TL;DR(too long don't read)
想要做到统一监控,不外乎做到下面这么几件事情。阿里云有日志服务,开源有 ELK。
1. 全链路调用唯一ID
2. 标准化日志
3. 打点方案
4. 监控大盘
5. 告警方案
前言
比如我们对于我们开出去的接口,所依赖调用别人的二方三方服务,究竟是怎样的表现,如果没有监控告警体系,那我们基本就是乱猜。比如,没有客诉,那么大概系统运行得还不错吧。这太瞎扯了,作为一个合格的工程师不允许这种情况出现。
投入一定的资源进行监控告警的建设什么好处呢?最大的好处就是,我们知道究竟有多少个服务被依赖,依赖了多少三方服务,QPS 是多少,接口平均 RT 多长,成功率是多少,失败的各个错误码分布是怎样的,一旦超过阈值能否比较及时触达到开发、运营人员。
有了监控,我们随时都可以对我们的系统有一个比较全面的了解,以及有一个比较全面的把控。有了告警,遇到问题我们可以第一时间感知,也可以第一时间介入。这些事情我们需要去解,各个公司各个平台的技术实力和经济实力都不同,所以解决方案也差别比较大。这些可能都是我们开发人员需要花时间额外去做的,无论是一次性的营销方案,还是长期运行的系统,都需要准备监控告警方案。用钱换时间,以及用时间换钱,这就是我们需要权衡的东西。当然,准备方案基本都是一致的,在这里我先只聊接口层面的监控。其他的关于数据库、JVM、消息队列、分布式缓存、tomcat 线程、主机CPU磁盘网络等,均不在此次讨论范围,这些需要更高层面的聚合服务来实现监控,监控逻辑几乎都是一致的。
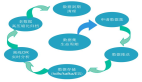
监控告警五部曲
想要做到统一监控,不外乎做到下面这么几件事情,但是每一件事都很难很重要。
1. 全链路调用唯一ID
2. 标准化日志
3. 打点方案
4. 监控大盘
5. 告警方案
1. 全链路调用唯一ID
全链路调用使用唯一ID,这是一个比较有价值的事情,可以用来判断某个调用链的调用过程是怎样的,能够在排查问题的追溯过程确保追溯流程的准确性。比如我们有5个系统,如果我们没有了这个唯一ID,在跨越五个系统的时候我们必然只能靠时间、订单、人 等业务维度来确定调用链路。只有两个字,低效。
正确的解决方式,就是在开始调用的时候生成一个几乎全局唯一的ID,然后在调用的过程中不断地传递给下游和分支,然后让下游再链式地传递给下游。
比如在 Java 中的处理方案。所有的接口入参都增加一个 traceId,然后放到 ThreadLocal 中,方便在任何地方进行打点。
2. 标准化日志
如果需要最终进行统一化分析,那么就要求我们在打日志的过程中,进行标准化统一化,大家全局的日志格式都一致,那么我们最终分析的时候也会比较简单。一个比较可行的标准化日志方案是长这样的。

3. 打点方案
标准化返回值
其中最核心的就是 ,具体可以参照下 大蕉蕉的三道 Java 私房菜 No.131 中的 ResultExecutor + ResultDTO 组合,核心就是标准化所有的出参,以便可以标准化进行 AOP 打印日志,核心值就是 succ 和 code。经过了标准化返回值之后,我们就可以针对返回值进行打点了,这就到了第二步。
AOP 切面
我们会使用切面的方式来进行日志打点,比如提供的服务接口调用前后,调用数据库的调用前后,调用公共缓存服务前后,调用消息中间件前后。如果是 Java 的话,建议使用 AspectJAroundAdvice,这样可以增加统计 rt (响应时间)。
日志文件规划
可以标准化成 rpc_access.log(内部服务)、http_access.log(http 类型服务,带登录态)、proxy_access.log(调用外部服务的代理)、db_access.log(db 类型日志)。这样分类有两个好处,第一个是在排查问题的时候可以有针对性地缩小排查范围,第二个是在最终日志聚合的时候可以有的放矢。
当然,打这么多日志,我们肯定会考虑,真的不会影响服务性能吗?这就到了第三步。
滚动日志&异步appender
