信的超时和重试处理。
消费端
消费端通过消息确认机制来保证消息已经被正确消费。由于其间会发生很多异常情况,所以大多数消息系统保证at least once语义。即确保消息至少被消费1次。
言外之意,消息是会重复的,消费者需要做到幂等,保证重复消费不会引起业务异常。
消费端同样会发生一些错误情况,有些mq可以在多次消费失败后自动进入死信队列,有些mq需要自行设计topic进行规划。
高性能
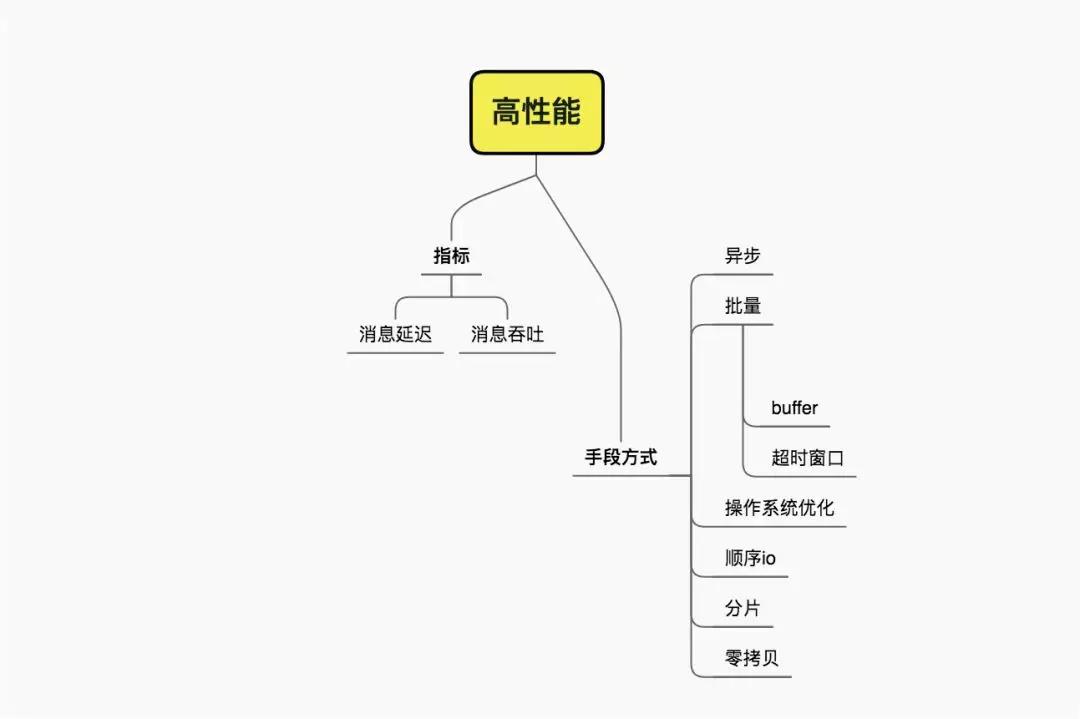
作为一个数据传输的通道,性能是一个非常有分量的考量点。其中两个比较重要的指标,一个是消息的延迟性,一个就是消息的吞吐量。
消息从生产端发出,到消费者处理,其间的过程不能太长,对于使用拉模式来消费的mq来说,就要加快轮询速度,并使用零拷贝一类的技术加快数据传输。
对于消息吞吐量来说,是一个生产端、mq节点、消费端共同优化的结果。目前主要有以下手段:
异步化
消息采用异步发送的方式,发送端不用同步等待,加快了处理速度。
batch
采用批量发送的方式,减少网络传输的次数,方便进行数据压缩。一般是内存中缓冲一个buffer,如果buffer满了,或者到达了时间窗口,则进行一次传输。这能够显著增加传输速度,但处理不当容易丢失数据。
顺序IO
xjjdog已经在多篇文章提到,顺序性操作磁盘,比随机操作内存速度快的多。这也是kafka之类的消息队列速度快的原因之一,但要注意主题的数量(想下为什么)。
另外,还有其他手段。比如优化操作系统参数,使用分片增加并行度等。
消息类型
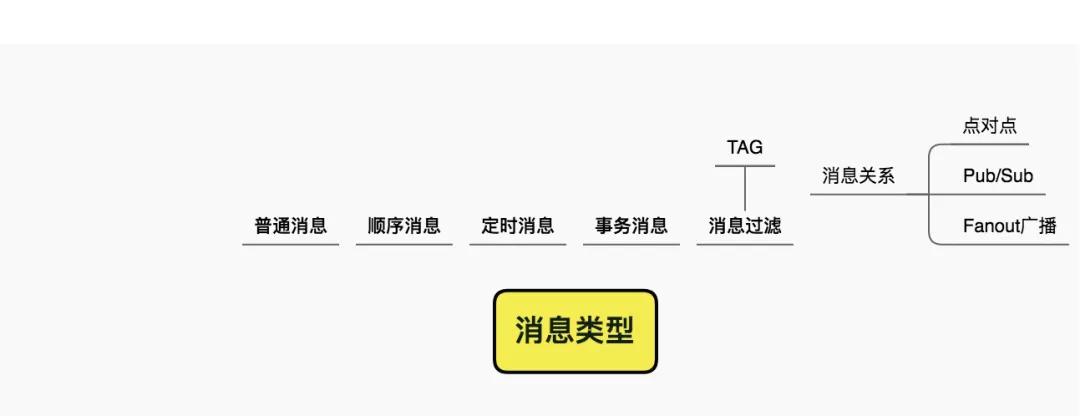
消息有点对点的,一条消息只会被消费一次。Pub/Sub通过发布/订阅模式,一条消息能够被多个消费端消费。还有一种消息是通过广播模式进行广播,即producer发送消息,所有的consumer都会收到。
