继续答星球水友提问,30WQPS的点赞计数业务,如何设计?
可以看到,这个业务的特点是:
- 吞吐量超高;
- 能够接受一定数据不一致;
画外音:计数有微小不准确,不是大问题。
先用最朴素的思想,只考虑点赞计数,可以怎么做?有几点是最容易想到的:
- 肯定不能用数据库抗实时读写流量;
- redis天然支持固化,可以用高可用redis集群来做固化存储;
- 也可以用MySQL来做固化存储,redis做缓存,读写操作都落缓存,异步线程定期刷DB;
- 架一层计数服务,将计数与业务逻辑解耦;
此时MySQL核心数据结构是:
- t_count(msg_id, praise_count)
此时redis的KV设计也不难:
- key:msg_id
- value:praise_count

似乎很容易就搞定了:
- 服务可以水平扩展;
- 数据量增加时,数据库可以水平扩展;
- 读写量增加时,缓存也可以水平扩展;
计数系统的难点,还在于业务扩展性问题,以及效率问题。
以微博为例:
- 用户微博首页,有多条消息list
,这是一种扩展; 同一条消息msg_id,不止有点赞计数,还有阅读计数,转发计数,评论计数,这也是一种扩展;
- // (1)获取首页所有消息msg_id
- list<msg_id> = getHomePageMsg(uid);
- // (2)对于首页的所有消息要拉取多个计数
- for( msg_id in list<msg_id>){
- //(3.1)获取阅读计数
- getReadCount(msg_id);
- //(3.2)获取转发计数
- getForwordCount(msg_id);
- //(3.3)获取评论计数
- getCommentCount(msg_id);
- //(3.4)获取赞计数
- getPraiseCount(msg_id);
- }
由于同一个msg_id多了几种业务计数,redis的key需要带上业务flag,升级为:
- msg_id:read
- msg_id:forword
- msg_id:comment
- msg_id:praise
用来区分共一个msg_id的四种不同业务计数,redis不能支持key的模糊操作,必须访问四次reids。
假设首页有100条消息,这个方案总结为:
- for循环每一条消息,100条消息100次;
- 每条消息4次RPC获取计数接口调用;
- 每次调用服务要访问reids,拼装key获取count;
画外音:这种方案的扩展性和效率是非常低的。
那如何进行优化呢?
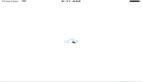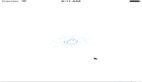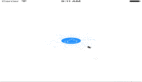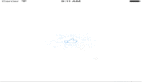
首先看下数据库层面元数据扩展,常见的扩展方式是,增加列,记录更多的业务计数。
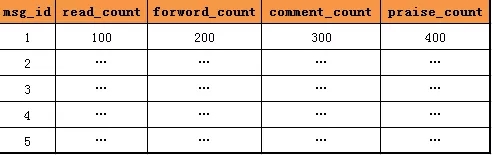
如上图所示,由一列点赞计数,扩充为四列阅读、转发、评论、点赞计数。
增加列这种业务计数扩展方式的缺点是:每次要扩充业务计数时,总是需要修改表结构,增加列,很烦。
有没有不需要变更表结构的扩展方式呢?
行扩展是一种扩展性更好的方式。

表结构固化为:
- t_count(msg_id, count_key, count_value)
当要扩充业务计数时,增加一行就行,不需要修改表结构。
画外音:很多配置业务,会使用这种方案,方便增加配置。
增加行这种业务计数扩展方式的缺点是:表数据行数会增加,但这不是主要矛盾,数据库水平扩展能很轻松解决数据量大的问题。
接下来看下redis批量获取计数的优化方案。
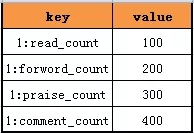
原始方案,通过拼装key来区分同一个msg_id的不同业务计数。
可以升级为,同一个value来存储多个计数。

如上图所示,同一个msg_id的四个计数,存储在一个value里,从而避免多次redis访问。
画外音:通过value来扩展,是不是很巧妙?
总结
计数业务,在数据量大,并发量大的时候,要考虑的一些技术点:
- 用缓存抗读写;
- 服务化,计数系统与业务系统解耦;
- 水平切分扩展吞吐量、数据量、读写量;
- 要考虑扩展性,数据库层面常见的优化有:列扩展,行扩展两种方式;
- 要考虑批量操作,缓存层面常见的优化有:一个value存储多个业务计数;
计数系统优化先聊到这里,希望大家有收获。
【本文为51CTO专栏作者“58沈剑”原创稿件,转载请联系原作者】