我们每天的访问量都是海量的,如果任由日志不断打的话,机器无论有多大基本都是不够用的,所以我们可以使用滚动日志的方式,比如 Java 下是 slf4j2。至于打日志,其实是一个磁盘 IO 的过程,这个过程如果量比较大的话,是有可能会影响服务的 rt 的,如果我们做成异步的appender,那么我们打点的过程对于原来的服务来说影响几乎可以忽略不计。那么日志打完就放到本地吗?明显是不合适的,肯定需要有一个归档的地方,按照某种策略进行归档。
归档数据库
这类归档数据库的写入其实有两个方案,第一个是使用 SDK 的方式进行写入。第二个是安装一个 agent 进行定时文件扫描,然后上传到归档数据库。可选择的方案大概有 ElasticSearch、SLOG、时序数据库、HBase、Graphite 等 NOSQL 的数据库。在这里强烈建议不要放到关系型数据库里,毕竟日志的量实在是太大了,无论放到哪个关系型数据库里,最终的结果都只会因为基础数据量太大,而导致几乎任何查询都进行不下去。
4. 监控大盘
开源方案
Graphite
Graphite does two things:
- Store numeric time-series data
- Render graphs of this data on demand
Graphite 就做了两件事,第一件事就是存储了时序数字类型的数据,第二件事就是把这些数据用图表的方式展示出来,至于安装和使用的过程比较复杂,请自行进行阅读。 https://www.infoq.cn/article/graphite-intro/
ELK(ElasticSearch + Logstach + Kibana)
这里的监控大盘主要使用了 Kibana 的自定义视图能力,要求就是数据必须写入到 ElasticSearch 里边。
高成本方案
阿里云 SLOG 日志服务
SLOG 是阿里云提供的一个日志服务,只要根据 key-value 的形式将数据写入到 SLOG 上,就可以自定义配置一些监控大盘,一定量以内是免费的。所以如果量不大,技术实力又不强,可以尝试一下这个方案。当然如果有一定的资金,SLOG 本身其实并不算太贵,而且可靠性和性能都非常强。除了官方提供的方式外,也可以对接到一个自定义的日志平台或者监控平台,通过 API 的形式进行监控数据查询,并进行展示。
高技术方案
Flink 实时计算
这里使用的主要 Flink 的基于窗口的聚合能力,能够将大批量的流式数据进行聚合,然后再将聚合的结果输出到某个库,提供一定的大盘能力,比如双十一的 GMV 计算大屏。优点就是可定制型非常非常强以及性能可以得到很好的调优和定制,缺点就是技术实力可能要求比较高,而且对每一个需要监控的点基本都需要进行代码开发。
5. 告警方案
高成本方案
阿里云 SLOG 日志服务本身也提供了告警功能,详细可以进入官网查看。
高技术方案
这里主要是对于自控形式比较强的团队。可以自行开发告警服务,主要技术手段就是,按照某种聚合方式,定时从时序数据库里查询,然后进行告警的触发。当然如果技术实力够的话,也可以集合一定的规则引擎以及配置的能力,对于开发人员进行 devOps 的支持,也就是告警的自定义。
触达方式
有了告警之后,我们肯定希望能够准确快速触达到对应的人员,一般来说我们的触达方式可以有 钉钉群机器人、企业微信群机器人、邮件、电话、短信。这几个方式都算比较便捷实现,我们要考虑的点是,什么样的告警需要怎样的频率进行触达,比如告警 1 分钟用群机器人,重要的用短信,告警持续 5 分钟还未关闭则通过自动化语音播报的形式进行电话触达。
总结
为什么很多的开发人员在上线后会心慌,因为这部分的工程师对于系统的表现毫无概念,毫无可以着手的,毫无把控能力。这就是我们需要监控告警的作用,监控是让我们拥有对系统一定的把控能力,告警是让我们不需要时时刻刻盯着所谓的大盘。上面所说的这些,都是我们需要在开发完成或者开发初期就需要考虑到的,是需要纳入到项目工作量里面的(当然如果项目经理不管这个,你需要对他进行宣告。又或者给自己留一定的 buffer 进行监控告警的建设)。我们需要在哪里进行打点,打怎样的点,怎么进行监控,什么样的内容需要告警,作为一个合格的工程师,这是我们效率方面非常非常非常值得的投入。
没有监控的系统就是半废,你,敢上线吗?