除了普通发送的消息,还有一些特殊用途的消息。顺序性消息有全局有序和分区有序之分,一般用于有严格顺序要求的业务。通过业务的设计,可以规避全局有序这种非常耗性能的操作。
有些mq还支持定时消息(私以为这种放业务系统更佳)。事务消息更加耗费性能,慎用。
还有一些mq,提供打tag、进行消息过滤的功能。比如订单信息发送到一个topic,消费者只订阅相关商品的订单,某些有求隔离的情况,非常有用。
消费模式
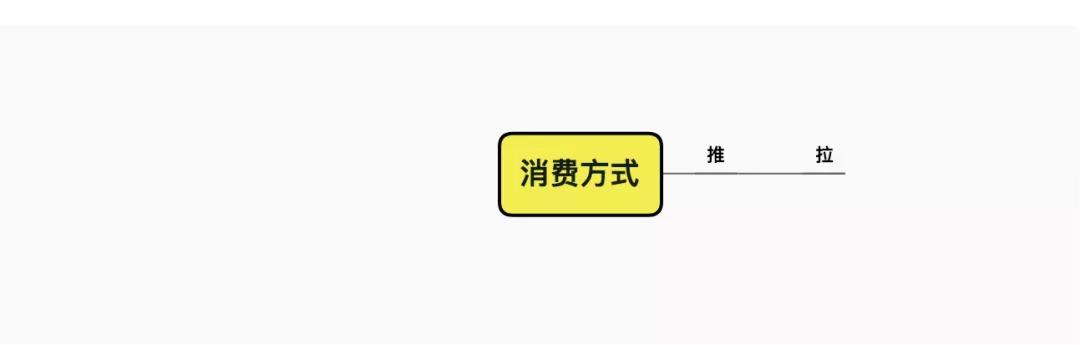
消费模式,主要有推模式和拉模式。拉模式最为实用和流行,因为消费处理速度可以由消费端进行调节。
推模式的实时性更好一些,但不好评估消费端能力,容易将其压垮。同时,处理pub/sub,失败重试等,也有很多挑战。
协议
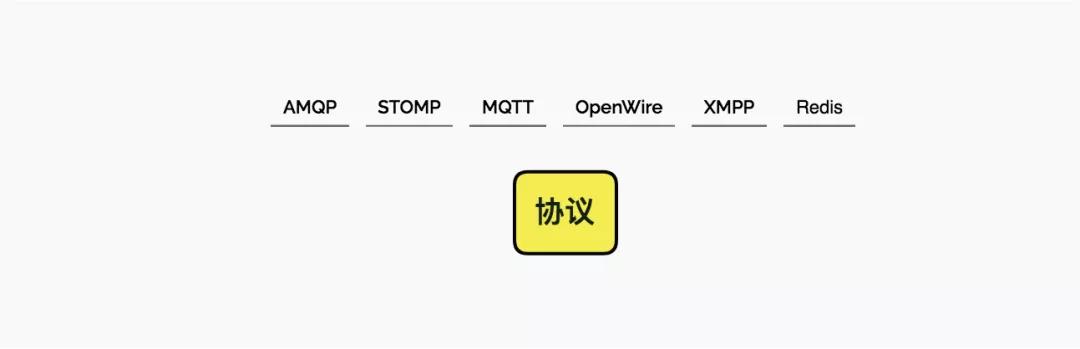
大家都知道java中有一个JMS规范,但是类似于kafka这种却没有实现这个规范。所以一些协议,比如amqp、openwire等,有更加明显的定制型。
这个传输协议,与功能关系不大。比如就有基于http协议的,或者redis协议,甚至websocket之上的stomp。
mqtt是物联网IoT的应用协议,你会发现一大坨基于它的消息队列。
堆积能力

现在的数据都长这么大,mq的堆积能力是非常非常重要的。就拿redis这种内存型的队列来说,分分钟就给撑爆。mq除了作为消息处理的通道,还可以作为备用存储用。
堆积能力的体现在海量存储上,比如存放在数据库中(矛盾转移),挂载非常大的磁盘等。但别高兴的太早,大型集群的启动加载,以及故障再平衡,通常会花费比较长的时间。
