GPU、TPU、CPU 都可以用于深度学习模型的训练,那么这几个平台各适用于哪种模型,又各有哪些瓶颈?在本文中,来自哈佛的研究者设计了一个用于深度学习的参数化基准测试套件——ParaDnn,旨在系统地对这些深度学习平台进行基准测试。
ParaDnn 能够为全连接(FC)、卷积(CNN)和循环(RNN)神经网络生成端到端的模型。研究者使用 6 个实际模型对谷歌的云 TPU v2/v3、英伟达的 V100 GPU、以及英特尔的 Skylake CPU 平台进行了基准测试。他们深入研究了 TPU 的架构,揭示了它的瓶颈,并重点介绍了能够用于未来专业系统设计的宝贵经验。他们还提供了平台的全面对比,发现每个平台对某些类型的模型都有自己独特的优势。最后,他们量化了专用的软件堆栈对 TPU 和 GPU 平台提供的快速性能改进。
- 论文:Benchmarking TPU, GPU, and CPU Platforms for Deep Learning
- 论文链接:https://arxiv.org/pdf/1907.10701.pdf
常用硬件及基准都有啥
TPU v2 发布于 2017 年 5 月,它是一款定制的专用集成电路(ASIC)。每个 TPU v2 设备能够在单板上提供 180 TFLOPS 的峰值算力。一年之后 TPU v3 发布,它将峰值性能提高到了 420 TFLOPS。云 TPU 于 2018 年 2 月开始提供学术访问权限。这篇论文中使用的就是云 TPU。
英伟达的 Tesla V100 Tensor Core 是一块具有 Volta 架构的 GPU,于 2017 年发布。
CPU 已经被证明在某些特定的用例中会更加适合训练,因此它也是一个重要的平台,应该被包含在比较内容中。
这项研究表明,没有一个平台在所有的场景中是最佳的。基于它们各自的特点,不同的平台能够为不同的模型提供优势。此外,由于深度学习模型的快速改进和变化,基准测试也必须持续更新并经常进行。
最近的基准测试似乎都局限于任意的几个 DNN 模型。只盯着著名的 ResNet50 和 Transformer 等模型可能会得到误导性的结论。例如,Transformer 是一个大型的全连接模型,它在 TPU 上的训练速度比在 GPU 上快了 3.5 倍;但是,关注这一个模型并不能揭示 TPU 在超过 4000 个节点的全连接网络上出现的严重的内存带宽瓶颈。这凸显了为某些模型去过度优化硬件和(或)编译器的风险。
新一代硬件基准测试
