














继续答星球水友提问:盘口数据频繁变化,如何做缓存与推送,如何降低数据库压力?
并没有做过相关的业务,结合自己的架构经验,说说自己的思路和想法,希望对大家有启示。
一、业务抽象
- 有很多客户端关注盘口,假设百万级别;
- 数据量不一定很大,上市交易的股票个数,假设万级别;
- 写的量比较大,每秒钟有很多交易发生,假设每秒百级别;
- 计算比较复杂,有求和/分组/排序等操作;
二、潜在技术折衷
1. 客户端与服务端连接如何选型?
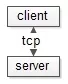
首先,盘口客户端与服务器建立TCP长连接,而不是每次请求都建立与销毁短连接,能极大提升性能,降低服务器压力。
2. 业务的实时性如何满足?
盘口业务,对数据实时性的要求较高,服务端可以通过TCP长连接推送,保证消息的实时性。
由于推送量级巨大,可以独立推送集群,专门实施推送。推送集群独立化之后,增加推送服务器数量,就可以线性提升推送能力。
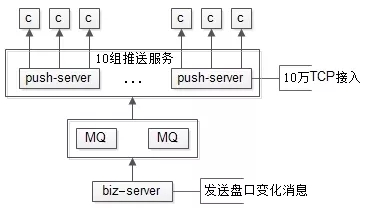
如上图所示,假设有100W用户接收实时推送:
- 搭建专门的推送集群,维护与客户端的tcp长连接,实时推送
- 每台推送服务维护10W长连接,10台推送服务即可服务100W用户
- 推送集群与业务集群之间,通过MQ解耦,推送集群只单纯的推送消息,无任何业务逻辑计算,推送消息的内容,都是业务集群计算好的
3. 推送服务最大的瓶颈是,如何将一条消息,最快的推送给与之连接的10W个客户端?
- 如果消息量不大,例如几秒钟一个消息,可以开多线程,例如100个线程,并发推送
画外音:对应水友提到的,如果量不大,可以成交一笔推送一笔。
- 如果消息量过大,例如一秒钟几百个消息,可以将消息暂存一秒,批量推送
画外音:对应水友提到的,如果消息量巨大,批量推送是很好的方法。
4. 数据量,写入量,扩展性如何满足?
股票个数较少,数据量不是瓶颈。
流水数据写入量,每秒百级别,甚至千级别,数据库写性能也不是瓶颈,理论上一个库可以抗住。
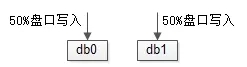
假如每秒写入量达到万级别,可以在数据库层面实施水平切分,将不同股票的流水拆到不同水平切分的库里去,就能线性增加数据库的写入量。
画外音:水平拆分后,同一个股票,数据在同一个库里,不同股票,可能在不同的库里,理论上不会有跨库查询的需求。
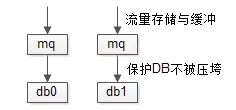
如果每秒写入量达到十万,百万级别,还可以加入MQ缓冲请求,削峰填谷,保护数据库。
如论如何,根据本业务的数据量与写入量,单库应该是没有问题的。
5. 复杂的业务逻辑操作,如何满足?
本业务的写入量不大,但读取量很大,肯定不能每个读取请求都sum/group by/order by,这样数据库肯定扛不住。
水友已经想到了,可以用缓存来降低数据库的压力,但担心“随着时间的推移,这个偏差势必会慢慢放大”。
关于缓存的一致性的放大,可以这么搞:
- 做一个异步的线程,每秒钟访问一次数据库,将复杂的业务逻辑计算出来,放入高可用缓存
- 所有的读请求不再耦合业务逻辑计算,都直接从高可用缓存读结果
如此一来,复杂业务逻辑的计算,每秒钟只会有一次。
带来的问题是,一秒内可能有很多流水写入数据库,但不会实时的反应到缓存里,用户最差情况下,会读到一秒前的盘口数据。
无论如何,这是一个性能与一致性的设计折衷。
上面的所有方案,都是基于在线客户量级巨大,推送消息巨大的前提下,采用推送方案。很多时候,工程师都会妄加猜测,把问题想得很复杂,把方案搞得很复杂。
如果在线用户量很小,用户能够接受的盘口时延较长(例如5s),完全可以采用轮询拉取方案:
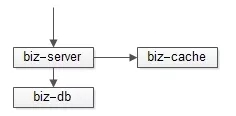
- 取消整个推送集群与MQ集群;
- 盘口数据,异步线程每1s写入高可用缓存一次;
- 客户端每5s轮询拉取最新的盘口数据,都只从缓存中拉取;
搞定!
反正,肯定不能每个读请求都sum/group by/order by扫库计算,这个是最需要优化的。
三、总结
- 长连接比短连接性能好很多倍
- 推送量巨大时,推送集群需要与业务集群解耦
- 推送量巨大时,并发推送与批量推送是一个常见的优化手段
- 写入量巨大时,水平切分能够扩容,MQ缓冲可以保护数据库
- 业务复杂,读取量巨大时,加入缓存,定时计算,能够极大降低数据库压力
思路比结论重要,希望大家有收获。
【本文为51CTO专栏作者“58沈剑”原创稿件,转载请联系原作者】





