堆积能力的另外一个体现,就是对历史消息的清理。一般有两个策略:磁盘上线和过期清理,可以结合需求灵活设置。
生态
一个开源软件的生态是非常重要的,对于mq来说也是如此。主要体现在两个方面,一个是支持的的开发语言多样(需要提供producer和consumer两方的包),一个是针对周边软件的支持。比如spring,spark,hadoop,flink等,减少集成成本。
这方面除了比较新的mq系统,都做的不错。
消息系统的作用
消息系统在目前的分布式系统中设计中,作用越来越大。它的使用场景,包括但不限于:
削峰 用于承接超出业务系统处理能力的请求,使业务平稳运行。这能够大量节约成本,比如某些秒杀活动,并不是针对峰值设计容量。
缓冲 在服务层和缓慢的落地层作为缓冲层存在,作用与削峰类似,但主要用于服务内数据流转。比如批量短信发送。
解耦 项目尹始,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。
冗余 消息数据能够采用一对多的方式,供多个毫无关联的业务使用。
健壮性 消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。
End
根据消息的体量和用途,目前可以将分布式mq大体分为两类。
一类用于业务系统,保证极高的可靠性。要求不能够丢失消息,比如订单、支付等,有较高的SLA服务水准。这种情况,对mq的功能要求也比较多,包括消息的可查性。
另外一类用于大数据相关的系统,典型的特点就是吞吐量非常大。异常情况下,丢失几条消息,无伤大雅。
但消息系统,可能关注的只是mq本身。怎么保证生产端、消费端、mq本身三者的可用性,是需要业务进行权衡的。
比如,前段时间xjjdog开源的okmq,就是用来解决一个特定场景的高可用问题。
开源一个kafka增强:okmq-1.0.0