为了对最先进的深度学习平台进行基准测试,这篇论文提出了一个用于训练的深度学习模型集合。为了支持广泛和全面的基准测试研究,研究者引入了 ParaDnn 这一参数化的深度学习基准测试组件。ParaDnn 能够无缝地生成数千个参数化的多层模型,这些模型由全连接(FC)模型、卷积神经网络(CNN)以及循环神经网络(RNN)组成。ParaDnn 允许对参数规模在近乎 6 个数量级的模型上进行系统基准测试,这已经超越了现有的基准测试的范围。
研究者将这些参数化模型与 6 个现实模型结合起来,作为广泛模型范围内的独特点,以提供对硬件平台的全面基准测试。表 1 总结了本文中描述的十 14 个观察结果和见解,这些观察和见解可以为未来的特定领域架构、系统和软件设计提供启发信息。
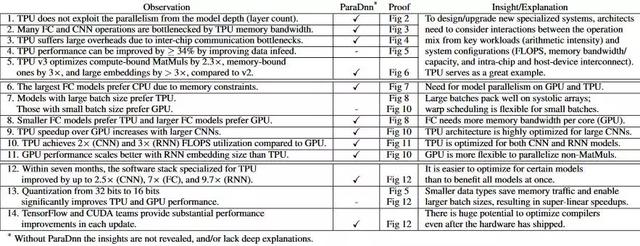
表 1:本文部分分组的主要观察和见解总结
研究者特意标记了通过 ParaDnn 得到的见解。他们从论文第 4 部分开始对 TPU v2 和 v3 的架构进行深入探讨,揭示了算力中的架构瓶颈、内存带宽、多片负载以及设备-主机平衡(第 1 到 5 个观察)。论文第五部分提供了 TPU 和 GPU 性能的全面比较,突出了这两个平台的重要区别(第 6 到第 11 个观察)。最后的 3 个观察在论文第六部分有详细描述,探讨了专用软件堆栈和量化数据类型带来的性能改进。
明确本研究的局限性非常重要。这篇论文着重研究了目前的架构和系统设计中可以优化的可能性,因为它们为未来的设计提供了宝贵的经验。优化的细节不属于本文的研究范围。例如,本文的分析只聚焦于训练而不是推理。作者没有研究多 GPU 平台或 256 节点 TPU 系统的性能,二者可能会导致不同的结论。
深度学习基准测试
深度学习(DL)最近的成功驱动了关于基准测试组件的研究。现有的组件主要有两种类型:一是像 MLPerf,、Fathom、BenchNN、以及 BenchIP 这种实际的基准测试;二是 DeepBench、BenchIP 这类微基准测试,但是它们都有一定的局限。
这些组件仅包含今天已有的深度学习模型,随着深度学习模型的快速发展,这些模型可能会过时。而且,它们没有揭示深度学习模型属性和硬件平台性能之间的深刻见解,因为基准测试只是巨大的深度学习空间中的稀疏点而已。
ParaDnn 对这项研究现有的基准测试组件做出了补充,它具有以上这些方法的优点,目标是提供「端到端」的、能够涵盖现有以及未来应用的模型,并且将模型参数化,以探索一个更大的深度神经网络属性的设计空间。
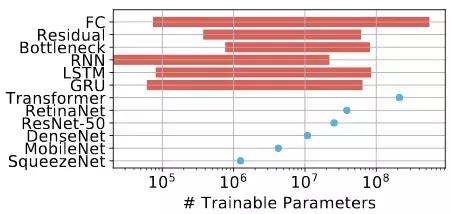
图 1:这篇文章中所有负载的可训练参数的数量。ParaDnn 中的模型参数范围在 1 万到接近十亿之间,如图所示,它要比实际模型的参数范围更大,如图中的点所示。
