分布式系统为保证数据高可用,需要为数据保存多个副本,随之而来的问题是如何在不同副本间同步数据?不同的同步机制有不同的效果和代价,本文尝试对常见分布式组件的同步机制做一个小结。
常见机制
有一些常用的同步机制,对它们也有许多评价的维度,先看看大神的 经典总结 :
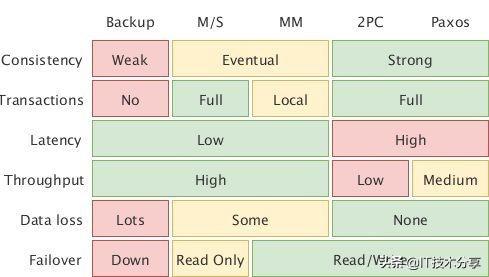
上图给出了常用的同步方式(个人理解,请批评指正):
- Backup,即定期备份,对现有的系统的性能基本没有影响,但节点宕机时只能勉强恢复
- Master-Slave,主从复制,异步复制每个指令,可以看作是粒度更细的定期备份
- Multi-Muster,多主,也称“主主”,MS 的加强版,可以在多个节点上写,事后再想办法同步
- 2 Phase-Commit,二阶段提交,同步先确保通知到所有节点再写入,性能容易卡在“主”节点上
- Paxos,类似 2PC,同一时刻有多个节点可以写入,也只需要通知到大多数节点,有更高的吞吐
同步方式分两类,异步的性能好但可能有数据丢失,同步的能保证不丢数据但性能较差。同种方式的算法也能有所提升(如 Paxos 对于 2PC),但实现的难度又很高。实现上只能在这几点上进行权衡。
考虑同步算法时,需要考虑节点宕机、网络阻断等故障情形。下面,我们来看看一些分布式组件的数据同步机制,主要考虑数据写入请求如何被处理,期间可能会涉及如何读数据。
Redis
Redis 3.0 开始引入 Redis Cluster 支持集群模式,个人认为它的设计很漂亮,大家可以看看 官方文档 。
- 采用的是主从复制,异步同步消息,极端情况会丢数据
- 只能从主节点读写数据,从节点只会拒绝并让客户端重定向,不会转发请求
- 如果主节点宕机一段时间,从节点中会自动选主
- 如果期间有数据不一致,以最新选出的主节点的数据为准。
一些设计细节:
- HASH_SLOT = CRC16(Key) mod 16384
- MEET
- WAIT
Kafka
Kafka 的分片粒度是 Partition,每个 Partition 可以有多个副本。副本同步设计参考 官方文档
- 类似于 2PC,节点分主从,同步更新消息,除非节点全挂,否则不会丢消息
- 消息发到主节点,主节点写入后等待“所有”从节点拉取该消息,之后通知客户端写入完成
- “所有”节点指的是 In-Sync Replica(ISR),响应太慢或宕机的从节点会被踢除
- 主节点宕机后,从节点选举成为新的主节点,继续提供服务
- 主节点宕机时正在提交的修改没有做保证(消息可能没有 ACK 却提交了)
一些设计细节:
- 当前消费者只能从主节点读取数据,未来可能会改变
- 主从的粒度是 partition,每个 broker 对于某些 Partition 而言是主节点,对于另一些而言是从节点
- Partition 创建时,Kafka 会尽量让 preferred replica 均匀分布在各个 broker
- 选主由一个 controller 跟 zookeeper 交互后“内定”,再通过 RPC 通知具体的主节点 ,此举能防止 partition 过多,同时选主导致 zk 过载。
ElasticSearch
ElasticSearch 对数据的存储需求和 Kafka 很类似,设计也很类似,详细可见 官方文档 。
ES 中有 master node 的概念,它实际的作用是对集群状态进行管理,跟数据的请求无关。为了上下文一致性,我们称它为管理节点,而称 primary shard 为“主节点”, 称 replica shard 为从节点。ES 的设计:
- 类似于 2PC,节点分主从,同步更新消息,除非节点全挂,否则不会丢消息
- 消息发到主节点,主节点写入成功后并行发给从节点,等到从节点全部写入成功,通知客户端写入完成
- 管理节点会维护每个分片需要写入的从节点列表,称为 in-sync copies
- 主节点宕机后,从节点选举成为新的主节点,继续提供服务
- 提交阶段从节点不可用的话,主节点会要求管理节点将从节点从 in-sync copies 中移除
一些设计细节:
- 写入只能通过只主节点进行,读取可以从任意从节点进行
- 每个节点均可提供服务,它们会转发请求到数据分片所在的节点,但建议循环访问各个节点以平衡负载
- 数据做分片: shard = hash(routing) % number_of_primary_shards
- primary shard 的数量是需要在创建 index 的时候就确定好的
- 主从的粒度是 shard,每个节点对于某些 shard 而言是主节点,对于另一些而言是从节点
- 选主算法使用了 ES 自己的 Zen Discovery
Hadoop
Hadoop 使用的是链式复制,参考 Replication Pipelining
- 数据的多个复本写入多个 datanode,只要有一个存活数据就不会丢失
- 数据拆分成多个 block,每个 block 由 namenode 决定数据写入哪几个 datanode
- 链式复制要求数据发往一个节点,该节点发往下一节点,待下个节点返回及本地写入成 功后返回,以此类推形成一条写入链。
- 写入过程中的宕机节点会被移除 pineline,不一致的数据之后由 namenode 处理。
实现细节:
- 实现中优化了链式复制:block 拆分成多个 packet,节点 1 收到 packet, 写入本地 的同时发往节点 2,等待节点 2 完成及本地完成后返回 ACK。节点 2 以此类推将 packet 写入本地及发往节点 3……
TiKV
TiKV 使用的是 Raft 协议来实现写入数据时的一致性。参考 三篇文章了解 TiDB 技术内幕——说存储
- 使用 Raft,写入时需要半数以上的节点写入成功才返回,宕机节点不超过半数则数据不丢失。
- TiKV 将数据的 key 按 range 分成 region,写入时以 region 为粒度进行同步。
- 写入和读取都通过 leader 进行。每个 region 形成自己的 raft group,有自己的 leader。
Zookeeper
Zookeeper 使用的是 Zookeeper 自己的 Zab 算法(Paxos 的变种?),参考 Zookeeper Internals
- 数据只可以通过主节点写入(请求会被转发到主节点进行),可以通过任意节点读取
- 主节点写入数据后会广播给所有节点,超过半数节点写入后返回客户端
- Zookeeper 不保证数据读取为最新,但通过“单一视图”保证读取的数据版本不“回退”
小结
如果系统对性能要求高以至于能容忍数据的丢失(Redis),则显然异步的同步方式是一种好的选择。
而当系统要保证不丢数据,则几乎只能使用同步复制的机制,看到 Kafka 和 Elasticsearch 不约而同地使用了 PacificA 算法(个人认为可以看成是 2PC 的变种),当然这种方法的响应制约于最慢的副本,因此 Kafka 和 Elasticsearch 都有相关的机制将慢的副本移除。
当然看起来 Paxos, Raft, Zab 等新的算法比起 2PC 还是要好的:一致性保证更强,只要半数节点写入成功就可以返回,Paxos 还支持多点写入。只不过这些算法也很难正确实现和优化。