硬件平台
作者对硬件平台的选择反映了在论文提交时,云平台上广泛可用的最新配置。模型的详细指标在表 3 中。
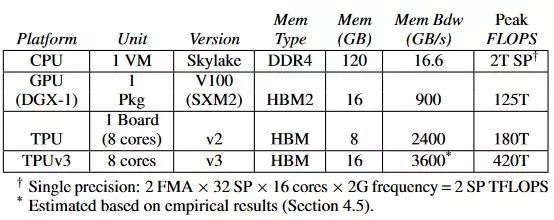
表 3:作为研究对象的硬件平台
实验图表
图 2(a)–(c) 表明,这三种方法的 FLOPS 利用率是随着 batch size 的增大而增大的。除此之外,全连接网络的 FLOPS 利用率随着每层节点数的增加而增大(图 2(a));卷积神经网络的 FLOPS 利用率随着滤波器的增加而增大,循环神经网络的 FLOPS 利用率随着嵌入尺寸的增大而增大。图 2(a)–(c) 中的 x 轴和 y 轴是图 2(d)–(f) 中具有最大绝对值的超参数。
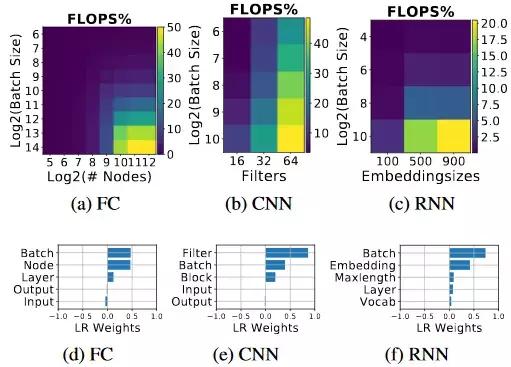
图 2:FLOPS 的利用率及其与超参数的相关性。(a)–(c) 表示参数化模型的 FLOPS 利用率。(d)–(f) 使用线性回归权重量化了模型超参数对 FLOPS 利用率的影响。
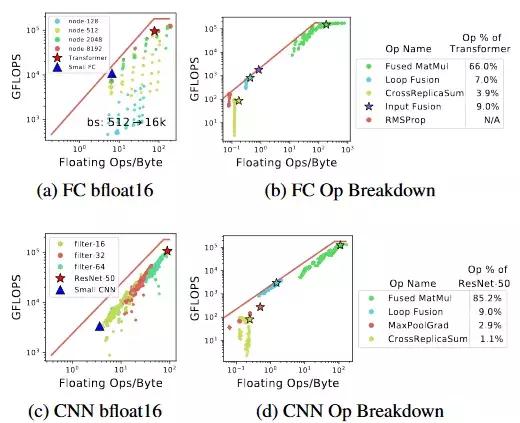
图 3:全连接网络和卷积神经网络在 TPU 上的 Roofline。矩阵相乘(MatMul)运算的负载是计算密集型的。即使是 Transformer 和 ResNet-50 这样的计算密集型模型也具有 10% 以上的内存限制运算。(a) 和 (c) 展示了参数化模型和实际模型的 roofline。(b) 和 (d) 展示了运算的分解。
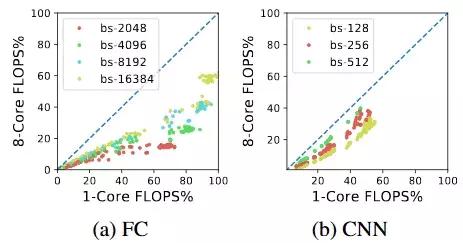
图 4:多片系统中的通信开销是不能忽略的,但是它会随着 batch size 的增大而减小。
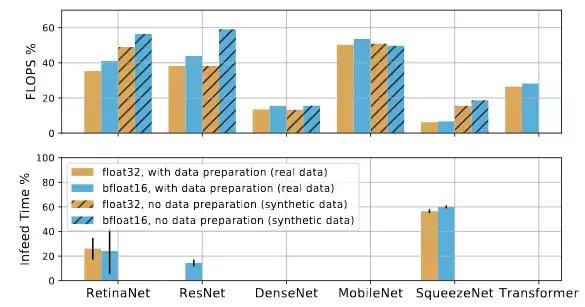
图 5:FLOPS 利用率(顶部)和使用 float32 和 bfloat16 的实际模型在具有以及没有数据准备情况下的喂料时间(设备等待数据的时间)(底部)。具有较大喂料时间百分比的模型(例如 RetinaNet 和 SqueezeNet)会受到数据喂入的限制。
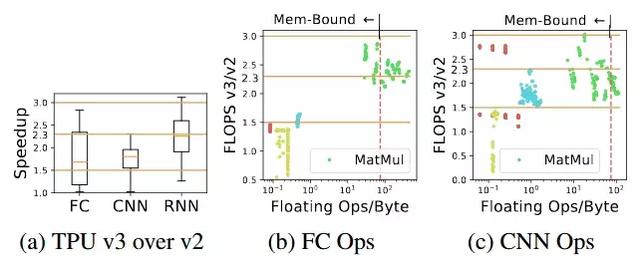
图 6:(a) 是 TPU v3 在运行端到端模型时与 v2 相比的加速比。(b) 和 (c) 是全连接和卷积神经网络的加速比。TPU v3 更大的内存支持两倍的 batch size,所以如果它们具有更大的 batch size,内存受限的运算会具获得三倍加速,如果没有更大的 batch size,则是 1.5 倍的加速。在 v3 上计算受限的运算拥有 2.3 倍的加速。红色的线 (75 Ops/Byte) 是 TPU v2 的 roofline 的拐点。
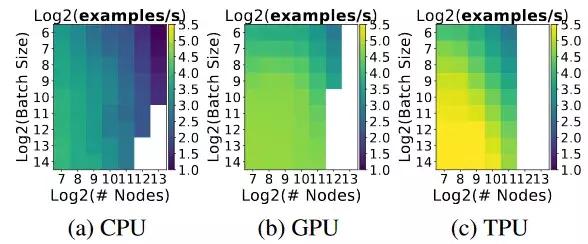
图 7:具有固定层(64)的全连接模型的 Examples/second(样本/秒)。Examples/second 随着节点的增多而减小,随着 batch size 的增大而增大。白色方块表示模型遇到了内存不足的问题。CPU 平台运行最大的模型,因为它具有最大的内存。
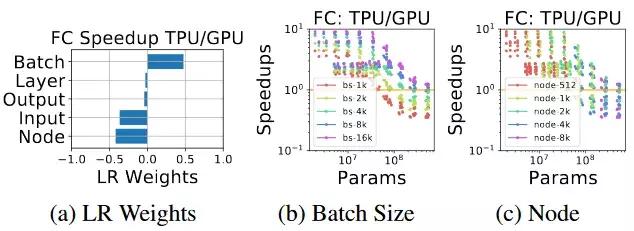
图 8:具有大 batch size 的小型全连接模型更偏好 TPU,具有小 batch size 的大型模型更加偏好 GPU,这意味着收缩阵列对大型矩阵更好,在 GPU 上对小型矩阵做变换更加灵活。
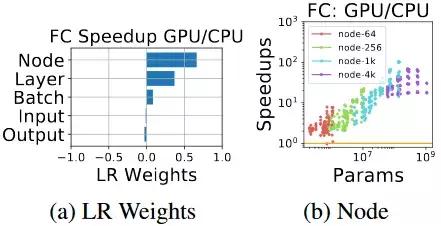
图 9:相比于 CPU,具有大 batch size 的大型全连接模型更适合 GPU,因为 CPU 的架构能够更好地利用额外的并行。
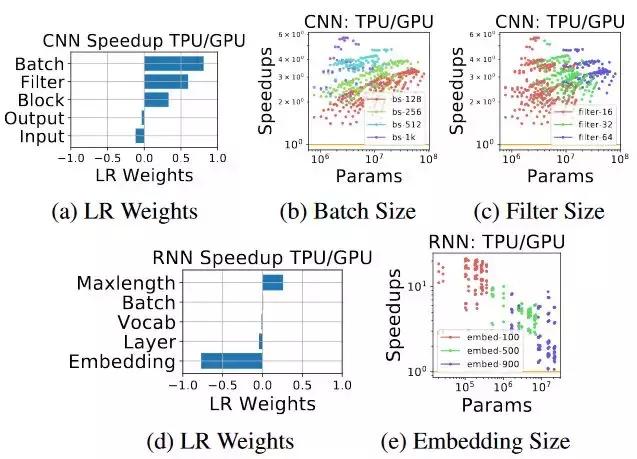
图 10:(a)–(c):对大型卷积神经网络而言,TPU 是比 GPU 更好的选择,这意味着 TPU 是对卷积神经网络做了高度优化的。(d)–(e):尽管 TPU 对 RNN 是更好的选择,但是对于嵌入向量的计算,它并不像 GPU 一样灵活。
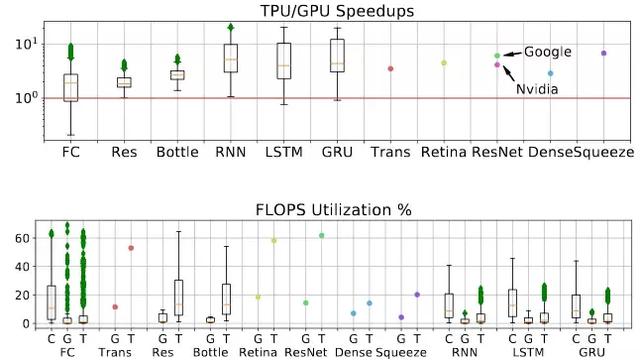
图 11:(顶部)在所有的负载上 TPU 相对 GPU 的加速比。需要注意的是,实际负载在 TPU 上会使用比 GPU 上更大的 batch size。ResNet-50 的英伟达 GPU 版本来自于文献 [9]。(底部)所有平台的 FLOPS 利用率对比。
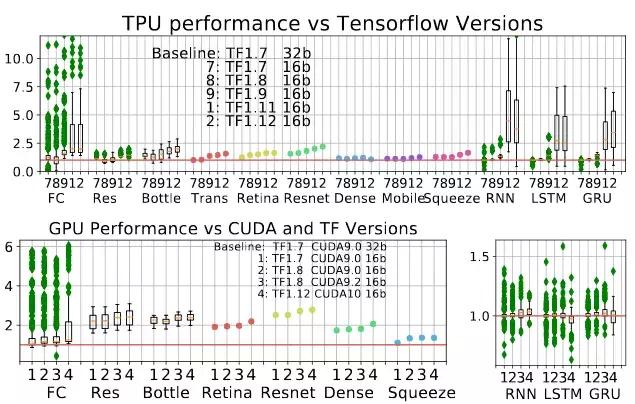
图 12:(a)TPU 性能随着 TensorFlow 版本更新发生的变化。所有的 ParaDnn 模型都有提升:Transformer, RetinaNet, 和 ResNet-50 提升稳定。(b)CUDA 和 TF 的不同版本上 GPU 的加速比。CUDA 9.2 对卷积神经网络的提升要比其他 ParaDnn 模型更多,对 ResNet-50 的提升要比其他实际模型更多。CUDA 10 没有提升 RNN 和 SqueezeNet。